Citation: Song-Ju Kim, Tohru Tsuruoka, Tsuyoshi Hasegawa, Masashi Aono, Kazuya Terabe, Masakazu Aono. Decision maker based on atomic switches[J]. AIMS Materials Science, 2016, 3(1): 245-259. doi: 10.3934/matersci.2016.1.245

| [1] |
Castro LN (2007) Fundamentals of natural computing: an overview. Physics of Life Reviews 4: 1-36. doi: 10.1016/j.plrev.2006.10.002

|
| [2] | Kari L, Rozenberg G (2008) The many facets of natural computing. Communications of the ACM 51: 72-83. |
| [3] | Rozenberg G, Back T, Kok J (2012) Handbook of natural computing, Springer-Verlag. |
| [4] |
Kirkpatrick S, Gelatt CD, Vecchi MP (1983) Optimization in simulated annealing. Science 220: 671-680. doi: 10.1126/science.220.4598.671
|
| [5] | Hopfield JJ, Tank DW (1985) Neural computation of decisions in optimization problems. Biological Cybernetics 52: 141-152. |
| [6] |
Brady RM (1985) Optimization strategies gleaned from biological evolution. Nature 317: 804-806. doi: 10.1038/317804a0
|
| [7] |
Adelman LM (1994) Molecular computation of solutions to combinatorial problems. Science 266: 1021-1024. doi: 10.1126/science.7973651
|
| [8] | Terabe K, Hasegawa T, Nakayama T, et al. (2001) Quantum point contact switch realized by solid electrochemical reaction. RIKEN Review 37: 7-8. |
| [9] |
Terabe K, Hasegawa T, Nakayama T, et al. (2005) Quantized conductance atomic switch. Nature 433: 47-50. doi: 10.1038/nature03190
|
| [10] |
Kim S-J, Aono M, Nameda E (2015) Efficient decision-making by volume-conserving physical object. New J Phys 17: 083023. doi: 10.1088/1367-2630/17/8/083023
|
| [11] |
Robbins H (1952) Some aspects of the sequential design of experiments. Bull Amer Math Soc 58: 527-536. doi: 10.1090/S0002-9904-1952-09620-8
|
| [12] |
Thompson W (1933) On the likelihood that one unknown probability exceeds another in view of the evidence of two samples. Biometrika 25: 285-294. doi: 10.1093/biomet/25.3-4.285
|
| [13] | Gittins J, Jones D (1974) Dynamic allocation index for the sequential design of experiments, In: Gans, J. Progress in Statistics North Holland, 241-266. |
| [14] | Gittins J (1979) Bandit processes and dynamic allocation indices. J R Stat Soc B 41: 148-177. |
| [15] |
Agrawal R (1995) Sample mean based index policies with O(log n) regret for the multi-armed bandit problem. Adv Appl Prob 27: 1054-1078. doi: 10.2307/1427934
|
| [16] |
Auer P, Cesa-Bianchi N, Fischer P (2002) Finite-time analysis of the multiarmed bandit problem. Machine Learning 47: 235-256. doi: 10.1023/A:1013689704352
|
| [17] | Lai L, Jiang H, Poor HV (2008) Medium access in cognitive radio networks: a competitive multiarmed bandit framework. Proc. of IEEE 42nd Asilomar Conference on Signals, System and Computers, 98-102. |
| [18] |
Lai L, Gamal HE, Jiang H, et al. (2011) Cognitive medium access: exploration, exploitation, and competition. IEEE Trans. on Mobile Computing 10: 239-253. doi: 10.1109/TMC.2010.65
|
| [19] | Agarwal D, Chen BC, Elango P (2009) Explore/exploit schemes for web content optimization. Proc of ICDM2009, http://dx.doi.org/10.1109/ICDM.2009.52. |
| [20] | Kocsis L, Szepesv´ari C. (2006) Bandit based monte-carlo planning, In: Carbonell, J. G. et al., 17th European Conference on Machine Learning, Lecture Notes in Artificial Intelligence 4212, Springer, 282-293. |
| [21] | Gelly S, Wang Y, Munos R, et al. (2006) Modification of UCT with patterns in Monte-Carlo Go. RR-6062-INRIA, 1-19. |
| [22] |
Demis EC, Aguilera R, Sillin HO, et al. (2015) Atomic switch networks - nanoarchitectonic design of a complex system for natural computing. Nanotechnology 26: 204003. doi: 10.1088/0957-4484/26/20/204003
|
| [23] |
Avizienis AV, Sillin HO, Martin-Olmos C, et al. (2012) Neuromorphic atomic switch networks. PLoS ONE 7: e42772. doi: 10.1371/journal.pone.0042772
|
| [24] | Sutton R, Barto A (1998) Reinforcement Learning: An Introduction, MIT Press. |
| [25] | Kim S-J, Aono M, Hara M (2010) Tug-of-war model for multi-armed bandit problem, In: Calude C. et al. Unconventional Computation, Lecture Notes in Computer Science 6079, Springer, 69-80. |
| [26] |
Kim S-J, Aono M, Hara M (2010) Tug-of-war model for the two-bandit problem: Nonlocallycorrelated parallel exploration via resource conservation. BioSystems 101: 29-36. doi: 10.1016/j.biosystems.2010.04.002
|
| [27] |
Kim S-J, Naruse M, Aono M, et al. (2013) Decision maker based on nanoscale photo-excitation transfer. Sci Rep 3: 2370. doi: 10.1038/srep02370
|
| [28] |
Naruse M, NomuraW, Aono M, et al. (2014) Decision making based on optical excitation transfer via near-field interactions between quantum dots. J Appl Phys 116: 154303. doi: 10.1063/1.4898570
|
| [29] |
Naruse M, Berthel M, Drezet A, et al. (2015) Single photon decision maker Sci Rep 5: 13253. doi: 10.1038/srep13253
|
| [30] |
Tsuruoka T, Hasegawa T, Terabe K, et al. (2012) Conductance quantization and synaptic behavior in a Ta2O5-based atomic switch. Nanotechnology 23: 435705. doi: 10.1088/0957-4484/23/43/435705
|
| [31] | Roughgarden T (2005) Selfish routing and the price of anarchy, MIT Press, Cambridge. |
| [32] | Nisan N, Roughgarden T, Tardos E, et al. (2007) Algorithmic Game Theory, Cambridge Univ. Press. |
| [33] | Kim S-J, Aono M (2015) Decision maker using coupled incompressible-fluid cylinders. Special issue of Advances in Science, Technology and Environmentology B11: 41-45, Available from: http://arxiv.org/abs/1502.03890. |
| [34] | Kim S-J, Naruse M, Aono M (2015) Harnessing natural fluctuations: analogue computer for efficient socially-maximal decision-making. eprint arXiv, Available from: http://arxiv.org/abs/1504.03451. |
| [35] | Vermorel J, Mohri M (2005) Multi-armed bandit algorithms and empirical evaluation, In: Gama J., et al. 16th European Conference on Machine Learning. Lecture Notes in Artificial Intelligence 3720, Springer, 437-448. |
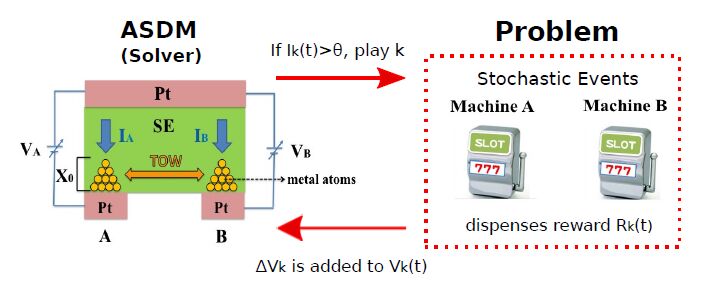
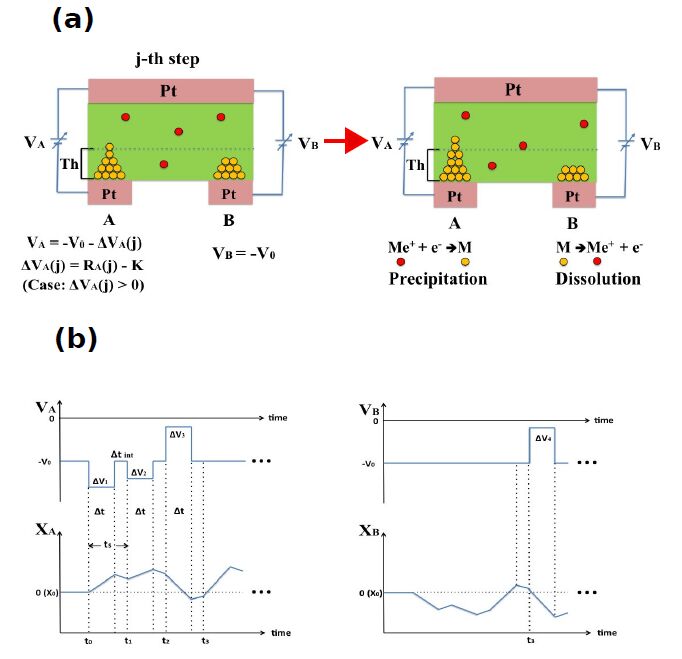
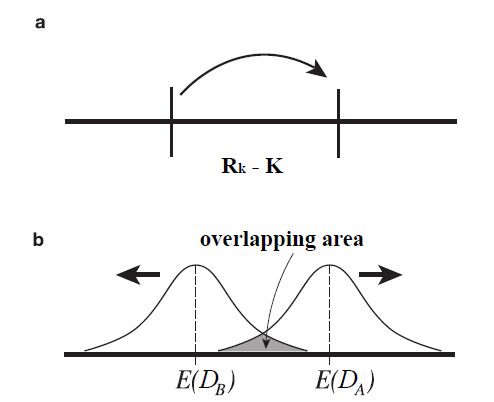
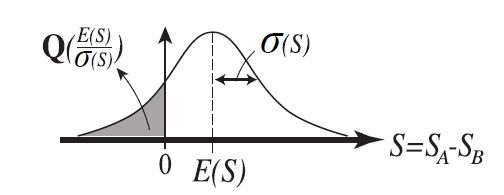
Figures(5) / Tables(1)

Song-Ju Kim, Tohru Tsuruoka, Tsuyoshi Hasegawa, Masashi Aono, Kazuya Terabe, Masakazu Aono. Decision maker based on atomic switches[J]. AIMS Materials Science, 2016, 3(1): 245-259. doi: 10.3934/matersci.2016.1.245







 DownLoad:
DownLoad: