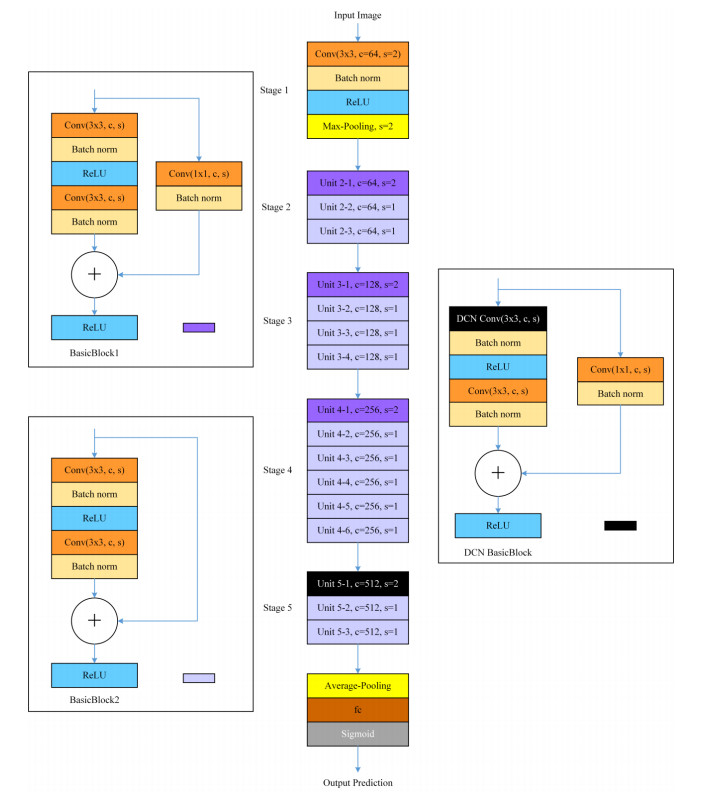
ResNet-based correlation models excel in age recognition algorithms, but specific age recognition research is currently limited and often plagued by substantial errors. We introduce an enhanced portrait age recognition algorithm based on ResNet, using CORAL (consistent rank logits) rank consistent ordered regression instead of traditional classification to predict precise ages. We further improve this approach by incorporating DCN (deformable convolution), resulting in the DCN-R model. DCN dynamically adjusts convolution kernels for diverse faces, improving accuracy and robustness. We tested DCN-R34 and DCN-R50 against the SOTA model, achieving better results with the same complexity. This reduces the computational load while maintaining or enhancing performance.
Citation: Ji Xi, Zhe Xu, Zihan Yan, Wenjie Liu, Yanting Liu. Portrait age recognition method based on improved ResNet and deformable convolution[J]. Electronic Research Archive, 2023, 31(11): 6585-6599. doi: 10.3934/era.2023333
ResNet-based correlation models excel in age recognition algorithms, but specific age recognition research is currently limited and often plagued by substantial errors. We introduce an enhanced portrait age recognition algorithm based on ResNet, using CORAL (consistent rank logits) rank consistent ordered regression instead of traditional classification to predict precise ages. We further improve this approach by incorporating DCN (deformable convolution), resulting in the DCN-R model. DCN dynamically adjusts convolution kernels for diverse faces, improving accuracy and robustness. We tested DCN-R34 and DCN-R50 against the SOTA model, achieving better results with the same complexity. This reduces the computational load while maintaining or enhancing performance.

| [1] |
Z. Huang, J. Zhang, H. Shan, When age-invariant face recognition meets face age synthesis: A multi-task learning framework and a new benchmark, IEEE Trans. Pattern Anal. Mach. Intell., 45 (2023), 7917–7932. https://doi.org/10.1109/TPAMI.2022.3217882 doi: 10.1109/TPAMI.2022.3217882

|
| [2] | A. M. Abu Nada, E. Alajrami, A. A. Al-Saqqa, S. Abu-Naser, Age and gender prediction and validation through single user images using CNN, Int. J. Acad. Eng. Res., 4 (2020), 21–24. |
| [3] | I. Rafique, A. Hamid, S. Naseer, M. Asad, M. Awais, T. Yasir, Age and gender prediction using deep convolutional neural networks, in 2019 International Conference on Innovative Computing (ICIC), 2019, 1–6. https://doi.org/10.1109/ICIC48496.2019.8966704. |
| [4] |
A. Othmani, A. R. Taleb, H. Abdelkawy, A. Hadid, Age estimation from faces using deep learning: A comparative analysis, Comput. Vision Image Understanding, 196 (2020). https://doi.org/10.1016/j.cviu.2020.102961 doi: 10.1016/j.cviu.2020.102961
|
| [5] |
N. Sharma, R. Sharma, N. Jindal, Face-based age and gender estimation using improved convolutional neural network approach, Wireless Pers. Commun., 124 (2022), 3035–3054. https://doi.org/10.1007/s11277-022-09501-8 doi: 10.1007/s11277-022-09501-8
|
| [6] |
A. Sakata, N. Takemura, Y. Yagi, Gait-based age estimation using multi-stage convolutional neural network, IPSJ Trans. Comput. Vision Appl., 4 (2019), 1–10. https://doi.org/10.1186/s41074-019-0054-2 doi: 10.1186/s41074-019-0054-2
|
| [7] |
C. Y. Hsu, L. E. Lin, C. H. Lin, Age and gender recognition with random occluded data augmentation on facial images, Multimedia Tools Appl., 80 (2021), 11631–11653. https://doi.org/10.1007/s11042-020-10141-y doi: 10.1007/s11042-020-10141-y
|
| [8] | B. B. Mamatkulovich, H. A. Alijon o'g'li, Facial image-based gender and age estimation, Eurasian Sci. Her., 18 (2023), 47–50. |
| [9] | L. Li, H. T. Lin, Ordinal regression by extended binary classification, Adv. Neural Inf. Process. Syst., 19 (2006). |
| [10] |
W. Cao, V. Mirjalili, S. Raschka, Rank consistent ordinal regression for neural networks with application to age estimation, Pattern Recognit. Lett., 140 (2020), 325–331. https://doi.org/10.1016/j.patrec.2020.11.008 doi: 10.1016/j.patrec.2020.11.008
|
| [11] | J. Paplham, V. Franc, Unraveling the age estimation puzzle: Comparative analysis of deep learning approaches for facial age estimation, arXiv preprint, (2023), arXiv: 2307.04570. https://doi.org/10.48550/arXiv.2307.04570 |
| [12] | J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, et al., Deformable convolutional networks, in Proceedings of the IEEE International Conference on Computer Vision, (2017), 764–773. |
| [13] | Z. Niu, M. Zhou, L. Wang, X. Gao, G. Hua, Ordinal regression with multiple output CNN for age estimation, in Proceedings of the IEEE conference on computer Vision and Pattern Recognition, (2016), 4920–4928. |










Figures(11) / Tables(4)
Ji Xi, Zhe Xu, Zihan Yan, Wenjie Liu, Yanting Liu. Portrait age recognition method based on improved ResNet and deformable convolution[J]. Electronic Research Archive, 2023, 31(11): 6585-6599. doi: 10.3934/era.2023333







 DownLoad:
DownLoad: