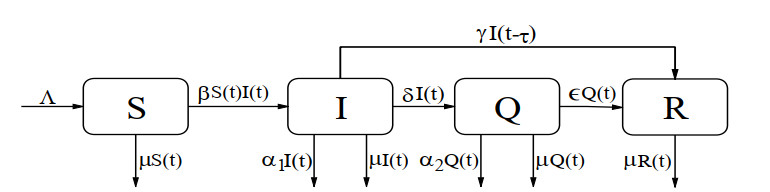
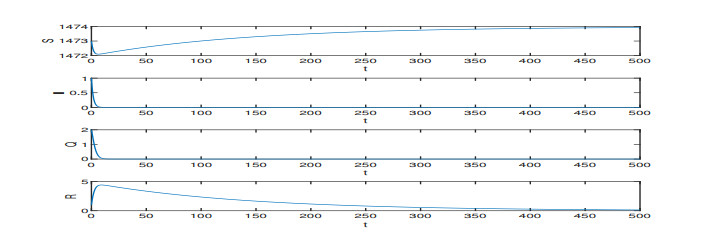
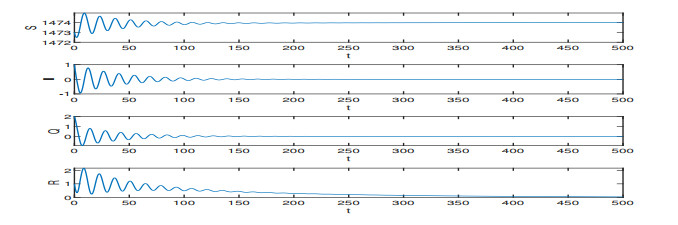
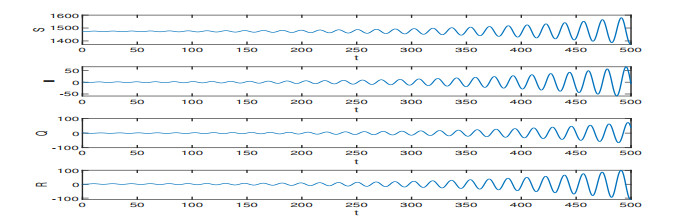
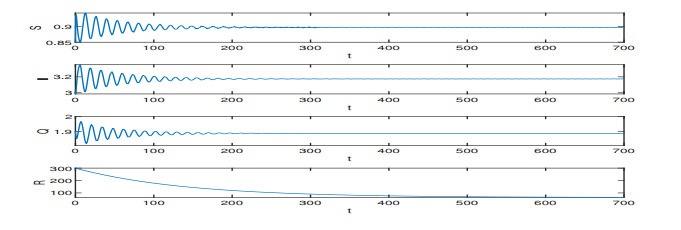
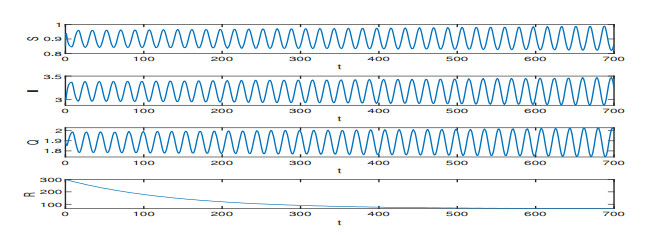
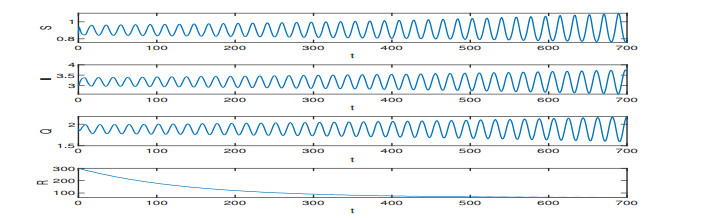
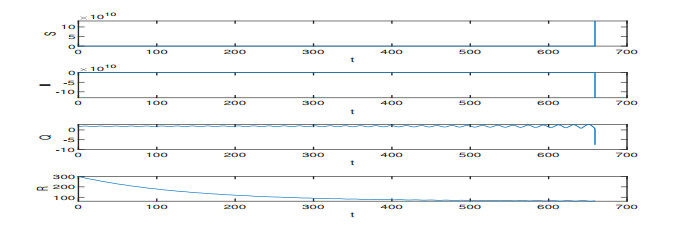
On the basis of the SIQR epidemic model, we consider the impact of treatment time on the epidemic situation, and we present a differential equation model with time-delay according to the characteristics of COVID-19. Firstly, we analyze the existence and stability of the equilibria in the modified COVID-19 epidemic model. Secondly, we analyze the existence of Hopf bifurcation, and derive the normal form of Hopf bifurcation by using the multiple time scales method. Then, we determine the direction of Hopf bifurcation and the stability of bifurcating periodic solutions. Finally, we carry out numerical simulations to verify the correctness of theoretical analysis with actual parameters, and show conclusions associated with the critical treatment time and the effect on epidemic for treatment time.
Citation: Hongfan Lu, Yuting Ding, Silin Gong, Shishi Wang. Mathematical modeling and dynamic analysis of SIQR model with delay for pandemic COVID-19[J]. Mathematical Biosciences and Engineering, 2021, 18(4): 3197-3214. doi: 10.3934/mbe.2021159
On the basis of the SIQR epidemic model, we consider the impact of treatment time on the epidemic situation, and we present a differential equation model with time-delay according to the characteristics of COVID-19. Firstly, we analyze the existence and stability of the equilibria in the modified COVID-19 epidemic model. Secondly, we analyze the existence of Hopf bifurcation, and derive the normal form of Hopf bifurcation by using the multiple time scales method. Then, we determine the direction of Hopf bifurcation and the stability of bifurcating periodic solutions. Finally, we carry out numerical simulations to verify the correctness of theoretical analysis with actual parameters, and show conclusions associated with the critical treatment time and the effect on epidemic for treatment time.

| [1] |
Z. Liao, P. Lan, Z. Liao, Y. Zhang, S. Liu, TW-SIR: Time-window based SIR for COVID-19 forecasts, Sci. Rep., 10 (2020), 22454. doi: 10.1038/s41598-020-80007-8

|
| [2] | C. Yang, J. Wang, Modeling the transmission of COVID-19 in the US-A case study, Infect. Dis. Model., 6 (2021), 195-211. |
| [3] | G. Xu, F. Qi, H. Li, Q. Yang, H. Wang, X. Wang, et al., The differential immune responses to COVID-19 in peripheral and lung revealed by single-cell RNA sequencing, Cell Discov., 6 (2020), 1-14. |
| [4] |
Z. Zhang, A novel covid-19 mathematical model with fractional derivatives: Singular and nonsingular kernels, Chaos Soliton. Fract., 139 (2020), 110060. doi: 10.1016/j.chaos.2020.110060
|
| [5] | A. S. Bhadauria, R. Pathak, M. Chaudhary, A SIQ mathematical model on COVID-19 investigating the lockdown effect, Infect. Dis. Model., 6 (2021), 244-257. |
| [6] |
Y. Li, Q. Zhang, The balanced implicit method of preserving positivity for the stochastic SIQS epidemic model, Physica A, 538 (2020), 122972. doi: 10.1016/j.physa.2019.122972
|
| [7] |
M. Higazy, Novel fractional order SIDARTHE mathematical model of COVID-19 pandemic, Chaos Soliton. Fract., 138 (2020), 110007. doi: 10.1016/j.chaos.2020.110007
|
| [8] |
A. M. Ramos, M. R. Ferrández, M. Vela-Pérez, A. B. Kubik, B. Ivorra, A simple but complex enough $\theta$-SIR type model to be used with COVID-19 real data. Application to the case of Italy, Physica D, 421 (2021), 132839. doi: 10.1016/j.physd.2020.132839
|
| [9] |
K. S. Nisar, S. Ahmad, A. Ullah, K. Shah, H. Alrabaiah, M. Arfan, Mathematical analysis of SIRD model of COVID-19 with Caputo fractional derivative based on real data, Results Phys., 21 (2021), 103772. doi: 10.1016/j.rinp.2020.103772
|
| [10] |
C. M. Batistela, D. P. F. Correa, Á. M. Bueno, J. R. C. Piqueira, SIRSi compartmental model for COVID-19 pandemic with immunity loss, Chaos Soliton. Fract., 142 (2021), 110388. doi: 10.1016/j.chaos.2020.110388
|
| [11] |
P. E. Paré, C. L. Beck, T. Başar, Modeling, estimation, and analysis of epidemics over networks: An overview, Annu. Rev. Control, 50 (2020), 345-360. doi: 10.1016/j.arcontrol.2020.09.003
|
| [12] |
C.-C. Zhu, J. Zhu, Dynamic analysis of a delayed COVID-19 epidemic with home quarantine in temporal-spatial heterogeneous via global exponential attractor method, Chaos Soliton. Fract., 143 (2021), 110546. doi: 10.1016/j.chaos.2020.110546
|
| [13] |
S. Scheiner, N. Ukaj, C. Hellmich, Mathematical modeling of COVID-19 fatality trends: Death kinetics law versus infection-to-death delay rule, Chaos Soliton. Fract., 136 (2020), 109891. doi: 10.1016/j.chaos.2020.109891
|
| [14] |
H. Wei, Y. Jiang, X. Song, G. H. Su, S. Z. Qiu, Global attractivity and permanence of a SVEIR epidemic model with pulse vaccination and time delay, J. Comput. Appl. Math., 229 (2009), 302-312. doi: 10.1016/j.cam.2008.10.046
|
| [15] |
D. Mukherjee, Stability analysis of an S-I epidemic model with time delay, Math. Comput. Model., 24 (1996), 63-68. doi: 10.1016/0895-7177(96)00154-9
|
| [16] |
S. İğret Araz, Analysis of a Covid-19 model: Optimal control, stability and simulations, Alex. Eng. J., 60 (2021), 647-658. doi: 10.1016/j.aej.2020.09.058
|
| [17] |
S. Annas, Muh. Isbar Pratama, Muh. Rifandi, W. Sanusi, S. Side, Stability analysis and numerical simulation of SEIR model for pandemic COVID-19 spread in Indonesia, Chaos Soliton. Fract., 139 (2020), 110072. doi: 10.1016/j.chaos.2020.110072
|
| [18] |
A. E. S. Almocera, G. Quiroz, E. A. Hernandez-Vargas, Stability analysis in COVID-19 within-host model with immune response, Commun. Nonlinear Sci. Numer. Simul., 95 (2021), 105584. doi: 10.1016/j.cnsns.2020.105584
|
| [19] |
G. P. Samanta, Permanence and extinction of a nonautonomous HIV/AIDS epidemic model with distributed time delay, Nonlinear Anal.-Real World Appl., 12 (2011), 1163-1177. doi: 10.1016/j.nonrwa.2010.09.010
|
| [20] |
U. Avila-Ponce de León, Á. G. C. Pérez, E. Avila-Vales, An SEIARD epidemic model for COVID-19 in Mexico: Mathematical analysis and state-level forecast, Chaos Soliton. Fract., 140 (2020), 110165. doi: 10.1016/j.chaos.2020.110165
|
| [21] |
H. M. Youssef, N. A. Alghamdi, M. A. Ezzat, A. A. El-Bary, A. M. Shawky, A new dynamical modeling SEIR with global analysis applied to the real data of spreading COVID-19 in Saudi Arabia, Math. Biosci. Eng., 17 (2020), 7018-7044. doi: 10.3934/mbe.2020362
|
| [22] |
R. Carli, G. Cavone, N. Epicoco, P. Scarabaggio, M. Dotoli, Model predictive control to mitigate the COVID-19 outbreak in a multi-region scenario, Annu. Rev. Control, 50 (2020), 373-393. doi: 10.1016/j.arcontrol.2020.09.005
|
| [23] |
G. Giordano, F. Blanchini, R. Bruno, P. Colaneri, A. D. Filippo, A. D. Matteo, et al., Modelling the COVID-19 epidemic and implementation of population-wide interventions in Italy, Nature Med., 26 (2020), 855--860. doi: 10.1038/s41591-020-0883-7
|
| [24] |
T. Odagaki, Exact properties of SIQR model for COVID-19, Physica A, 564 (2021), 125564. doi: 10.1016/j.physa.2020.125564
|
| [25] |
F. Saldaña, H. Flores-Arguedas, J. A. Camacho-Guti\' errez, I. Barradas, Modeling the transmission dynamics and the impact of the control interventions for the COVID-19 epidemic outbreak, Math. Biosci. Eng., 17 (2020), 4165--4183. doi: 10.3934/mbe.2020231
|
| [26] | Q. Liu, D. Jiang, N. Shi, Threshold behavior in a stochastic SIQR epidemic model with standard incidence and regime switching, Appl. Math. Comput., 316 (2018), 310-325. |
| [27] |
M. Chen, M. Li, Y. Hao, Z. Liu, L. Hu, L. Wang, The introduction of population migration to SEIAR for COVID-19 epidemic modeling with an efficient intervention strategy, Inf. Fusion, 64 (2020), 252-258. doi: 10.1016/j.inffus.2020.08.002
|
| [28] | A. B. Gumel, E. A. Iboi, C. N. Ngonghala, E. H. Elbasha, A primer on using mathematics to understand COVID-19 dynamics: Modeling, analysis and simulations, Infect. Dis. Model., 6 (2021), 148-168. |
| [29] |
A. Khan, R. Zarin, G. Hussain, N. A. Ahmad, M. H. Mohd, A. Yusuf, Stability analysis and optimal control of covid-19 with convex incidence rate in Khyber Pakhtunkhawa (Pakistan), Results Phys., 20 (2021), 103703. doi: 10.1016/j.rinp.2020.103703
|


Figures(10) / Tables(1)

Hongfan Lu, Yuting Ding, Silin Gong, Shishi Wang. Mathematical modeling and dynamic analysis of SIQR model with delay for pandemic COVID-19[J]. Mathematical Biosciences and Engineering, 2021, 18(4): 3197-3214. doi: 10.3934/mbe.2021159







 DownLoad:
DownLoad: