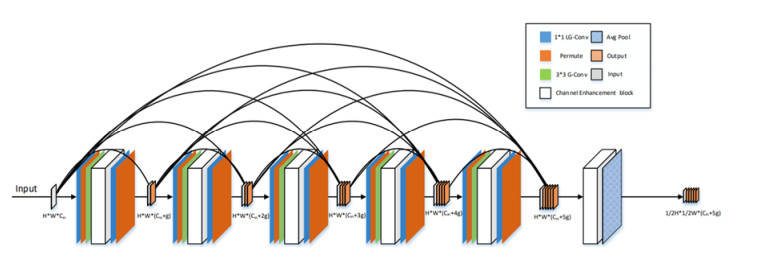
In recent years, deep convolutional neural network (CNN) has been applied more and more increasingly used in computer vision, natural language processing and other fields. At the same time, low-power platforms have more and more significant requirements for the size of the network. This paper proposed CED-Net (Channel enhancement DenseNet), a more efficient densely connected network. It combined the bottleneck layer with learned group convolution and channel enhancement module. The bottleneck layer with learned group convolution could effectively increase the network's accuracy without too many extra parameters and computation (FLOPs, Floating Point Operations). The channel enhancement module improved the representation of the network by increasing the interdependency between convolutional feature channels. CED-Net is designed regarding CondenseNet's structure, and our experiments show that the CED-Net is more effective than CondenseNet and other advanced lightweight CNNs. Accuracy on the CIFAR-10 dataset and CIFAR-100 dataset is 0.4 and 1% higher than that on CondenseNet, respectively, but they have almost the same number of parameters and FLOPs. Finally, the ablation experiment proves the effectiveness of the bottleneck layer used in CED-Net.
Citation: Xiangqun Li, Hu Chen, Dong Zheng, Xinzheng Xu. CED-Net: A more effective DenseNet model with channel enhancement[J]. Mathematical Biosciences and Engineering, 2022, 19(12): 12232-12246. doi: 10.3934/mbe.2022569
In recent years, deep convolutional neural network (CNN) has been applied more and more increasingly used in computer vision, natural language processing and other fields. At the same time, low-power platforms have more and more significant requirements for the size of the network. This paper proposed CED-Net (Channel enhancement DenseNet), a more efficient densely connected network. It combined the bottleneck layer with learned group convolution and channel enhancement module. The bottleneck layer with learned group convolution could effectively increase the network's accuracy without too many extra parameters and computation (FLOPs, Floating Point Operations). The channel enhancement module improved the representation of the network by increasing the interdependency between convolutional feature channels. CED-Net is designed regarding CondenseNet's structure, and our experiments show that the CED-Net is more effective than CondenseNet and other advanced lightweight CNNs. Accuracy on the CIFAR-10 dataset and CIFAR-100 dataset is 0.4 and 1% higher than that on CondenseNet, respectively, but they have almost the same number of parameters and FLOPs. Finally, the ablation experiment proves the effectiveness of the bottleneck layer used in CED-Net.

| [1] |
Y. Shao, J. C. W. Lin, G. Srivastava, A. Jolfaei, D. Guo, Y. Hu, Self-attention-based conditional random fields latent variables model for sequence labeling, Pattern Recognit. Lett., 145 (2021), 157–164. https://doi.org/10.1016/j.patrec.2021.02.008 doi: 10.1016/j.patrec.2021.02.008

|
| [2] |
J. C. W. Lin, Y. Shao, Y. Djenouri, U. Yun, ASRNN: A recurrent neural network with an attention model for sequence labeling, Knowl. Based Syst., 212 (2021), 106548. https://doi.org/10.1016/j.knosys.2020.106548 doi: 10.1016/j.knosys.2020.106548
|
| [3] |
Y. Djenouri, G. Srivastava, J. C. W. Lin, Fast and accurate convolution neural network for detecting manufacturing data, IEEE Trans. Ind. Inf., 17 (2021), 2947–2955. https://doi.org/10.1109/TII.2020.300149 doi: 10.1109/TII.2020.300149
|
| [4] |
Y. Shao, J. C. W. Lin, G. Srivastava, D. Guo, H. Zhang, H. Yi, et al., Multi-objective neural evolutionary algorithm for combinatorial optimization problems, IEEE Trans. Neural Networks Learn. Syst., 2021 (2021), 1–11. https://doi.org/10.1109/TNNLS.2021.3105937 doi: 10.1109/TNNLS.2021.3105937
|
| [5] | K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition, preprint, arXiv: 1409.1556. |
| [6] | C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, et al., Going deeper with convolutions, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2014), 1–9. https://doi.org/10.48550/arXiv.1409.4842 |
| [7] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2016), 770–778. https://doi.org/10.48550/arXiv.1512.03385 |
| [8] | S. Xie, R. Girshick, P. Dollár, Z. Tu, K. He, Aggregated residual transformations for deep neural networks, in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 5987–5995. https://doi.org/10.1109/CVPR.2017.634 |
| [9] | G. Huang, Z. Liu, L. van der Maaten, K. Q. Weinberger, Densely connected convolutional networks, in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 2261–2269. https://doi.org/10.1109/CVPR.2017.243 |
| [10] | J. Hu, L. Shen, G. Sun, Squeeze-and-Excitation networks, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2018), 7132–7141. https://doi.org/10.1109/CVPR.2018.00745 |
| [11] | B. Zoph, V. Vasudevan, J. Shlens, Q. V. Le, Learning transferable architectures for scalable image recognition, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2018), 8697–8710. https://doi.org/10.48550/arXiv.1707.07012 |
| [12] | C. Liu, B. Zoph, M. Neumann, J. Shlens, W. Hua, L. J. Li, et al., Progressive neural architecture search, in Proceedings of the European Conference on Computer Vision (ECCV), (2018), 19–34. https://doi.org/10.48550/arXiv.1712.00559 |
| [13] | E. Real, A. Aggarwal, Y. Huang, Q. V. Le, Regularized evolution for image classifier architecture search, in Proceedings of the AAAI Conference on Artificial Intelligence, 33 (2019), 4780–4789. https://doi.org/10.1609/aaai.v33i01.33014780 |
| [14] | A. Banitalebi-Dehkordi, Knowledge distillation for low-power object detection: A simple technique and its extensions for training compact models using unlabeled data, in 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), (2021), 769–778. https://doi.org/10.1109/ICCVW54120.2021.00091. |
| [15] | A. Goel, C. Tung, Y. H. Lu, G. K. Thiruvathukal, A Survey of methods for low-power deep learning and computer vision, in 2020 IEEE 6th World Forum on Internet of Things (WF-IoT), (2020), 1–6. https://doi.org/10.1109/WF-IoT48130.2020.9221198 |
| [16] | F. Chollet, Xception: Deep learning with depthwise separable convolutions, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2017), 1251–1258. https://doi.org/10.48550/arXiv.1610.02357 |
| [17] | A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, et al., Mobilenets: Efficient convolutional neural networks for mobile vision applications, preprint, arXiv: 170404861. |
| [18] | M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, L. C. Chen, Mobilenetv2: Inverted residuals and linear bottlenecks, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2018), 4510–4520. https://doi.org/10.48550/arXiv.1801.04381 |
| [19] | F. Zhang, Q. Li, Y. Ren, H. Xu, Y. Song, S. Liu, An expression recognition method on robots based on mobilenet V2-SSD, in 2019 6th International Conference on Systems and Informatics (ICSAI), IEEE, (2019), 118–122. https://doi.org/10.1109/ICSAI48974.2019.9010173 |
| [20] | X. Zhang, X. Zhou, M. Lin, J. Sun, Shufflenet: An extremely efficient convolutional neural network for mobile devices, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2018), 6848–6856. https://doi.org/10.1109/CVPR.2018.00716 |
| [21] | N. Ma, X. Zhang, H. T. Zheng, J. Sun, Shufflenet v2: Practical guidelines for efficient CNN architecture design, in Proceedings of the European Conference on Computer Vision (ECCV), (2018), 116–131. https://doi.org/10.48550/arXiv.1807.11164 |
| [22] | G. Huang, S. Liu, L. Van der Maaten, K. Q. Weinberger, Condensenet: An efficient densenet using learned group convolutions, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2018), 2752–2761. https://doi.org/10.48550/arXiv.1807.11164 |
| [23] |
R. Zhang, F. Zhu, J. Liu, G. Liu, Depth-wise separable convolutions and multi-level pooling for an efficient spatial CNN-based steganalysis, IEEE Trans. Inf. Forensics Secur., 15 (2020), 1138–1150. https://doi.org/10.1109/TIFS.2019.2936913. doi: 10.1109/TIFS.2019.2936913
|
| [24] | S. Han, H. Mao, W. J. Dally, Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding, preprint, arXiv: 151000149. |
| [25] | H. Lin, A. Kadav, I. Durdanovic, H. Samet, H. P. Graf, Pruning filters for efficient convnets, preprint, arXiv: 1608.08710. |
| [26] | Z. Liu, J. Li, Z. Shen, G. Huang, S. Yan, C. Zhang, Learning efficient convolutional networks through network slimming, in Proceedings of the IEEE International Conference on Computer Vision, (2017), 2736–2744. https://doi.org/10.48550/arXiv.1708.06519 |
| [27] | Y. He, P. Liu, Z. Wang, Z. Hu, Y. Yang, Filter pruning via geometric median for deep convolutional neural networks acceleration, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2019), 4340–4349. https://doi.org/10.48550/arXiv.1811.00250 |
| [28] | M. Rastegari, V. Ordonez, J. Redmon, A. Farhadi, Xnor-net: ImageNet classification using binary convolutional neural networks, in European Conference on Computer Vision, (2016), 525–542. https://doi.org/10.1007/978-3-319-46493-0_32 |
| [29] | Y. Jiao, S. Li, X. Huo, Y. K. Li, Synchronous weight quantization-compression for low-bit quantized neural network, in 2021 International Joint Conference on Neural Networks (IJCNN), IEEE, (2021), 1–8. https://doi.org/10.1109/IJCNN52387.2021.9533393 |
| [30] | H. Mao, S. Han, J. Pool, W. Li, X. Liu, Y. Wang, et al., Exploring the regularity of sparse structure in convolutional neural networks, preprint, arXiv: 170508922. |
| [31] | W. Yin, G. Dong, Y. Zhao, R. Li, Coresets application in channel pruning for fast neural network slimming, in 2021 International Joint Conference on Neural Networks (IJCNN), (2021), 1–8. https://doi.org/10.1109/IJCNN52387.2021.9533343 |




Figures(5) / Tables(5)

Xiangqun Li, Hu Chen, Dong Zheng, Xinzheng Xu. CED-Net: A more effective DenseNet model with channel enhancement[J]. Mathematical Biosciences and Engineering, 2022, 19(12): 12232-12246. doi: 10.3934/mbe.2022569







 DownLoad:
DownLoad: