Citation: Ting Mao, Lanting Yu, Yueyi Zhang, Li Zhou. Modified Mahalanobis-Taguchi System based on proper orthogonal decomposition for high-dimensional-small-sample-size data classification[J]. Mathematical Biosciences and Engineering, 2021, 18(1): 426-444. doi: 10.3934/mbe.2021023

| [1] | G. Taguchi, S. Chowdhury, Y. Wu, The Mahalanobis-Taguchi System, 2001. |
| [2] |
Z. P. Chang, Y. W. Li, N. Fatima., A theoretical survey on Mahalanobis-Taguchi System, Measurement, 136 (2019), 501–510. doi: 10.1016/j.measurement.2018.12.090

|
| [3] | N. Deepa, K. Ganesan, Mahalanobis Taguchi System based criteria selection tool for agriculture crops, 41 (2016), 1407–1414. |
| [4] |
B. Buenviaje, J. E. Bischoff, R. A. Roncace, C. J. Willy, Mahalanobis-Taguchi System to identify preindicators of delirium in the ICU, IEEE J. Biomed. Heal. Informatics, 20 (2016), 1205–1212. doi: 10.1109/JBHI.2015.2434949
|
| [5] | J. Wang, C. Duan, Structural health monitoring using Mahalanobis-Taguchi System, Proc. 2009 Int. Conf. Inf. Eng. Comput. Sci. ICIECS 2009, (2009). |
| [6] | A. K. Dwivedi, I. Mallawaarachchi, L. A. Alvarado, Analysis of small sample size studies using nonparametric bootstrap test with pooled resampling method, Stat. Med., 36 (2017), 2187–2205. |
| [7] |
H. F. Gong, Z. S. Chen, Q. X. Zhu, Y. L. He, A monte carlo and PSO based virtual sample generation method for enhancing the energy prediction and energy optimization on small data problem: An empirical study of petrochemical industries, Appl. Energy, 197 (2017), 405–415. doi: 10.1016/j.apenergy.2017.04.007
|
| [8] |
E. Etchells, M. Ho, K. G. Shojania, Value of small sample sizes in rapid-cycle quality improvement projects, BMJ Qual. Saf., 25 (2016), 202–206. doi: 10.1136/bmjqs-2015-005094
|
| [9] |
W. Jia, D. Zhao, L. Ding, An optimized RBF neural network algorithm based on partial least squares and genetic algorithm for classification of small sample, Appl. Soft Comput. J., 48 (2016), 373–384. doi: 10.1016/j.asoc.2016.07.037
|
| [10] | Abdul Lateh, A. K. Muda, Z. I. M. Yusof, N. A. Muda, M. S. Azmi, Handling a small dataset problem in prediction model by employ artificial data generation approach: A review, J. Phys. Conf. Ser., 892 (2017). |
| [11] | F. Song, Z. Guo, D. Mei, Feature selection using principal component analysis, Int. Conf. Syst. Sci., 2 (2010). |
| [12] | C. Lameiro, P. J. Schreier, A sparse CCA algorithm with application to model-order selection for small sample support, ICASSP, IEEE Int. Conf. Acoust. Speech Signal Process. Proc., (2017), 4721–4725. |
| [13] |
Z. Ma, Sparse principal component analysis and iterative thresholding, Ann. Stat., 41 (2013), 772–801. doi: 10.1214/13-AOS1097
|
| [14] | C. M. Feng, Y. L. Gao, J. X. Liu, C. H. Zheng, S. J. Li, D. Wang, A Simple Review of Sparse Principal Components Analysi, Intell. Comput. Theor. Appl., 9772 (2016), 374–383. |
| [15] | L. R. Eun, C. Jinwoo, Y. Kyusang, A systematic review on model selection in high-dimensional regression, J. Korean Stat. Soc., 48 (2019), 12. |
| [16] |
S. Ramírez‐Gallego, I. Lastra, D. Martínez‐Rego, V. Bolón‐Canedo, J. M. Benítez, F. Herrera, et al., Fast‐mRMR: Fast minimum redundancy maximum relevance algorithm for high‐dimensional big data, Int. J. Intell. Syst., 32 (2017), 134–152. doi: 10.1002/int.21833
|
| [17] |
González, J. Ortega, M. Damas, P. Martín-Smith, J.Q. Gan, A new multi-objective wrapper method for feature selection-accuracy and stability analysis for BCI, Neurocomputing, 333 (2019), 407–418. doi: 10.1016/j.neucom.2019.01.017
|
| [18] | X. Xiao, D. Fu, Y. Shi, J. Wen, Optimized Mahalanobis-Taguchi System for high-dimensional small sample data classification, Comput. Intell. Neurosci., 2020 (2020). |
| [19] |
B. Bayar, N. Bouaynaya, R. Shterenberg, SMURC: High-dimension small-sample multivariate regression with covariance estimation, IEEE J. Biomed. Heal. Informatics, 21 (2017), 573–581. doi: 10.1109/JBHI.2016.2515993
|
| [20] | K. Pearson, On lines and planes of closest fit to systems of points in space, Phil. Mag, 2 (1901). |
| [21] |
H. Hotelling, Analysis of a complex of statistical variables into principal components, Educ. Psychol, 24 (1933), 417–441. doi: 10.1037/h0071325
|
| [22] |
G. Kerschen, J. C. Golinval, A. F. Vakakis, L. A. Bergman, The method of proper orthogonal decomposition for dynamical characterization and order reduction of mechanical systems: an overview, Nonlinear Dyn., 41 (2005), 147–169. doi: 10.1007/s11071-005-2803-2
|
| [23] | X. Chen, Research on Several Issues of mahalanobis taguchi System, 2008. |
| [24] |
L. Cheng, V. Yaghoubi, W. Van Paepegem, M. Kersemans, Mahalanobis classification system (MCS) integrated with binary particle swarm optimization for robust quality classification of complex metallic turbine blades, Mech. Syst. Signal Process., 146 (2021), 107060. doi: 10.1016/j.ymssp.2020.107060
|
| [25] | Z. Chang, L. Cheng, L. Cui, Interval choquet fuzzy integral multi-attribute decision-making method based on mahalanobis taguchi system, Control Decis., 31 (2016), 180–186. |
| [26] | Y. Kikuchi, T. Ishihara, Anomaly detection and prediction of high-tension bolts by using strain of tower shell, Wind Energy, (2020), 1–16. |
| [27] | Z. Sheng, L. Cheng, Y. Gu, Research on the generation mechanism of mahalanobis space in mahalanobis taguchi system based on control chart[, Math. Stat. Manag., 26 (2017), 1059–1068. |
| [28] |
Z. Chang, W. Chen, Y. Gu, H. Xu, Mahalanobis-Taguchi System for symbolic interval data based on kernel mahalanobis distance, IEEE Access, 8 (2020), 20428–20438. doi: 10.1109/ACCESS.2020.2967411
|
| [29] | W. Z. A. W. Muhamad, K. R. Jamaludin, S. A. Saad, Z. R. Yahya, S. A. Zakaria, Random binary search algorithm based feature selection in Mahalanobis Taguchi system for breast cancer diagnosis, AIP Conf. Proc., 2018. |
| [30] | E. Zhu, X. Wang, A principal component orthogonal decomposition algorithm suitable for processing fingerprint data of traditional Chinese medicine, J. Xiamen Univ. Natural Sci. Ed., 6 (2005), 150–151. |
| [31] |
K. Lu, Y. Jin, Y. Chen, Y. Yang, L. Hou, Z. Zhang, et al., Review for order reduction based on proper orthogonal decomposition and outlooks of applications in mechanical systems, Mech. Syst. Signal Process., 123 (2019), 264–297. doi: 10.1016/j.ymssp.2019.01.018
|
| [32] | D. Wang, L. He, J. Zhu, Comparison of stock return volatility patterns based on functional adaptive clustering, Stat. Res., 35 (2018), 79–91. |
| [33] |
V. Penenko, E. Tsvetova, Orthogonal decomposition methods for inclusion of climatic data into environmental studies, Ecol. Modell., 217 (2008), 279–291. doi: 10.1016/j.ecolmodel.2008.06.004
|
| [34] |
M. Ohkubo, Y. Nagata, Anomaly detection in high-dimensional data with the Mahalanobis‑Taguchi system, Total Qual. Manag. Bus. Excell., 29 (2018), 1213–1227. doi: 10.1080/14783363.2018.1487615
|
| [35] |
R. Valeria, C. Renato, R. Carlo, U. Lorenzo, C. Sirio, V. Francesco, et al., Prediction of tumor grade and nodal status in oropharyngeal and oral cavity squamous-cell carcinoma using a radiomic approach, Anticancer Res., 40 (2020), 271–280. doi: 10.21873/anticanres.13949
|
| [36] | A. Stanzione, C. Ricciardi, R. Cuocolo, V. Romeo, J. Petrone, M. Sarnataro, et al., MRI radiomics for the prediction of fuhrman grade in clear cell renal cell carcinoma: A machine learning exploratory study, J. Digit. Imaging, (2020), 1–9. |
| [37] | V. Romeo, C. Ricciardi, R. Cuocolo, A. Stanzione, F. Verde, L. Sarno, et al., Machine learning analysis of MRI-derived texture features to predict placenta accreta spectrum in patients with placenta previa Magnetic resonance imaging, 64 (2019), 71–76. |
| [38] |
P. Mesejo, D. Pizarro, A. Abergel, Computer-aided classification of gastrointestinal lesions in regular colonoscopy, IEEE Trans. Med. Imaging, 35 (2016), 2051–2063, . doi: 10.1109/TMI.2016.2547947
|
| [39] |
R. L.Babu, S. Vijayan, Wrapper based feature selection in semantic medical information retrieval, J. Med. Imaging Heal. Informatics, 6 (2016), 802–805. doi: 10.1166/jmihi.2016.1758
|
| [40] |
G. L. Irene, R. V. Esther, Characterization of artifact signals in neck photoplethysmography, IEEE Trans. Biomed. Eng., 67 (2020), 1–1. doi: 10.1109/TBME.2019.2950357
|
| [41] | J. Gardezi, I. Faye, F. Adjed, N. Kamel, M. Hussain, Mammogram classification using chi-square distribution on local binary pattern features, J. Med. Imaging Heal. Informatics, 7 (2017), 30–35. |
| [42] |
H. A. Khan, W. Jue, M. Mushtaq, M. U. Mushtaq, Brain tumor classification in MRI image using convolutional neural network, Math. Biosci. Eng., 17 (2020), 6203. doi: 10.3934/mbe.2020328
|
| [43] | G. D'Addio, C. Ricciardi, G. Improta, P. Bifulco, M. Cesarelli, Feasibility of Machine Learning in Predicting Features Related to Congenital Nystagmus, In: Henriques J., Neves N., de Carvalho P. (eds XV Mediterranean Conference on Medical and Biological Engineering and Computing MEDICON 2019), IFMBE Proceedings, (2020). |
| [44] | M. El-Banna, Modified Mahalanobis Taguchi System for imbalance data classification, Comput. Intell. Neurosci., 2017 (2017). |
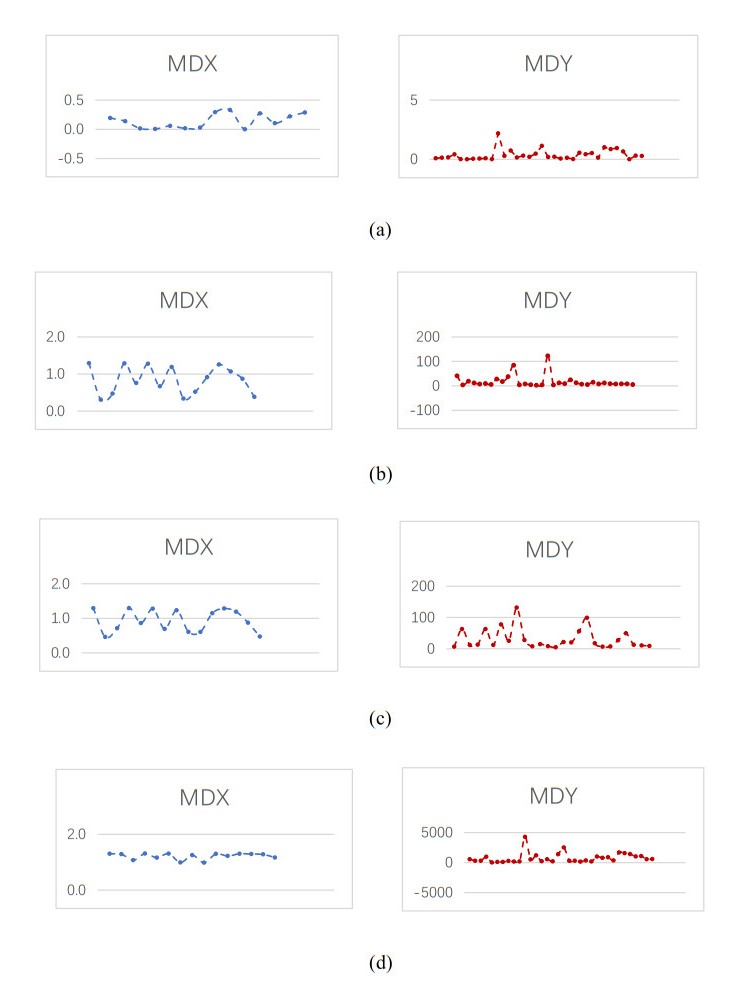
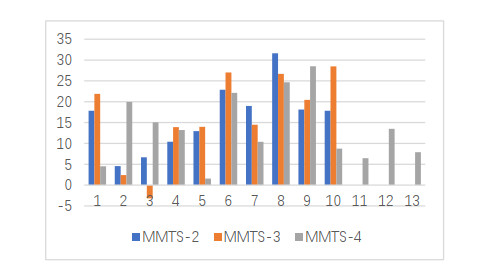
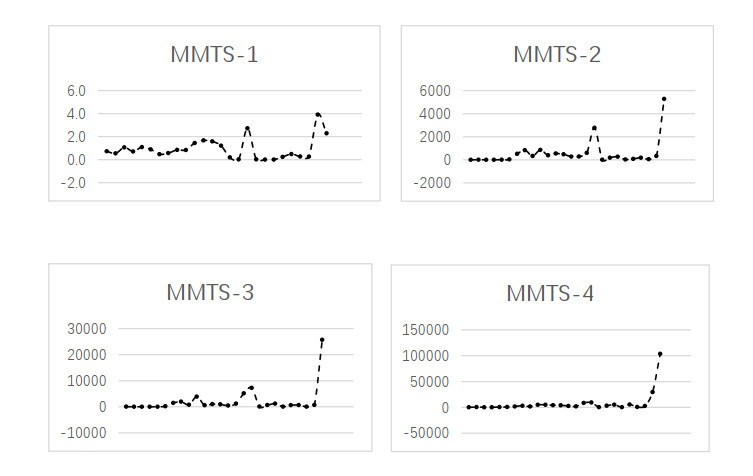
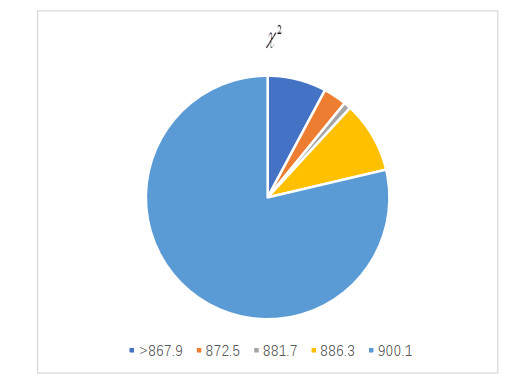
Figures(5) / Tables(4)

Ting Mao, Lanting Yu, Yueyi Zhang, Li Zhou. Modified Mahalanobis-Taguchi System based on proper orthogonal decomposition for high-dimensional-small-sample-size data classification[J]. Mathematical Biosciences and Engineering, 2021, 18(1): 426-444. doi: 10.3934/mbe.2021023







 DownLoad:
DownLoad: