Citation: Pingping Sun, Yongbing Chen, Bo Liu, Yanxin Gao, Ye Han, Fei He, Jinchao Ji. DeepMRMP: A new predictor for multiple types of RNA modification sites using deep learning[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 6231-6241. doi: 10.3934/mbe.2019310

| [1] | S. Dunin-Horkawicz, A. Czerwoniec, M. J. Gajda, et al., MODOMICS: A database of RNA modification pathways, Nucleic Acids Res., 34(2006), D145–D149. |
| [2] | J. H. Ge and Y. T. Yu, RNA pseudouridylation: New insights into an old modification, Trends Biochem. Sci., 38(2013), 210–218. 2. J. H. Ge and Y. T. Yu, RNA pseudouridylation: New insights into an old modification, Trends Biochem. Sci., 38(2013), 210–218. |
| [3] | M. Charette and M. W. Gray, Pseudouridine in RNA: what, where, how, and why, IUBMB Life, 49(2010), 341–351. 3. M. Charette and M. W. Gray, Pseudouridine in RNA: what, where, how, and why, IUBMB Life, 49(2010), 341–351. |
| [4] | D. R. Davis, C. A. Veltri, L. J. J. o. B. S. Nielsen, et al., An RNA model system for investigation of pseudouridine stabilization of the codon-anticodon interaction in tRNALys, tRNAHis and tRNATyr, J. Biomol. Struct. Dyn., 15(1998), 1121–1132. |
| [5] | A. Basak and C. Query, A pseudouridine residue in the spliceosome core is part of the filamentous growth program in yeast, Cell Reports, 8(2014), 966–973. |
| [6] | X. Yang, Y. Yang, B. F. Sun, et al., 5-methylcytosine promotes mRNA export-NSUN2 as the methyltransferase and ALYREF as an m5C reader, Cell Res., 27(2017), 606–625. |
| [7] | M. Frye and F. M. Watt, The RNA methyltransferase Misu (NSun2) mediates Myc-induced proliferation and is upregulated in tumors, Curr. Biol., 16(2006), 971–981. |
| [8] | X. Wang, Z. Lu, A. Gomez, et al., N6-methyladenosine-dependent regulation of messenger RNA stability, Nature, 505(2014), 117–120. |
| [9] | C. Roost, S. R. Lynch, P. J. Batista, et al., Structure and thermodynamics of N6-methyladenosine in RNA: A spring-loaded base modification, J. Am. Chem. Soc., 137(2015), 2107–2115. |
| [10] | T. Chen, Y. J. Hao, Y. Zhang, et al., m6A RNA methylation is regulated by micrornas and promotes reprogramming to pluripotency, Cell Stem Cell, 16(2015), 289–301. |
| [11] | S. Geula, S. Moshitch-Moshkovitz, D. Dominissini, et al., m6A mRNA methylation facilitates resolution of naive pluripotency toward differentiation, Science, 347(2015), 1002–1006. |
| [12] | X. Li, X. Xiong, K. Wang, et al., Transcriptome-wide mapping reveals reversible and dynamic N1-methyladenosine methylome, Nat. Chem. Biol., 12(2016), 311. |
| [13] | S. Nachtergaele and C. J. R. B. He, The emerging biology of RNA post-transcriptional modifications, RNA Biol., 14(2016), 156–163. |
| [14] | W. Chen, P. M. Feng, H. Tang, et al., RAMPred: Identifying the N-1-methyladenosine sites in eukaryotic transcriptomes, Sci. Rep., 6(2016), 31080. |
| [15] | W. Chen, H. Tang, J. Ye, et al., iRNA-PseU: Identifying RNA pseudouridine sites, Mol. Ther.-Nucl. Acids, 5(2016). |
| [16] | J. J. He, T. Fang, Z. Z. Zhang, et al., PseUI: Pseudouridine sites identification based on RNA sequence information, BMC Bioinform., 19(2018), 306. |
| [17] | W. R. Qiu, S. Y. Jiang, Z. C. Xu, et al., iRNAm5C-PseDNC: Identifying RNA 5-methylcytosine sites by incorporating physical-chemical properties into pseudo dinucleotide composition, Oncotarget, 8(2017), 41178–41188. |
| [18] | J. W. Li, Y. Huang, X. Y. Yang, et al., RNAm5Cfinder: A web-server for predicting RNA 5-methylcytosine (m5C) sites based on random forest, Sci. Rep., 8(2018). |
| [19] | P. M. Feng, H. Ding, H. Yang, et al., iRNA-PseColl: Identifying the occurrence sites of different RNA modifications by incorporating collective effects of nucleotides into PseKNC, Mol. Ther.-Nucl. Acids, 7(2017), 155–163. |
| [20] | W. Chen, P. M. Feng, H. Yang, et al., iRNA-3typeA: Identifying three types of modification at RNA's adenosine sites, Mol. Ther.-Nucl. Acids, 11(2018), 468–474. |
| [21] | Y. Huang, N. N. He, Y. Chen, et al., BERMP: A cross-species classifier for predicting m6A sites by integrating a deep learning algorithm and a random forest approach, Int. J. Biol. Sci., 14(2018), 1669–1677. |
| [22] | J. J. Xuan, W. J. Sun, P. H. Lin, et al., RMBase v2.0: Deciphering the map of RNA modifications from epitranscriptome sequencing data, Nucleic Acids Res., 46(2018), D327–D334. |
| [23] | D. Dominissini, S. Moshitch-Moshkovitz, S. Schwartz, et al., Topology of the human and mouse m6A RNA methylomes revealed by m6A-seq, Nature, 485(2012), U201–U284. |
| [24] | L. Fu, B. Niu, Z. Zhu, et al., CD-HIT: Accelerated for clustering the next-generation sequencing data, Bioinformatics, 28(2012), 3150–3152. |
| [25] | W. Z. Li and A. Godzik, Cd-hit: A fast program for clustering and comparing large sets of protein or nucleotide sequences, Bioinformatics, 22(2006), 1658–1659. |
| [26] | L. Zhu, H. B. Zhang and D. S. J. B. Huang, Direct AUC optimization of regulatory motifs, Bioinformatics, 33(2017), i243. |
| [27] | H. Zhang, L. Zhu and D. S. J. S. R. Huang, WSMD: Weakly-supervised motif discovery in transcription factor ChIP-seq data, Sci. Rep., 7(2017). |
| [28] | G. H. Chuai, H. H. Ma, J. F. Yan, et al., DeepCRISPR: Optimized CRISPR guide RNA design by deep learning, Genome Biol., 19(2018). |
| [29] | Q. Zhang, L. Zhu and D. S. Huang, High-order convolutional neural network architecture for predicting DNA-protein binding sites, IEEE/ACM Transact. Comput. Biol. Bioinform., (2018), 1. |
| [30] | Q. Zhang, L. Zhu, W. Bao, et al., Weakly-supervised convolutional neural network architecture for predicting protein-DNA binding, IEEE/ACM Transact. Comput. Biol. Bioinform., (2018), 1. |
| [31] | A. Krizhevsky, I. Sutskever and G. E. Hinton, ImageNet classification with deep convolutional neural networks, NIPS. Curran Assoc. Inc., (2012). |
| [32] | D. P. Kingma and J. J. C. S. Ba, Adam: A method for stochastic optimization, (2014). |
| [33] | C. Tan, F. Sun, K. Tao, et al., A survey on deep transfer learning, (2018). |
| [34] | G. Litjens, T. Kooi, B. E. Bejnordi, et al., A survey on deep learning in medical image analysis, Med. Image Anal., 42(2017), 60–88. |
| [35] | S. Liang, R. G. Zhang, D. Y. Liang, et al., Multimodal 3D denseNet for IDH genotype prediction in gliomas, Genes, 9(2018). |
| [36] | L. Zhu, W. L. Guo, C. Lu, et al., Collaborative completion of transcription factor binding profiles via local sensitive unified embedding, IEEE Transact. NanoBiosci., (2016), 1. |
| [37] | J. X. Wang, L. Chen, Y. Wang, et al., A computational systems biology study for understanding salt tolerance mechanism in rice, Plos One, 8(2013), 177–194. |

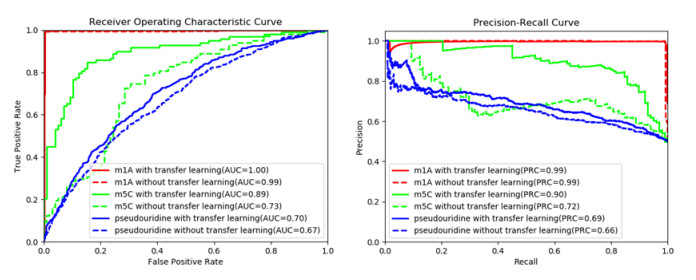
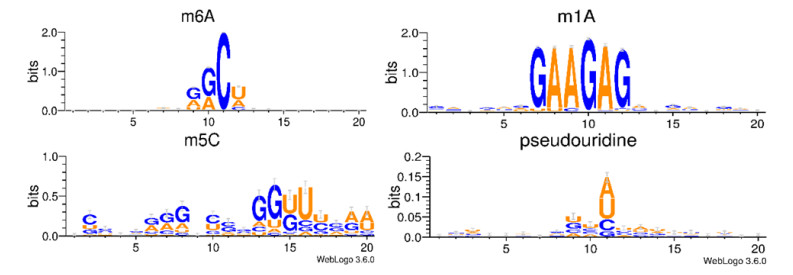
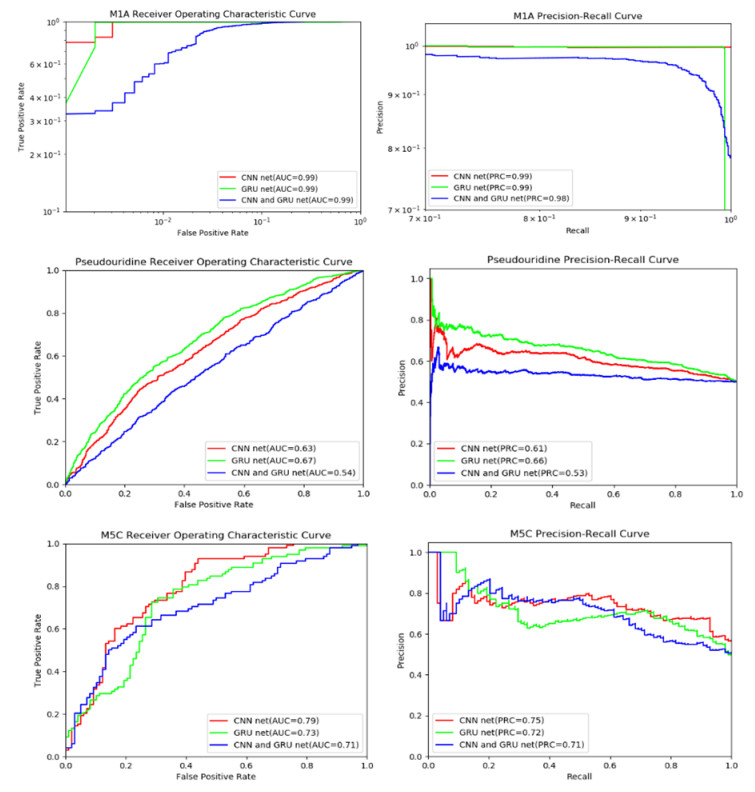
Figures(4) / Tables(3)

Pingping Sun, Yongbing Chen, Bo Liu, Yanxin Gao, Ye Han, Fei He, Jinchao Ji. DeepMRMP: A new predictor for multiple types of RNA modification sites using deep learning[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 6231-6241. doi: 10.3934/mbe.2019310







 DownLoad:
DownLoad: