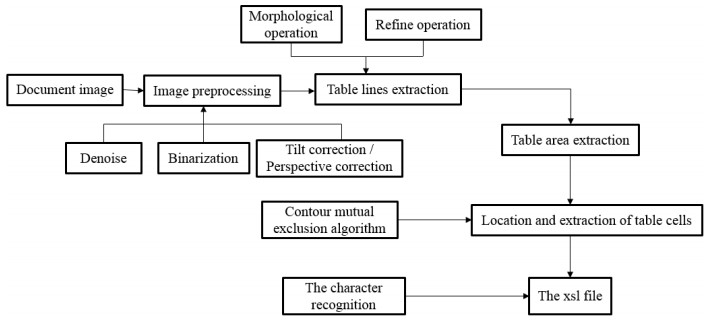
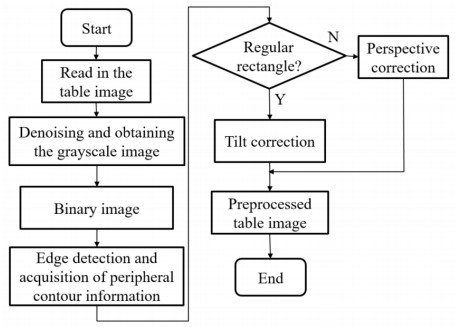
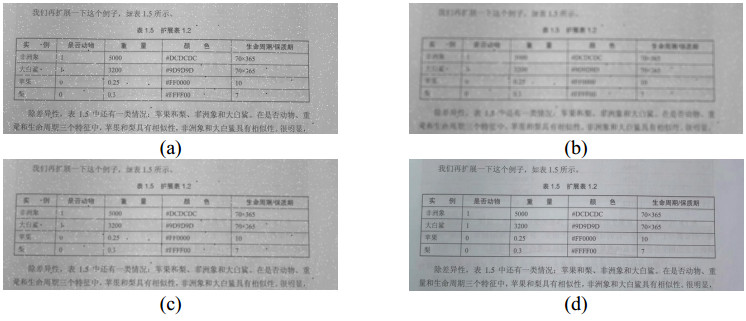
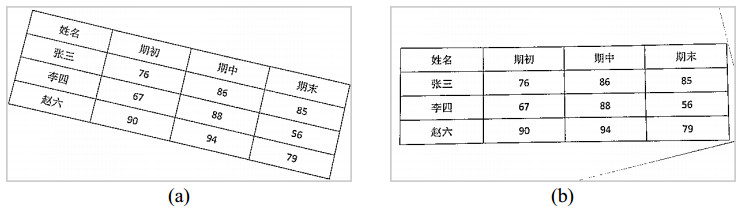
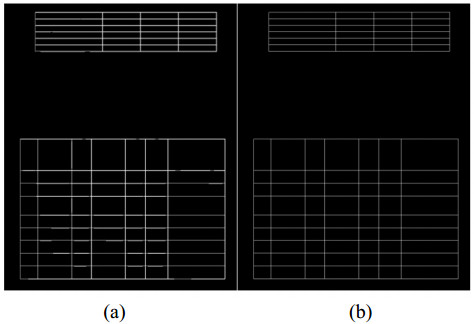
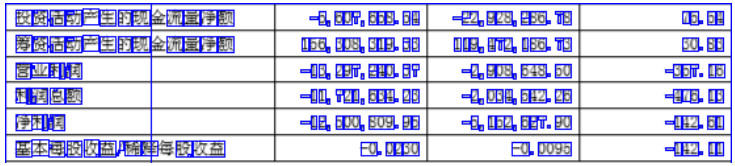
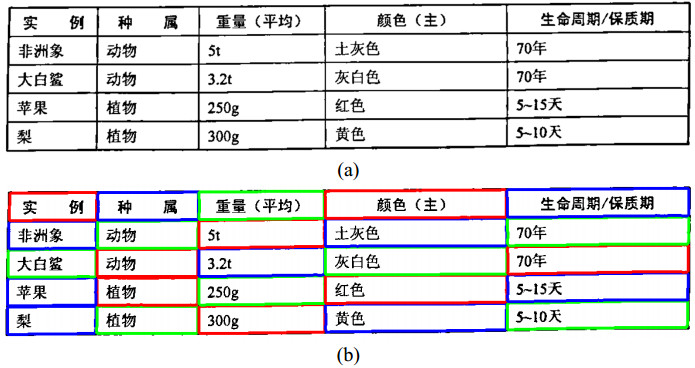
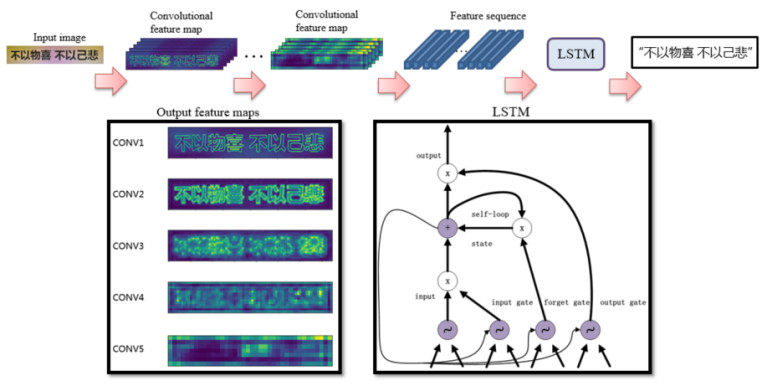
The recognition and analysis of tables on printed document images is a popular research field of the pattern recognition and image processing. Existing table recognition methods usually require high degree of regularity, and the robustness still needs significant improvement. This paper focuses on a robust table recognition system that mainly consists of three parts: Image preprocessing, cell location based on contour mutual exclusion, and recognition of printed Chinese characters based on deep learning network. A table recognition app has been developed based on these proposed algorithms, which can transform the captured images to editable text in real time. The effectiveness of the table recognition app has been verified by testing a dataset of 105 images. The corresponding test results show that it could well identify high-quality tables, and the recognition rate of low-quality tables with distortion and blur reaches 81%, which is considerably higher than those of the existing methods. The work in this paper could give insights into the application of the table recognition and analysis algorithms.
Citation: Qiaokang Liang, Jianzhong Peng, Zhengwei Li, Daqi Xie, Wei Sun, Yaonan Wang, Dan Zhang. Robust table recognition for printed document images[J]. Mathematical Biosciences and Engineering, 2020, 17(4): 3203-3223. doi: 10.3934/mbe.2020182
The recognition and analysis of tables on printed document images is a popular research field of the pattern recognition and image processing. Existing table recognition methods usually require high degree of regularity, and the robustness still needs significant improvement. This paper focuses on a robust table recognition system that mainly consists of three parts: Image preprocessing, cell location based on contour mutual exclusion, and recognition of printed Chinese characters based on deep learning network. A table recognition app has been developed based on these proposed algorithms, which can transform the captured images to editable text in real time. The effectiveness of the table recognition app has been verified by testing a dataset of 105 images. The corresponding test results show that it could well identify high-quality tables, and the recognition rate of low-quality tables with distortion and blur reaches 81%, which is considerably higher than those of the existing methods. The work in this paper could give insights into the application of the table recognition and analysis algorithms.

| [1] | H. Singh, A. Sachan, A Proposed Approach for Character Recognition Using Document Analysis with OCR, 2018 Second International Conference on Intelligent Computing and Control Systems (ICICCS), 2018,190-195. Available from: https://ieeexplore.ieee.org/abstract/document/8663011. |
| [2] | A. M. Sabu, A. S. Das, A Survey on various Optical Character Recognition Techniques, 2018 Conference on Emerging Devices and Smart Systems (ICEDSS), 2018,152-155. Available from: https://ieeexplore.ieee.org/abstract/document/8544323. |
| [3] | V. Ranka, S. Patil, S. Patni, T. Raut, K. Mehrotra, M. K. Gupta, Automatic Table Detection and Retention from Scanned Document Images via Analysis of Structural Information, 2017 Fourth International Conference on Image Information Processing (ICIIP), 2017,244-249. Available from: https://ieeexplore.ieee.org/abstract/document/8313719/. |
| [4] | T. Kasar, T. K. Bhowmik, A. Belaïd, Table information extraction and structure recognition using query patterns, 2015 13th International Conference on Document Analysis and Recognition(ICDAR), 2015, 1086-1090. Available from: https://ieeexplore.ieee.org/abstract/document/7333928. |
| [5] |
E. Cuevas, Block-matching algorithm based on harmony search optimization for motion estimation, Appl. Intell., 39 (2013), 165-183. doi: 10.1007/s10489-012-0403-7

|
| [6] | C. Sage, A. Aussem, H. Elghazel, V. Eglin, J. Espinas, Recurrent Neural Network Approach for Table Field Extraction in Business Documents, International Conference on Document Analysis and Recognition(ICDAR), 2019. Available from: https://hal.archives-ouvertes.fr/hal-02156269/. |
| [7] | A. Shrivastava, D. K. Srivastava, A Review on Pixel-Based Binarization of Gray Images, Proceedings of the International Congress on Information and Communication Technology, 2016,357-364. Available from: https://link.springer.com/chapter/10.1007/978-981-10-0755-2_38. |
| [8] |
A. K. Khambampati, D. Liu, S. K. Konki; K. Y. Kim, An Automatic Detection of the ROI Using Otsu Thresholding in Nonlinear Difference EIT Imaging, IEEE Sens. J., 18 (2018), 5133-5142. doi: 10.1109/JSEN.2018.2828312
|
| [9] |
M. Valizadeh, E. Kabir. Partitioning of feature space by iterative classification for degraded document image binarization, IET image Process., 6 (2012), 804-812. doi: 10.1049/iet-ipr.2011.0399
|
| [10] |
L. P. Saxena, Niblack's binarization method and its modifications to real-time applications: A review, Artif. Intell. Rev., 51 (2019), 673-705. doi: 10.1007/s10462-017-9574-2
|
| [11] |
M. Kiran, I. Ahmed, N. Khan, A. G. Reddy, Chest X-ray segmentation using Sauvola thresholding and Gaussian derivatives responses, J. Ambient Intell. Humanized Comput., 10 (2019), 4179-4195. doi: 10.1007/s12652-019-01281-7
|
| [12] | Z. Hadjadj, A. Meziane, Y. Cherfa, M. Cheriet, I. Setitra, ISauvola: Improved Sauvola's Algorithm for Document Image Binarization, International Conference on Image Analysis and Recognition, 2016,737-745. Available from: https://link.springer.com/chapter/10.1007/978-3-319-41501-7_82. |
| [13] | L. Yang, Q. Feng. The Improvement of Bernsen Binarization Algorithm for QR Code Image, 2018 5th IEEE International Conference on Cloud Computing and Intelligence Systems (CCIS), 2018,931-934. Available from: https://ieeexplore.ieee.org/abstract/document/8691255. |
| [14] | I. Pratikakis, K. Zagoris, G. Barlas, B. Gatos, ICFHR2016 Handwritten Document Image Binarization Contest (H-DIBCO 2016), 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), 2016. Available from: https://ieeexplore.ieee.org/abstract/document/7814134. |
| [15] |
O. Boudraa, W. K. Hidouci, D. Michelucci, Using skeleton and Hough transform variant to correct skew in historical documents, Math. Comput. Simul., 167 (2020), 389-403. doi: 10.1016/j.matcom.2019.05.009
|
| [16] |
T. A. Tran, K Oh, I. S. Na, G. S. Lee, H. J. Yang, S. H. Kim, A robust system for document layout analysis using multilevel homogeneity structure, Expert Syst. Appl., 85 (2017), 99-113. doi: 10.1016/j.eswa.2017.05.030
|
| [17] |
J. Ryu, H. I. Koo, N. I. Cho, Word Segmentation Method for Handwritten Documents based on Structured Learning, IEEE Signal Process. Lett., 22 (2015), 1161-1165. doi: 10.1109/LSP.2015.2389852
|
| [18] | A. Riad, C. Sporer, S. S. Bukhari, A. Dengel, Classification and Information Extraction for Complex and Nested Tabular Structures in Images, 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), 2017, 1156-1161. Available from: https://ieeexplore.ieee.org/abstract/document/8270122. |
| [19] | H. T. Tran, T. A. Tran, I. S. Na, S. H. Kim, Cell decomposition for the table in document image based on analysis of texts and lines distribution, 2016 Eighth International Conference on Ubiquitous and Future Networks (ICUFN), 2016,736-738. Available from: https://ieeexplore.ieee.org/abstract/document/7537135. |
| [20] | A. Krizhevsky, I. Sutskever, G. E. Hinton, ImageNet classification with deep convolutional neural networks, Advances in Neural Information Processing Systems 25 (NIPS 2012), 2012, 1097-1105. Available from: http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networ. |
| [21] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, In Proceedings of the IEEE conference on computer vision and pattern recognition, 2016,770-778. Available form: http://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html. |
| [22] | Y. Wei, Y. Zhao, C. Lu, S. Wei, L. Liu, Z. Zhu, et al. Cross-Modal Retrieval with CNN Visual Features: A New Baseline, IEEE Trans. Cybern., 47 (2017), 449-460. |
| [23] |
C. Tian, Y. Xu, W. Zuo, Image denoising using deep CNN with batch renormalization, Neural Networks, 121 (2020), 461-473. doi: 10.1016/j.neunet.2019.08.022
|
| [24] | D. Yang, H. Zhou, L. Tang, S. Chen, S. Liu, A License Plate Tilt Correction Algorithm Based on the Character Median Line Algorithm de correction d's inclinaison de plaque d's immatriculation base sur la ligne mediane du character, Can. J. Electr. Computer Eng., 41 (2018), 145-150. |
| [25] | Q. An, J. Shi, J. Li, F. Cai, Elevator button recognition using auto-slant correction and projection histogram, 2017 10 th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), 2017. Available from: https://ieeexplore.ieee.org/abstract/document/8302054. |
| [26] | R. Baran, A. Dziech, J. Wassermann, Contour Extraction and Compression Scheme Utilizing Both the Transform and Spatial Image Domains, International Conference on Multimedia Communications, Services and Security, 1-15. Available from: https://link.springer.com/chapter/10.1007/978-3-319-69911-0_1. |
| [27] | J. Tang, H, Huang, L. Shi, Z. Chen, Y. Lu, H. Chen, An Improved Perspective Transform for Image Distortion Correction, 2018 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW), 2018. Available from: https://ieeexplore.ieee.org/abstract/document/8448538/. |
| [28] |
Q. Vien, H. X. Nguyen, B. Barn, X. Tran, On the Perspective Transformation for Efficient Relay Placement in Wireless Multicast Networks, IEEE Commun. Lett., 19 (2015), 275-278. doi: 10.1109/LCOMM.2014.2387163
|
| [29] |
A. C. Jalba, M. H. F. Wilkinson, J. B. T. M. Roerdink, Shape representation and recognition through morphological curvature scale spaces, IEEE Trans. Image Process., 15 (2006), 331-341. doi: 10.1109/TIP.2005.860606
|
| [30] |
Y. Li, H. Zheng, Z. Yan, L. Chen. Detail preservation and feature refinement for object detection, Neurocomputing, 359 (2019), 209-218. doi: 10.1016/j.neucom.2019.05.086
|
| [31] |
M. Naseri, S. Heidari, R. Gheibi, L. Gong, M. A. Raiji, A. Sadri, A novel quantum binary images thinning algorithm: A quantum version of the Hilditch's algorithm, Optik, 131 (2017), 678-686. doi: 10.1016/j.ijleo.2016.11.124
|
| [32] | C. Zhang, W. Zhong, C. Zhang, X. Qin, Simulation Design of Improved OPTA Thinnin Algorithm, International Conference on Mechatronics and Intelligence Roboyics (ICMIR), 2017,105-114. Available from: https://link.springer.com/chapter/10.1007/978-3-319-70990-1_15. |
| [33] | A. K. J. Saudagar, H. V. Mohammed, OpenCV Based Implementation of Zhang-Suen Thinning Algorithm Using Java for Arabic Text Recognition, Information Systems Design and Intelligent Applications, 2016,265-271. Available from: https://link.springer.com/chapter/10.1007/978-81-322-2757-1_27. |
| [34] | X. Shi, Y. Huang, Y. Liu, Text on Oracle rubbing segmentation method based on connected domain, 2016 IEEE Advanced Information Management, Commuincates, Electronic and Automation Control Conference (IMCEC), 2016: 414-418. Available from: https://ieeexplore.ieee.org/abstract/document/7867245. |
| [35] | Y. Sun, Z. Guo, W. Qiu, Research on the Handwriting Character Recognition Technology Based on the Image Statistical Characteristics, International Conference on Geo-Spatial Knowledge and Intelligence, 2018, 13-20. Available from: https://link.springer.com/chapter/10.1007/978-981-13-0896-3_2. |
| [36] |
A. K. Sharma, P. Thakkar, D. M. Adhyaru, T. H. Zaveri, Handwritten Gujarati Character Recognition Using Structural Decomposition Technique, Pattern Recognit. Image Anal., 29 (2019), 325-338. doi: 10.1134/S1054661819010061
|
| [37] | M. D. Zeiler, R. Fergus, Visualizing and understanding convolutional networks, European Conference on Computer Vision. Cham, Switzerland: Springer International Publishing AG, 2014,818-833. Available from: https://link.springer.com/chapter/10.1007/978-3-319-10590-1_53. |
| [38] | K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition, arXiv preprint arXiv: 1409.1556, 2014. |
| [39] | C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, Going deeper with convolutions, In Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, 1-9. Available from: https://www.cv-foundation.org/openaccess/content_cvpr_2015/html/Szegedy_Going_Deeper_With_2015_CVPR_paper.html. |
| [40] | G. Huang, Z. Liu, L. Van Der Maaten, K. Q. Weinberger, Densely connected convolutional networks, In Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, 4700-4708. Available from: http://openaccess.thecvf.com/content_cvpr_2017/html/Huang_Densely_Connected_Convolutional_CVPR_2017_paper.html. |
| [41] | N. K. Manaswi, Deep Learning with Applications Using Python, Springer, (2018), 115-126. |
| [42] | J. Chung, C. Gulcehre, K. Cho, Y. Bengio, Empirical evaluation of gated recurrent neural networks on sequence modeling, arXiv: 1412.3555, 2014. |
| [43] | J. Chung, S. Ahn, Y. Bengio, Hierarchical multiscale recurrent neural networks, arXiv: 1609.01704, 2016. |
| [44] |
G. Liu, J. Guo, Bidirectional LSTM with attention mechanism and convolutional layer for text classification, Neurocomputing, 337 (2019), 325-338. doi: 10.1016/j.neucom.2019.01.078
|
| [45] |
Y. Bengio, P. Simard, P. Frasconi, Learning long-term dependencies with gradient descent is difficult, IEEE Trans. Neural Networks, 5 (1994), 157-166. doi: 10.1109/72.279181
|
| [46] | (CRNN) Chinese Characters Recognition, 2020. Available from: https://github.com/Sierkinhane/crnn_chinese_characters_rec. |
| [47] | S. Ruder, An overview of gradient descent optimization algorithms, 2016. Available from: http://sebastianruder.com/optimizing-gradient-descent/index.html. |
| [48] | M. Fan, D. S. Kim, Detecting Table Region in PDF Documents Using Distant Supervision, arXiv: 1506.08891, 2015. |
| [49] | A. Gilani, S. R. Qasim, I. Malik, F. Shafait, Table Detection Using Deep Learning, 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), 2017,771-776. Available from: https://ieeexplore.ieee.org/abstract/document/8270062. |
| [50] | E. Koci, M. Thiele, O. Romero, W. Lehner, Table Identification and Reconstruction in Spreadsheets, International Conference on Advanced Information Systems Engineering (CAiSE), 2017,527-541, Available from: https://link.springer.com/chapter/10.1007/978-3-319-59536-8_33. |
| [51] | S. Arif, F. Shafait, Table Detection in Document Images using Foreground and Background Features, Digital Image Computing: Techniques and Applications (DICTA), 2018. Available from: https://ieeexplore.ieee.org/abstract/document/8615795. |





Figures(15) / Tables(2)

Qiaokang Liang, Jianzhong Peng, Zhengwei Li, Daqi Xie, Wei Sun, Yaonan Wang, Dan Zhang. Robust table recognition for printed document images[J]. Mathematical Biosciences and Engineering, 2020, 17(4): 3203-3223. doi: 10.3934/mbe.2020182







 DownLoad:
DownLoad: