Citation: Gianniantonio Petruzzelli, Francesca Pedron, Irene Rosellini. Bioavailability and bioaccessibility in soil: a short review and a case study[J]. AIMS Environmental Science, 2020, 7(2): 208-225. doi: 10.3934/environsci.2020013

| [1] |
Oliver MA, Gregory PJ (2015) Soil, food security and human health: a review. Eur J Soil Sci 66: 257-276. doi: 10.1111/ejss.12216

|
| [2] |
Zhao FJ (2018) Soil and human health. Eur J Soil Sci 69: 158. doi: 10.1111/ejss.12528
|
| [3] | Petruzzelli G, Gorini F, Pezzarossa B, et al. (2010) The fate of pollutants in soil. CNR Environment and Health Inter-departmental Project, 1-25. |
| [4] |
McLaren L, Hawe P (2005) Ecological perspectives in health research. J Epidemiol Community Health 59: 6-14. doi: 10.1136/jech.2003.018044
|
| [5] | NRC National Research Council. Bioavailability of contaminants in soils and sediments: processes, tools and applications; National Academies: Washington, DC, 2002. |
| [6] | Petruzzelli G, Pedron F, Rosellini I, et al. (2015) The Bioavailability Processes as a Key to Evaluate Phytoremediation Efficiency, In: Ansari, A.A., Gill, S.S., Gill, S., Lanza, G.R., Newman, L. Editors, Phytoremediation: Management of Environmental Contaminants, Switzerland: Springer International Publishing. 1: 31-43. |
| [7] |
Petruzzelli G, Pedron F, Rosellini I, et al. (2013) Phytoremediation towards the future: focus on bioavailable contam+inants, In: Gupta, D.K. Editor, Plant-based remediation processes. Soil biology, Berlin: Springer, 35: 273-289. doi: 10.1007/978-3-642-35564-6_13
|
| [8] |
Guney M, Zagury GJ, Dogan N, et al. (2010) Exposure assessment and risk characterization from trace elements following soil ingestion by children exposed to playgrounds, parks and picnic areas. J Hazard Mater 182: 656-664. doi: 10.1016/j.jhazmat.2010.06.082
|
| [9] |
Luo XS, Ding J, Xu B, et al. (2012) Incorporating bioaccessibility into human health risk assessments of heavy metals in urban park soils. Sci Total Environ 424: 88-96. doi: 10.1016/j.scitotenv.2012.02.053
|
| [10] |
Ng JC, Juhasz A, Smith E, et al. (2015) Assessing the bioavailability and bioaccessibility of metals and metalloids. Environ Sci Pollut Res 22: 8802-8825. doi: 10.1007/s11356-013-1820-9
|
| [11] |
Wilson R, Mitchell I, Richardson GM (2016) Estimation of dust ingestion rates in units of surface area per day using a mechanistic hand-to-mouth model. Hum Ecol Risk Assess 22: 874-881. doi: 10.1080/10807039.2015.1115956
|
| [12] |
Van Wijnen JH, Clausing P, Brunekreef B (1990) Estimated soil ingestion by children. Environ Res 51: 147-162. doi: 10.1016/S0013-9351(05)80085-4
|
| [13] | Abrahams PW (2002) Soils: their implications to human health. Sci Total Environ 219: 1-32. |
| [14] | Plumlee GS, Morman SA, Zeigler TL (2006) The toxicological geochemistry of earth materials: An overview of processes and the interdisciplinary methods used to understand them, In: Sahai, N., Schoonen, M.A.A. Editors, Medical Mineralogy and Geochemistry Reviews in Mineralogy and Geochemistry, Washington DC: Mineralogical Society of America. 64: 5-57. |
| [15] | Plumlee GS, Ziegler TL (2007) The medical geochemistry of dusts, soils, and other earth materials, In: Lollar BS, Holland HD, Turekian, KK. Editors, Treatise on Geochemistry, Oxford: Elsevier. 9: 1-61. |
| [16] | Selinus O, Alloway B, Centeno J, et al. (2005) Essentials of Medical Geology: Impacts of the Natural Environment on Public Health, London, UK: Elsevier Academic Press. |
| [17] | Purakayastha TJ, Chhonkar PK (2010) Phytoremediation of Heavy Metal Contaminated Soils, In: Sherameti, I, Varma, A. Editors, Soil Heavy Metals, Soil Biology, Berlin Heidelberg: Springer-Verlag. 389-429. |
| [18] |
Li YM, Chaney R, Brewer E, et al. (2003) Development of a technology for commercial phytoextraction of nickel: economic and technical considerations. Plant Soil 249: 107-115. doi: 10.1023/A:1022527330401
|
| [19] | Chaney RL, Angle JS, McIntosh MS, et al. (2005) Using hyperaccumulator plants to phytoextract soil Ni and Cd. Z Naturforsch C 60: 190-198. |
| [20] | Abdullah S, Sarem SM (2010) The potential of Chrysanthemum and Pelargonium for phytoextraction of lead-contaminated soils. J Civ Eng 4: 409-416. |
| [21] | Pezzarossa B, Petruzzelli G (2001) Selenium contamination in soil: sorption and desorption processes, In: Selim, M.H., Sparks, D.L. Editors, Heavy metals release in soils, Boca Raton, CRC Press, 197-212. |
| [22] |
Wang Q, Li Z, Cheng S, et al. (2010) Effects of humic acids on phytoextraction of Cu and Cd from sediment by Elodea nuttallii. Chemosphere 78: 604-608. doi: 10.1016/j.chemosphere.2009.11.011
|
| [23] |
Evans LJ (1989) Chemistry of metal retention by soils. Environ Sci Technol, 23: 1046-1056. doi: 10.1021/es00067a001
|
| [24] |
Cherlatchka R, Cambier P (2000) Influence of reducing conditions on solubility of trace metals in contaminated soils. Water Air Soil Pollut 118: 143-167. doi: 10.1023/A:1005195920876
|
| [25] |
Fitz WJ, Wenzel WW (2002) Arsenic transformations in the soil-rhizosphere-plant system: fundamentals and potential application to phytoremediation. J Biotechnol 99: 259-278. doi: 10.1016/S0168-1656(02)00218-3
|
| [26] |
Alexander M (2000) Aging, bioavailability, and overestimation of risk from environmental pollutants. Environ Sci Technol 34: 4259-4265. doi: 10.1021/es001069+
|
| [27] | Harmsen JW, Rulkens W, Eijsakers H (2005) Bioavailability: concept for understanding or tool to predicting. Land Cont Recl 13: 161-171. |
| [28] | Petruzzelli G, Pedron F (2006) Bioavailability at heavy metal contaminated sites: a tool to select remediation strategies, In: Proceedings of the International conference on the remediation of polluted sites (BOSICON), Rome, Italy. 1-8. |
| [29] |
Harmsen J (2007) Measuring bioavailability: from a scientific approach to standard methods. J Environ Qual 36: 1420-1428. doi: 10.2134/jeq2006.0492
|
| [30] |
Semple KT, Doick KJ, Wick LY (2007) Microbial interactions with organic contaminants in soil: definitions, processes and measurement. Environ Pollut 150: 166-176. doi: 10.1016/j.envpol.2007.07.023
|
| [31] | USEPA (2008), Standard operating procedure for an in vitro bioaccessibility assay for lead in soil. EPA 9200, US Environmental Protection Agency. 1-86. |
| [32] |
Hu X, Zhang Y, Luo J, et al. (2011) Bioaccessibility and health risk of arsenic, mercury and other metals in urban street dusts from a mega-city, Nanjing, China. Environ Pollut 159: 1215-1221. doi: 10.1016/j.envpol.2011.01.037
|
| [33] |
Ruby MV, Davis A, Schoof R, et al. (1996) Estimation of lead and arsenic bioavailability using a physiologically based extraction test. Environ Sci Technol 30: 422-430. doi: 10.1021/es950057z
|
| [34] |
Rodriguez R, Basta N, Casteel SW, et al. (1999) An in vitro gastrointestinal method to estimate bioavailable arsenic in contaminated soils and solid media. Environ Sci Technol 33: 642-649. doi: 10.1021/es980631h
|
| [35] |
Oomen AG, Tolls J, Sips AJAM, et al. (2003) In vitro intestinal lead uptake and transport in relation to speciation. Arch Environ Contam Toxicol 44: 116-124. doi: 10.1007/s00244-002-1226-z
|
| [36] |
Drexler JW, Brattin WJ (2007) An in vitro procedure for estimation of lead relative bioavailability: with validation. Human Ecol Risk Assess 13: 383-401. doi: 10.1080/10807030701226350
|
| [37] |
Isikli B, Demir TA, Ürer SM, et al. (2003) Effects of chromium exposure from a cement factory. Environ Res 91: 113-118. doi: 10.1016/S0013-9351(02)00020-8
|
| [38] |
Schuhmacher M, Domingos JL, Garreta J (2004) Pollutants emitted by a cement plant: health risks for the population living in the neighbourhood. Environ Res 95: 198-206. doi: 10.1016/j.envres.2003.08.011
|
| [39] |
Schuhmacher M, Nadal M, Domingo JL (2009) Environmental monitoring of PCDD/Fs and metals in the vicinity of a cement plant after using sewage sludge as a secondary fuel. Chemosphere 74: 1502-1508. doi: 10.1016/j.chemosphere.2008.11.055
|
| [40] | Sparks DL (1996) Methods of Soil Analysis, Part 3-Chemical Method. Madison, USA: Soil Science Society of America Inc. |
| [41] |
Takáč P, Szabová T, Kozáková Ľ, et al. (2009) Heavy metals and their bioavailability from soils in the long-term polluted Central Spiš region of SR. Plant Soil Environ 55: 167-172. doi: 10.17221/21/2009-PSE
|
| [42] | Italian Government (2006) Official Gazette No. 88 of the Italian Republic of 14-04-2006. Ordinary Supplement No. 96 (in Italian). Istituto Poligrafico e Zecca dello Stato, Rome. |
| [43] |
Chandrasekaran A, Ravisankar R, Harikrishnan N, et al. (2015) Multivariate statistical analysis of heavy metal concentration in soils of Yelagiri Hills, Tamilnadu, India Spectroscopical approach. Spectrochim. Acta A. 137: 589-600. doi: 10.1016/j.saa.2014.08.093
|
| [44] |
Nolan AL, McLaughlin MJ, Mason SD (2003) Chemical speciation of Zn, Cd, Cu, and Pb in pore waters of agricultural and contaminated soils using Donnan dialysis. Environ Sci Technol 37: 90-98. doi: 10.1021/es025966k
|
| [45] |
Rasmussen PE, Beauchemin S, Nugent M, et al (2008) Influence of matrix composition on the bioaccessibility of copper, zinc, and nickel in urban residential dust and soil. Human Ecol Risk Assess 14: 351-371. doi: 10.1080/10807030801934960
|
| [46] |
Rieuwerts JS (2007) The mobility and bioavailability of trace metals in tropical soils: a review. Chem Spec Bioavail 19: 75-85. doi: 10.3184/095422907X211918
|
| [47] |
Ayoubi S, Jababri M, Khademi H (2018) Multiple linear modelling between soil properties, magnetic susceptibility and heavy metals in various land uses. Model Earth Syst Environ 4: 579-589. doi: 10.1007/s40808-018-0442-0
|
| [48] |
Zhao Z, Nie T, Yanga Z, et al. (2018) The role of soil components in the sorption of tetracycline and heavy metals in soils. RSC Adv 8: 32178-32187. doi: 10.1039/C8RA06631K
|
| [49] |
Siciliano SD, James K, Zhang GY., et al. (2009) Adhesion and enrichment of metals on human hands from contaminated soil at an Arctic urban brownfield. Environ Sci Technol 43: 6385-6390. doi: 10.1021/es901090w
|
| [50] |
Luo CL, Liu CP, Wang Y, et al. (2011) Heavy metal contamination in soils and vegetables near an e-waste processing site, south China. J Hazard Mater 186: 481-490. doi: 10.1016/j.jhazmat.2010.11.024
|
| [51] |
Ljung K, Oomen A, Duits M et al. (2007) Bioaccessibility of metals in urban playground soils. J Environ Sci Hlth A 42: 1241-1250. doi: 10.1080/10934520701435684
|
| [52] |
Caboche J, Denys S, Feidt C, et al. (2010) Modelling Pb bioaccessibility in soils contaminated by mining and smelting activities. J Environ Sci Hlth A 45: 1264-1274. doi: 10.1080/10934529.2010.493818
|
| [53] |
Pelfrêne C, Waterlot M, Mazzuca C, et al. (2011) Assessing Cd, Pb, Zn human bioaccessibility in smelter-contaminated agricultural topsoils (northern France). Environ Geochem Health 33: 477-493. doi: 10.1007/s10653-010-9365-z
|
| [54] | Baars AJ, Theelen RMC, Janssen PJ, et al. (2004) Re-evaluation of human-toxicological maximum permissibile risk levels. Bilthoven, The Netherlands: National Institute for Public Health and the Environment (RIVM), Report No. 711701025. |
| [55] |
Calabrese EJ, Stanek EJ, James RC, et al. (1997) Soil ingestion: A concern for acute toxicity in children. Environ Health Persp 105: 1354-1358. doi: 10.1289/ehp.971051354
|
| [56] |
Ferreri SJ, Tamm L, Wier KG (2006) Using food aversion to decrease severe pica by a child with autism. Behav Modif 30: 456-471. doi: 10.1177/0145445504272970
|
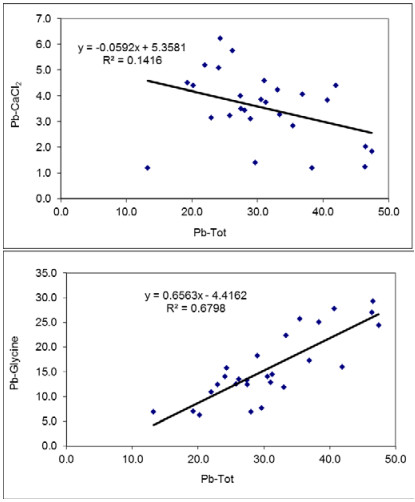
Figures(5) / Tables(2)

Gianniantonio Petruzzelli, Francesca Pedron, Irene Rosellini. Bioavailability and bioaccessibility in soil: a short review and a case study[J]. AIMS Environmental Science, 2020, 7(2): 208-225. doi: 10.3934/environsci.2020013







 DownLoad:
DownLoad: