Citation: Yong Tian, Tian Zhang, Qingchao Zhang, Yong Li, Zhaodong Wang. Feature fusion–based preprocessing for steel plate surface defect recognition[J]. Mathematical Biosciences and Engineering, 2020, 17(5): 5672-5685. doi: 10.3934/mbe.2020305

| [1] | D. He, K. Xu, P. Zhou, D. Zhou, Surface defect classification of steels with a new semi-supervised learning method, Opt. Lasers Eng., 117 (2019), 40-48. |
| [2] | R. Gong, M. Chu, Y. Yang, Y. Feng, A multi-class classifier based on support vector hyper-spheres for steel plate surface defects, Chemom. Intell. Lab. Syst., 188 (2019), 70-78. |
| [3] | B. Wu, J. Zhou, X. Ji, Y. Yin, X. Shen, Research on Approaches for Computer Aided Detection of Casting Defects in X-ray Images with Feature Engineering and Machine Learning, Procedia Manuf., 37 (2019), 394-401. |
| [4] | X. Wen, K. Song, M. Niu, Z. Dong, Y. Yan, A three-dimensional inspection system for high temperature steel product surface sample height using stereo vision and blue encoded patterns, Optik, 130 (2017), 131-148 |
| [5] | M. Kuffer, K. Pfeffer, R. Sliuzas, I. Baud, Extraction of slum areas from VHR imagery using GLCM variance, IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., 9 (2016), 1830-1840. |
| [6] | Y. Liu, S. Liu, Z. Wang, Multi-focus image fusion with dense SIFT, Inf. Fusion, 23 (2015), 139-155. |
| [7] | A. Zendehboudi, M. A. Baseer, R. Saidur, Application of support vector machine models for forecasting solar and wind energy resources: A review, J. Cleaner Prod., 199 (2018), 272-285 |
| [8] | I. Rish, An empirical study of the naive Bayes classifier, IJCAI 2001 workshop on empirical methods in artificial intelligence, 2001. |
| [9] | S. Zhang, X. Li, M. Zong, X. Zhu, R. Wang, Efficient knn classification with different numbers of nearest neighbors, IEEE Trans. Neural Networks Learn. Syst., 29 (2018), 1774-1785. |
| [10] | G. Biau, E. Scornet, A random forest guided tour, Test, 25 (2016), 197-227. |
| [11] | C. He, H. Kang, T. Yao, X. Li, An effective classifier based on convolutional neural network and regularized extreme learning machine, Math. Biosci. Eng., 16 (2019), 8309-8321. |
| [12] | L. Wen, Y. Dong, L. Gao, A new ensemble residual convolutional neural network for remaining useful life estimation, Math. Biosci. Eng., 16 (2019), 862-880. |
| [13] | Z. Ning, Y. Feng, M. Collotta, X. Kong, X. Wang, L. Guo, et al., Deep Learning in Edge of Vehicles: Exploring Tri-relationship for Data Transmission, IEEE Trans. Ind. Inf., 15 (2019), 5737-5746. |
| [14] | F. Chen, M. R. Jahanshahi, NB-CNN: Deep learning-based crack detection using convolutional neural network and Naïve Bayes data fusion, IEEE Trans. Ind. Electron., 65 (2018), 4392-4400. |
| [15] | Y. He, K. Song, Q. Meng, Y. Yan, An end-to-end steel surface defect detection approach via fusing multiple hierarchical features, IEEE Trans. Instrum. Meas., 69 (2020), 1493-1504. |
| [16] | Y. Wang, H. Xia, X. Yuan, L. Li, B. Sun, Distributed defect recognition on steel surfaces using an improved random forest algorithm with optimal multi-feature-set fusion, Multimedia Tools Appl., 77 (2018), 16741-16770. |
| [17] | S. Gupta, S. G. Mazumdar, Sobel edge detection algorithm, Int. J. Comput. Sci. Manage. Res., 2 (2013), 1578-1583. |
| [18] | W. Zheng, K. Liu, Research on Edge Detection Algorithm in Digital Image Processing, 2017 2nd International Conference on Materials Science, Machinery and Energy Engineering, 2017. |
| [19] | D. Adlakha, D. Adlakha, R. Tanwar, Analytical comparison between Sobel and Prewitt edge detection techniques, Int. J. Sci. Eng. Res., 7 (2016), 1482-1485. |
| [20] | P. Vit, Comparison of various edge detection technique, Int. J. Signal Process. Image Process. Pattern Recognit., 9 (2016), 143-158. |
| [21] | T. Ahonen, A. Hadid, M. Pietikainen, Face description with local binary patterns: Application to face recognition, IEEE Trans. Pattern Anal. Mach. Intell., 28 (2006), 2037-2041. |
| [22] | K. Song, Y. Yan, A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects, Appl. Surf. Sci., 285 (2013), 858-864. |
| [23] | K. Li, X. Wang, L. Ji, Application of Multi-Scale Feature Fusion and Deep Learning in Detection of Steel Strip Surface Defect, International Conference on Artificial Intelligence and Advanced Manufacturing (AIAM), 2019. |
| [24] | A. El-Sawy, H. EL-Bakry, M. Loey, CNN for handwritten arabic digits recognition based on LeNet-5, International conference on advanced intelligent systems and informatics (AISI), 2016. |
| [25] | A. Krizhevsky, I. Sutskever, G. E. Hinton, ImageNet classification with deep convolutional neural networks, Advances in neural information processing systems (NIPS), 2012. |
| [26] | A. Vedaldi, A. Zisserman, Vgg convolutional neural networks practical, Dep. Eng. Sci. Univ. Oxford, 2016 (2016), 66. |
| [27] | C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, et al., Going deeper with convolutions, Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), 2015. |
| [28] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, Proceedings of the IEEE conference on computer vision and pattern recognition, 2016. |
| [29] | R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, D. Batra, Grad-cam: Visual explanations from deep networks via gradient-based localization, Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017. |



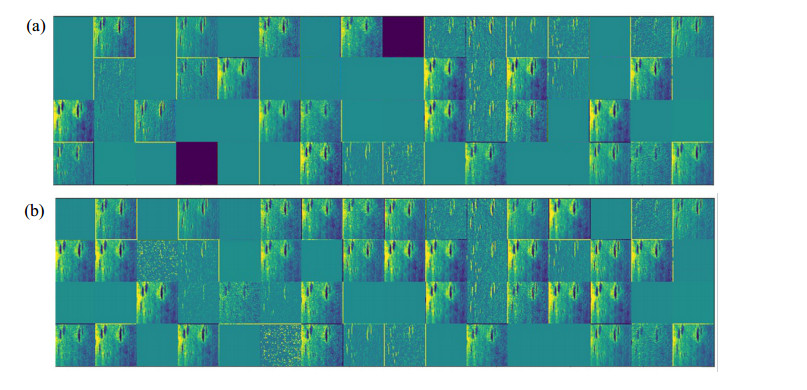
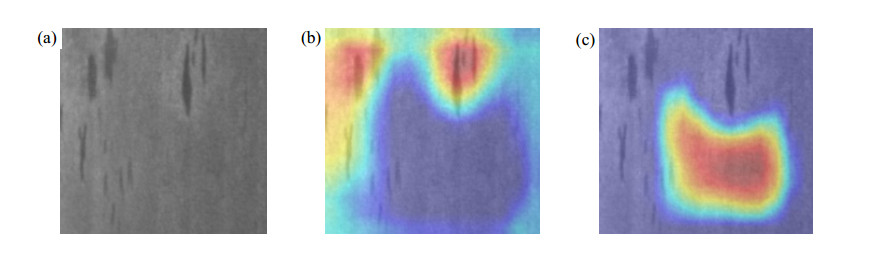
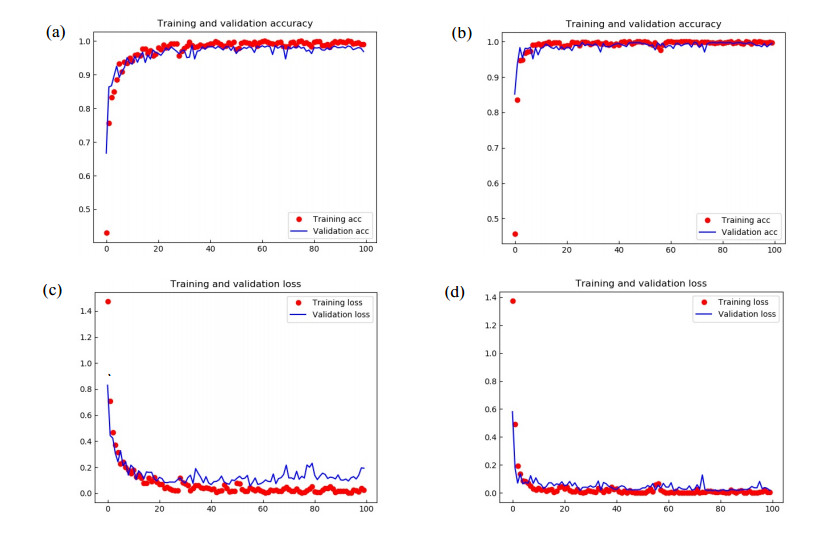
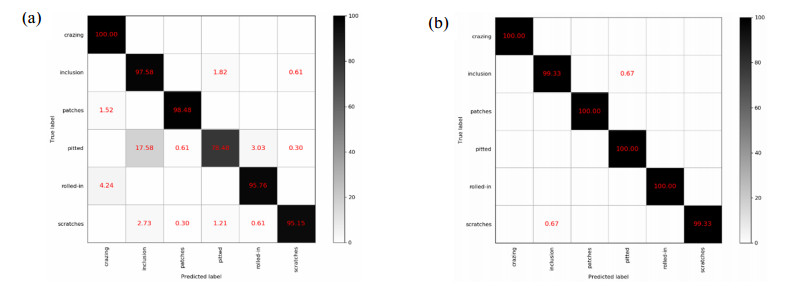
Figures(11) / Tables(2)

Yong Tian, Tian Zhang, Qingchao Zhang, Yong Li, Zhaodong Wang. Feature fusion–based preprocessing for steel plate surface defect recognition[J]. Mathematical Biosciences and Engineering, 2020, 17(5): 5672-5685. doi: 10.3934/mbe.2020305







 DownLoad:
DownLoad: