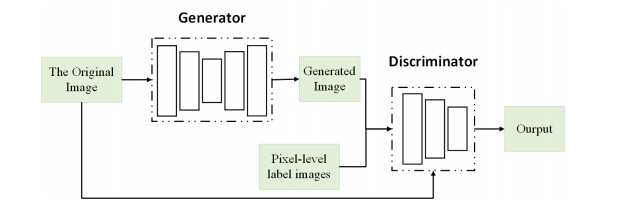
People's diversified tourism needs provide a broad development space and atmosphere for various tourism forms. The geographic resource information of the tourism unit can vividly highlight the unit's geographic spatial location and reflect the individual's spatial and attribute characteristics. It is not only the main goal of researching the information base of tourism resources, but it is also the difficulty that needs to be solved at present. This paper describes the use of image processing technology to realize the analysis and positioning of geographic tourism resources. Specifically, we propose a conditional generative adversarial network (CGAN) model, Ra-CGAN, with a multi-level channel attention mechanism. First, we built a generative model G with a multi-level channel attention mechanism. By fusing deep semantic and shallow detail information containing the attention mechanism, the network can extract rich contextual information. Second, we constructed a discriminative network D. We improved the segmentation results by correcting the difference between the ground-truth label map and the segmentation map generated by the generative model. Finally, through adversarial training between G and D with conditional constraints, we enabled high-order data distribution features learning to improve the boundary accuracy and smoothness of the segmentation results. In this study, the proposed method was validated on the large-scale remote sensing image object detection datasets DIOR and DOTA. Compared with the existing work, the method proposed in this paper achieves very good performance.
Citation: Xiuxia Li. Analysis and positioning of geographic tourism resources based on image processing method with Ra-CGAN modeling[J]. AIMS Geosciences, 2022, 8(4): 658-668. doi: 10.3934/geosci.2022036
People's diversified tourism needs provide a broad development space and atmosphere for various tourism forms. The geographic resource information of the tourism unit can vividly highlight the unit's geographic spatial location and reflect the individual's spatial and attribute characteristics. It is not only the main goal of researching the information base of tourism resources, but it is also the difficulty that needs to be solved at present. This paper describes the use of image processing technology to realize the analysis and positioning of geographic tourism resources. Specifically, we propose a conditional generative adversarial network (CGAN) model, Ra-CGAN, with a multi-level channel attention mechanism. First, we built a generative model G with a multi-level channel attention mechanism. By fusing deep semantic and shallow detail information containing the attention mechanism, the network can extract rich contextual information. Second, we constructed a discriminative network D. We improved the segmentation results by correcting the difference between the ground-truth label map and the segmentation map generated by the generative model. Finally, through adversarial training between G and D with conditional constraints, we enabled high-order data distribution features learning to improve the boundary accuracy and smoothness of the segmentation results. In this study, the proposed method was validated on the large-scale remote sensing image object detection datasets DIOR and DOTA. Compared with the existing work, the method proposed in this paper achieves very good performance.

| [1] |
Li K, Wan G, Cheng G, et al. (2020) Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J Photogram Remote Sens 159: 296–307. https://doi.org/10.1016/j.isprsjprs.2019.11.023 doi: 10.1016/j.isprsjprs.2019.11.023

|
| [2] | Xia GS, Bai X, Ding J, et al. (2018) DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE conference on computer vision and pattern recognition, 3974–3983. https://doi.org/10.1109/CVPR.2018.00418 |
| [3] |
Cheng G, Zhou P, Han J (2016) Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans Geosci Remote Sens 54: 7405–7415. https://doi.org/10.1109/TGRS.2016.2601622 doi: 10.1109/TGRS.2016.2601622
|
| [4] |
Long Y, Gong Y, Xiao Z, et al. (2017) Accurate object localization in remote sensing images based on convolutional neural networks. IEEE Trans Geosci Remote Sens 55: 2486–2498. https://doi.org/10.1109/TGRS.2016.2645610 doi: 10.1109/TGRS.2016.2645610
|
| [5] |
Cheng G, Han J, Zhou P, et al. (2018) Learning rotation-invariant and fisher discriminative convolutional neural networks for object detection. IEEE Trans Image Process 28: 265–278. https://doi.org/10.1109/TIP.2018.2867198 doi: 10.1109/TIP.2018.2867198
|
| [6] |
Deng Z, Sun H, Zhou S, et al. (2017) Toward fast and accurate vehicle detection in aerial images using coupled region-based convolutional neural networks. IEEE J Sel Top Appl Earth Obs Remote Sens 10: 3652–3664. https://doi.org/10.1109/JSTARS.2017.2694890 doi: 10.1109/JSTARS.2017.2694890
|
| [7] |
Li K, Cheng G, Bu S, et al. (2017) Rotation-insensitive and context-augmented object detection in remote sensing images. IEEE Trans Geosci Remote Sens 56: 2337–2348. https://doi.org/10.1109/TGRS.2017.2778300 doi: 10.1109/TGRS.2017.2778300
|
| [8] |
Zhang S, He G, Chen HB, et al. (2019) Scale adaptive proposal network for object detection in remote sensing images. IEEE Geosci Remote Sens Lett 16: 864–868. https://doi.org/10.1109/LGRS.2018.2888887 doi: 10.1109/LGRS.2018.2888887
|
| [9] |
Cheng G, Si Y, Hong H, et al. (2020) Cross-scale feature fusion for object detection in optical remote sensing images. IEEE Geosci Remote Sens Lett 18: 431–435. https://doi.org/10.1109/LGRS.2020.2975541 doi: 10.1109/LGRS.2020.2975541
|
| [10] | Li C, Xu C, Cui Z, et al. (2019) Feature-attentioned object detection in remote sensing imagery. In 2019 IEEE International Conference on Image Processing (ICIP), 3886–3890. https://doi.org/10.1109/ICIP.2019.8803521 |
| [11] | Jin F, Wang F, Rui J, et al. (2017) Residential area extraction based on conditional generative adversarial networks. In 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), IEEE, 1–5. https://doi.org/10.1109/BIGSARDATA.2017.8124931 |
| [12] |
Yu Y, Li X, Liu F (2019) Attention GANs: Unsupervised deep feature learning for aerial scene classification. IEEE Trans Geosci Remote Sens 58: 519–531. https://doi.org/10.1109/TGRS.2019.2937830 doi: 10.1109/TGRS.2019.2937830
|
| [13] | Hu J, Shen L, Sun G (2018) Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 7132–7141. https://doi.org/10.1109/CVPR.2018.00745 |
| [14] | Fang Y, Li P, Zhang J, et al. (2021) Cohesion Intensive Hash Code Book Co-construction for Efficiently Localizing Sketch Depicted Scenes. IEEE Trans Geosci Remote Sens. https: //doi.org/10.1109/TGRS.2021.3132296 |
| [15] |
Everingham M, Van Gool L, Williams CKI, et al. (2010) The pascal visual object classes (voc) challenge. Int J Comput Vis 88: 303–338. https://doi.org/10.1007/s11263-009-0275-4 doi: 10.1007/s11263-009-0275-4
|
| [16] | Ren S, He K, Girshick R, et al. (2015) Faster r-cnn: Towards real-time object detection with region proposal networks. Adv Neural Inf Process Syst 28. |
| [17] | Law H, Deng J (2018) Cornernet: Detecting objects as paired keypoints. In Proceedings of the European conference on computer vision (ECCV), 734–750. https://doi.org/10.1007/978-3-030-01264-9_45 |
| [18] | Redmon J, Farhadi A (2018) Yolov3: An incremental improvement. arXiv preprint arXiv: 1804.02767. |
| [19] | Bochkovskiy A, Wang CY, Liao HYM (2020) Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv: 2004.10934. |
| [20] | Dai J, Li Y, He K, et al. (2016) R-fcn: Object detection via region-based fully convolutional networks. Adv Neural Inf Process Syst 29. |
| [21] | Redmon J, Farhadi A (2017) YOLO9000: better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition, 7263–7271. https://doi.org/10.1109/CVPR.2017.690 |
| [22] | Thuan D (2021) Evolution of Yolo algorithm and Yolov5: The State-of-the-Art object detention algorithm. |


Figures(3)

Xiuxia Li. Analysis and positioning of geographic tourism resources based on image processing method with Ra-CGAN modeling[J]. AIMS Geosciences, 2022, 8(4): 658-668. doi: 10.3934/geosci.2022036







 DownLoad:
DownLoad: