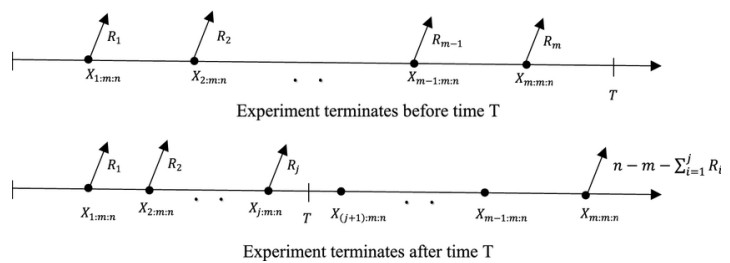
The Power Rayleigh distribution (PRD) is a new extension of the standard one-parameter Rayleigh distribution. To employ this distribution as a life model in the analysis of reliability and survival data, we focused on the statistical inference for the parameters of the PRD under the adaptive Type-II censored scheme. Point and interval estimates for the model parameters and the corresponding reliability function at a given time are obtained using likelihood, Bootstrap and Bayesian estimation methods. A simulation study is conducted in different settings of the life testing experiment to compare and evaluate the performance of the estimates obtained. In addition, the estimation procedure is also investigated in real lifetimes data. The results indicated that the obtained estimates gave an accurate and efficient estimation of the model parameters. The Bootstrap estimates are better than the estimates obtained by the likelihood estimation approach, and estimates obtained using the Markov Chain Monte Carlo method by the Bayesian approach under both the squared error and the general entropy loss functions have priority over other point and interval estimates. Under the adaptive Type-II censoring scheme, concluding results confirmed that the PRD can be effectively used to model the lifetimes in survival and reliability analysis.
Citation: Hatim Solayman Migdadi, Nesreen M. Al-Olaimat, Maryam Mohiuddin, Omar Meqdadi. Statistical inference for the Power Rayleigh distribution based on adaptive progressive Type-II censored data[J]. AIMS Mathematics, 2023, 8(10): 22553-22576. doi: 10.3934/math.20231149
The Power Rayleigh distribution (PRD) is a new extension of the standard one-parameter Rayleigh distribution. To employ this distribution as a life model in the analysis of reliability and survival data, we focused on the statistical inference for the parameters of the PRD under the adaptive Type-II censored scheme. Point and interval estimates for the model parameters and the corresponding reliability function at a given time are obtained using likelihood, Bootstrap and Bayesian estimation methods. A simulation study is conducted in different settings of the life testing experiment to compare and evaluate the performance of the estimates obtained. In addition, the estimation procedure is also investigated in real lifetimes data. The results indicated that the obtained estimates gave an accurate and efficient estimation of the model parameters. The Bootstrap estimates are better than the estimates obtained by the likelihood estimation approach, and estimates obtained using the Markov Chain Monte Carlo method by the Bayesian approach under both the squared error and the general entropy loss functions have priority over other point and interval estimates. Under the adaptive Type-II censoring scheme, concluding results confirmed that the PRD can be effectively used to model the lifetimes in survival and reliability analysis.

| [1] |
N. Balakrishnan, Progressive censoring methodology: An appraisal, TEST, 16 (2007), 211–259. https://doi.org/10.1007/s11749-007-0061-y doi: 10.1007/s11749-007-0061-y

|
| [2] |
R. Aggarwala, N. Balakrishnan, Some properties of progressive censored order statistics from arbitrary and uniform distributions with applications to inference and simulation, J. Stat. Plan. Infer., 70 (1998), 35–49. https://doi.org/10.1016/s0378-3758(97)00173-0 doi: 10.1016/s0378-3758(97)00173-0
|
| [3] |
H. Z. Muhammed, E. M. Almetwally, Bayesian and non-Bayesian estimation for the bivariate inverse weibull distribution under progressive type-II censoring, Ann. Data Sci., 10 (2023), 481–512. https://doi.org/10.1007/s40745-020-00316-7 doi: 10.1007/s40745-020-00316-7
|
| [4] |
R. Alshenawy, A. Al-Alwan, E. M. Almetwally, A. Z. Afify, H. M. Almongy, Progressive type-II censoring schemes of extended odd Weibull exponential distribution with applications in medicine and engineering, Mathematics, 8 (2020), 1679. https://doi.org/10.3390/math8101679 doi: 10.3390/math8101679
|
| [5] |
K. Maiti, S. Kayal, Estimation of parameters and reliability characteristics for a generalized Rayleigh distribution under progressive type-II censored sample, Commun. Stat.-Simul. Comput., 50 (2021), 3669–3698. https://doi.org/10.1080/03610918.2019.1630431 doi: 10.1080/03610918.2019.1630431
|
| [6] |
S. Dey, A. Elshahhat, Analysis of Wilson‐Hilferty distribution under progressive Type‐II censoring, Qual. Reliab. Eng. Int., 38 (2022), 3771–3796. https://doi.org/10.1002/qre.3173 doi: 10.1002/qre.3173
|
| [7] |
A. Elshahhat, A. H. Muse, O. M. Egeh, B. R. Elemary, Estimation for parameters of life of the Marshall-Olkin generalized-exponential distribution using progressive Type-II censored data, Complexity, 2022 (2022), 8155929. https://doi.org/10.1155/2022/8155929 doi: 10.1155/2022/8155929
|
| [8] |
E. M. Almetwally, T. M. Jawa, N. Sayed-Ahmed, C. Park, M. Zakarya, S. Dey, Analysis of unit-Weibull based on progressive type-II censored with optimal scheme, Alex. Eng. J., 63 (2023), 321–338. https://doi.org/10.1016/j.aej.2022.07.064 doi: 10.1016/j.aej.2022.07.064
|
| [9] |
Y. A. Tashkandy, E. M. Almetwally, R. Ragab, A. M. Gemeay, M. M. Abd El-Raouf, S. K. Khosa, et al., Statistical inferences for the extended inverse Weibull distribution under progressive type-II censored sample with applications, Alex. Eng. J., 65 (2023), 493–502. https://doi.org/10.1016/j.aej.2022.09.023 doi: 10.1016/j.aej.2022.09.023
|
| [10] |
S. M. A. Aljeddani, M. A. Mohammed, Estimating the power generalized Weibull Distribution's parameters using three methods under Type-II Censoring-Scheme, Alex. Eng. J., 67 (2023), 219–228. https://doi.org/10.1016/j.aej.2022.12.043 doi: 10.1016/j.aej.2022.12.043
|
| [11] |
H. K. T. Ng, D. Kundu, P. S. Chan, Statistical analysis of exponential lifetimes under an adaptive Type‐II progressive censoring scheme, Nav. Res. Log., 56 (2009), 687–698. https://doi.org/10.1002/nav.20371 doi: 10.1002/nav.20371
|
| [12] |
S. Chen, W. Gui, Statistical analysis of a lifetime distribution with a bathtub-shaped failure rate function under adaptive progressive type-II censoring, Mathematics, 8 (2020), 670. https://doi.org/10.3390/math8050670 doi: 10.3390/math8050670
|
| [13] |
M. H. Abu-Moussa, M. M. Mohie El-Din, M. A. Mosilhy, Statistical inference for Gompertz distribution using the adaptive-general progressive type-II censored samples, Amer. J. Math. Manage. Sci., 40 (2021), 189–211. https://doi.org/10.1080/01966324.2020.1835590 doi: 10.1080/01966324.2020.1835590
|
| [14] |
M. A. W. Mahmoud, A. A. Soliman, A. H. Abd Ellah, R. M. El-Sagheer, Estimation of generalized Pareto under an adaptive type-II progressive censoring, Intell. Inf. Manage., 5 (2013), 73–83. https://doi.org/10.4236/iim.2013.53008 doi: 10.4236/iim.2013.53008
|
| [15] |
S. Asadi, H. Panahi, C. Swarup, S. A. Lone, Inference on adaptive progressive hybrid censored accelerated life test for Gompertz distribution and its evaluation for virus-containing micro droplets data, Alex. Eng. J., 61 (2022), 10071–10084. https://doi.org/10.1016/j.aej.2022.02.061 doi: 10.1016/j.aej.2022.02.061
|
| [16] |
R. Alotaibi, M. Nassar, A. Elshahhat, Computational analysis of XLindley parameters using adaptive Type-II progressive hybrid censoring with applications in chemical engineering, Mathematics, 10 (2022), 3355. https://doi.org/10.3390/math10183355 doi: 10.3390/math10183355
|
| [17] |
S. J. Almalki, A. W. A. Farghal, M. K. Rastogi, G. A. Abd-Elmougod, Partially constant-stress accelerated life tests model for parameters estimation of Kumaraswamy distribution under adaptive Type-II progressive censoring, Alex. Eng. J., 61 (2022), 5133–5143. https://doi.org/10.1016/j.aej.2021.10.035 doi: 10.1016/j.aej.2021.10.035
|
| [18] |
H. H. Ahmad, M. M. Salah, M. S. Eliwa, Z. A. Alhussain, E. M. Almetwally, E. A. Ahmed, Bayesian and non-Bayesian inference under adaptive type-II progressive censored sample with exponentiated power Lindley distribution, J. Appl. Stat., 49 (2022), 2981–3001. https://doi.org/10.1080/02664763.2021.1931819 doi: 10.1080/02664763.2021.1931819
|
| [19] |
K. K. Shukla, R. Shanker, Power Ishita distribution and its application to model lifetime data, Stat. Transit. New Ser., 19 (2018), 135–148. https://doi.org/10.21307/stattrans-2018-008 doi: 10.21307/stattrans-2018-008
|
| [20] | A. A. Bhat, S. P. Ahmad, A new generalization of Rayleigh distribution: Properties and applications, Pak. J. Stat., 36 (2020), 225–250. |
| [21] |
D. Kundu, M. Z. Raqab, Generalized Rayleigh distribution: Different methods of estimations, Comput. Stat. Data Anal., 49 (2005), 187–200. https://doi.org/10.1016/j.csda.2004.05.008 doi: 10.1016/j.csda.2004.05.008
|
| [22] |
K. Ateeq, B. T. Qasim, R. A. Alvi, An extension of Rayleigh distribution and applications, Cogent Math. Stat., 6 (2019), 1622191. https://doi.org/10.1080/25742558.2019.1622191 doi: 10.1080/25742558.2019.1622191
|
| [23] |
M. A. W. Mahmoud, M. G. M. Ghazal, Estimations from the exponentiated Rayleigh distribution based on generalized Type-II hybrid censored data, J. Egypt. Math. Soc., 25 (2017), 71–78. https://doi.org/10.1016/j.joems.2016.06.008 doi: 10.1016/j.joems.2016.06.008
|
| [24] |
E. M. Almetwally, H. M. Almongy, E. A. ElSherpieny, Adaptive type-II progressive censoring schemes based on maximum product spacing with application of generalized Rayleigh distribution, J. Data Sci., 17 (2019), 802–831. https://doi.org/10.6339/jds.201910\textunderscore17(4).0010 doi: 10.6339/jds.201910\textunderscore17(4).0010
|
| [25] |
H. Panahi, N. Moradi, Estimation of the inverted exponentiated Rayleigh distribution based on adaptive Type II progressive hybrid censored sample, J. Comput. Appl. Math., 364 (2020), 112345. https://doi.org/10.1016/j.cam.2019.112345 doi: 10.1016/j.cam.2019.112345
|
| [26] |
S. Gao, J. Yu, W. Gui, Pivotal inference for the inverted exponentiated Rayleigh distribution based on progressive type-II censored data, Amer. J. Math. Manage. Sci., 39 (2020), 315–328. https://doi.org/10.1080/01966324.2020.1762142 doi: 10.1080/01966324.2020.1762142
|
| [27] |
J. Fan, W. Gui, Statistical inference of inverted exponentiated Rayleigh distribution under joint progressively type-II censoring, Entropy, 24 (2022), 171. https://doi.org/10.3390/e24020171 doi: 10.3390/e24020171
|
| [28] | J. F. Lawless, Statistical models and methods for lifetime data, John Wiley & Sons, Inc. 2003. https://doi.org/10.1002/9781118033005 |
| [29] |
N. Metropolis, A. W. Rosenbluth, M. N. Rosenbluth, A. H. Teller, E. Teller, Equation of state calculations by fast computing machines, J. Chem. Phys., 21 (1953), 1087–1092. https://doi.org/10.1063/1.1699114 doi: 10.1063/1.1699114
|
| [30] |
W. K. Hastings, Monte Carlo sampling methods using Markov chains and their applications, Biometrika, 57 (1970), 97–109. https://doi.org/10.1093/biomet/57.1.97 doi: 10.1093/biomet/57.1.97
|
| [31] |
M. H. Chen, Q. M. Shao, Monte Carlo estimation of Bayesian credible and HPD intervals, J. Comput. Graph. Stat., 8 (1999), 69–92. https://doi.org/10.2307/1390921 doi: 10.2307/1390921
|
| [32] |
P. Hall, Theoretical comparison of bootstrap confidence intervals, Ann. Statist., 16 (1988), 927–953. https://doi.org/10.1214/aos/1176350933 doi: 10.1214/aos/1176350933
|
| [33] | B. Efron, R. J. Tibshirani, An introduction to the bootstrap, CRC Press, 1994. |
| [34] |
N. Balakrishnan, R. A. Sandhu, A simple simulational algorithm for generating progressive TypeII censored samples, Amer. Stat., 49 (1995), 229–230. https://doi.org/10.2307/2684646 doi: 10.2307/2684646
|
| [35] |
D. Kundu, Bayesian inference and life testing plan for the Weibull distribution in presence of progressive censoring, Technometrics, 50 (2008), 144–154. https://doi.org/10.1198/004017008000000217 doi: 10.1198/004017008000000217
|
| [36] |
R. Al-Aqtash, C. Lee, F. Famoye, Gumbel-Weibull distribution: Properties and applications, J. Mod. Appl. Stat. Meth., 13 (2014), 11. https://doi.org/10.22237/jmasm/1414815000 doi: 10.22237/jmasm/1414815000
|







Figures(8) / Tables(9)

Hatim Solayman Migdadi, Nesreen M. Al-Olaimat, Maryam Mohiuddin, Omar Meqdadi. Statistical inference for the Power Rayleigh distribution based on adaptive progressive Type-II censored data[J]. AIMS Mathematics, 2023, 8(10): 22553-22576. doi: 10.3934/math.20231149







 DownLoad:
DownLoad: