Citation: Grujicic Mica, Ramaswami S., S. Snipes J., Yavari R.. Multi-Scale Computation-Based Design of Nano-Segregated Polyurea for Maximum Shockwave-Mitigation Performance[J]. AIMS Materials Science, 2014, 1(1): 15-27. doi: 10.3934/matersci.2014.1.15

| [1] | Castagna AM, Pangon A, Choi T, et al. (2012) The role of soft segment molecular weight on microphase separation and dynamics of bulk polymerized polyureas.Macromol 45: 8438-8444. |
| [2] | Grujicic M, Yavari R, Snipes JS, et al. (2013) Discrete Element Modeling and Analysis of Structural Collapse/Survivability of a Building Subjected to Improvised Explosive Device (IED) Attack.Adv Mater Sci Appl 2: 9-24. |
| [3] | Grujicic M, Pandurangan B, He T, et al. (2010) Computational Investigation of Impact Energy Absorption Capability of Polyurea Coatings via Deformation-Induced Glass Transition.Mater Sci Eng A, 527: 7741-7751. |
| [4] | Grujicic M, Arakere A, Pandurangan B, et al. (2012) Computational Investigation of Shock-Mitigation Efficacy of Polyurea when used in a Combat Helmet: A Core Sample Analysis.Multidisc Model Mater Struc 8: 297-331. |
| [5] | Grujicic M, Snipes JS, Ramaswami S, et al.Meso-Scale Computational Investigation of Shock-Wave Attenuation by Trailing Release-Wave in Different Grades of Polyurea.J Mater Eng Perform, in press . |
| [6] | Settles G. (2013) Pennsylvania State University.work in progress . |
| [7] | Grujicic M, Yavari R, Snipes JS, et al. (2013) Molecular-Level Computational Investigation of Shock-Wave Mitigation Capability of Polyurea.J Mater Sci 47: 8197-8215. |
| [8] | Grujicic M, Snipes JS, Ramaswami S, et al. (2013) Coarse-Grained Molecular-Level Analysis of Polyurea Properties and Shock-Mitigation Potential.J Mater Eng Perform 22: 1964-1981. |
| [9] | Sun H, Ren P, Fried JR (1998) The Compass Force-field: Parameterization and Validation for Phosphazenes.Comput Theor Polym Sci 8: 229-246. |
| [10] | Grujicic M, Bell WC, Pandurangan B, et al. (2010) Blast-wave Impact-Mitigation Capability of Polyurea When Used as Helmet Suspension Pad Material.Mater Des 31: 4050-4065. |
| [11] | Grujicic A, LaBerge M, Grujicic M, et al. (2012) Potential Improvements in Shock-Mitigation Efficacy of A Polyurea-Augmented Advanced Combat Helmet: A Computational Investigation.J Mater Eng Perform 21: 1562-1579. |
| [12] | Grujicic M, Olson GB, Owen WS (1985) Mobility of the β1-γ1' Martensitic Interface in Cu-Al-Ni. I. Experimental Measurements.Metall Trans 16A: 1723-1734. |
| [13] | Grujicic M, Bell WC, Pandurangan B, et al. (2012) Inclusion of Material Nonlinearity and Inelasticity into a Continuum-Level Material Model for Soda-lime Glass.J Mater Des 35: 144-155. |
| [14] | Grujicic M, Snipes JS, Ramaswami S, et al. (2013) Molecular- and Domain-Level Microstructure Dependent Material Model for Nano-Segregated Polyurea.Multidisc Model Mater Struc 9: 548-578. |
| [15] | Grujicic M, He T, Pandurangan B, et al. (2011) Development and Parameterization of a Time-Invariant (Equilibrium) Material Model for Segmented Elastomeric Polyureas.J Mater: Des Appl 225: 182-194. |
| [16] | Grujicic M, d'Entremont BP, Pandurangan B, et al. (2012) A Study of the Blast-induced Brain White-Matter Damage and the Associated Diffuse Axonal Injury.Multidisc Model Mater Struc 8: 213-245. |
| [17] | Grujicic M, d'Entremont BP, Pandurangan B, et al. (2012) Concept-Level Analysis and Design of Polyurea for Enhanced Blast-Mitigation Performance.J Mater Eng Perform 21: 2024-2037. |
| [18] | Grujicic M, Pandurangan B (2012) Meso-Scale Analysis of Segmental Dynamics in Micro-phase Segregated Polyurea.J Mater Sci 47: 3876-3889. |
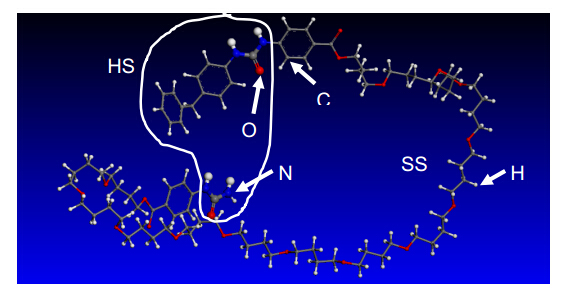
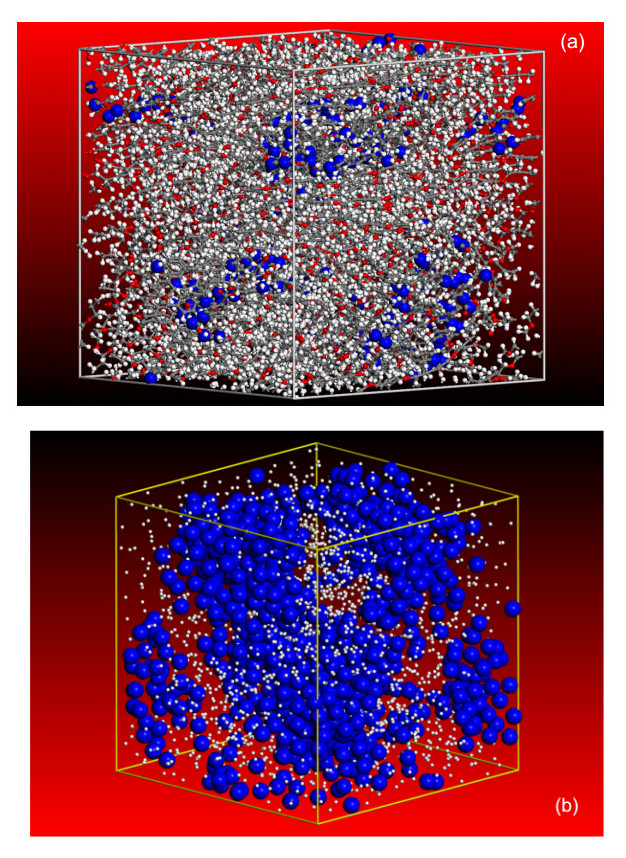

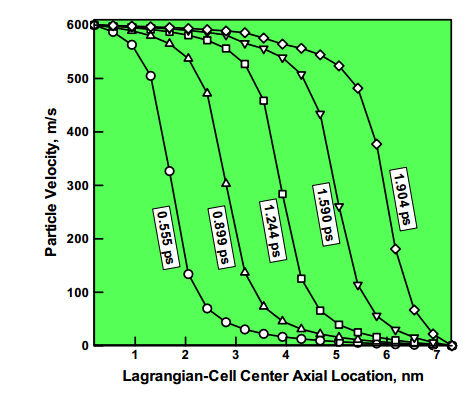
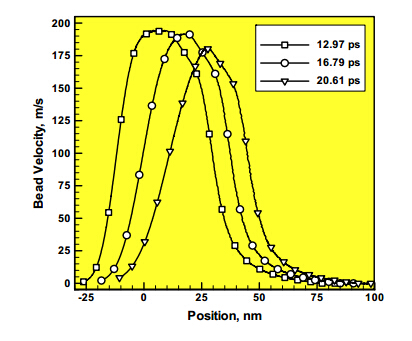
Figures(8)

Grujicic Mica, Ramaswami S., S. Snipes J., Yavari R.. Multi-Scale Computation-Based Design of Nano-Segregated Polyurea for Maximum Shockwave-Mitigation Performance[J]. AIMS Materials Science, 2014, 1(1): 15-27. doi: 10.3934/matersci.2014.1.15







 DownLoad:
DownLoad: