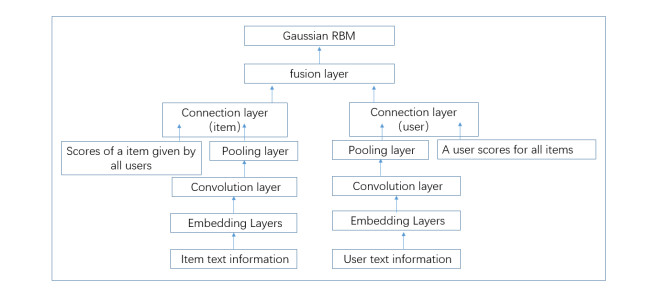
With the unprecedented development of big data, it is becoming hard to get the valuable information hence, the recommendation system is becoming more and more popular. When the limited Boltzmann machine is used for collaborative filtering, only the scoring matrix is considered, and the influence of the item content, the user characteristics and the user evaluation content on the predicted score is not considered. To solve this problem, the modified hybrid recommendation algorithm based on Gaussian restricted Boltzmann machine is proposed in the paper. The user text information and the item text information are input to the embedding layer to change the text information into numerical vector. The convolutional neural network is used to get the latent feature vector of the text information. The latent vector is connected to rating vector to get the item and the user vector. The user vector and the item vector are fused together to get the user-item matrix which is input to the visual layer of Gaussian restricted Boltzmann Machine to predict the ratings. Some simulation experiments have been performed on the algorithm, and the results of the experiments proved that the algorithm is feasible.
Citation: Jue Wu, Lei Yang, Fujun Yang, Peihong Zhang, Keqiang Bai. Hybrid recommendation algorithm based on real-valued RBM and CNN[J]. Mathematical Biosciences and Engineering, 2022, 19(10): 10673-10686. doi: 10.3934/mbe.2022499
With the unprecedented development of big data, it is becoming hard to get the valuable information hence, the recommendation system is becoming more and more popular. When the limited Boltzmann machine is used for collaborative filtering, only the scoring matrix is considered, and the influence of the item content, the user characteristics and the user evaluation content on the predicted score is not considered. To solve this problem, the modified hybrid recommendation algorithm based on Gaussian restricted Boltzmann machine is proposed in the paper. The user text information and the item text information are input to the embedding layer to change the text information into numerical vector. The convolutional neural network is used to get the latent feature vector of the text information. The latent vector is connected to rating vector to get the item and the user vector. The user vector and the item vector are fused together to get the user-item matrix which is input to the visual layer of Gaussian restricted Boltzmann Machine to predict the ratings. Some simulation experiments have been performed on the algorithm, and the results of the experiments proved that the algorithm is feasible.

| [1] |
L. Qi, C. H. Hu, X. Y. Zhang, M. R. Khosravi, S. Sharma, S. N. Pang, et al., Privacy-aware data fusion and prediction with spatial-temporal context for smart city industrial environment, IEEE Trans. Ind. Inf., 17 (2021), 4159–4167. https://doi.10.1109/TII.2020.3012157 doi: 10.1109/TII.2020.3012157

|
| [2] |
Y. Tian, R. Zheng, Z. Liang, S. Li, F. X. Wu, M. Li, A data-driven clustering recommendation method for single-cell RNA-sequencing data, Tsinghua Sci. Technol., 26 (2021), 772–789. https://doi.10.26599/TST.2020.9010028 doi: 10.26599/TST.2020.9010028
|
| [3] |
L. Shen, Q. Liu, G. Chen, S. Ji, Text-based price recommendation system for online rental houses, Big Data Min. Anal., 3 (2020), 143–152. https://doi.10.26599/BDMA.2019.9020023 doi: 10.26599/BDMA.2019.9020023
|
| [4] | L. Qi, W. Lin, X. Zhang, W. Dou, X. Xu, J. Chen, A correlation graph based approach for personalized and compatible Web APIs recommendation in mobile APP development, IEEE Trans. Knowl. Data Eng., 2022 (2022). https://doi.10.1109/TKDE.2022.3168611 |
| [5] |
P. Nitu, J. Coelho, P. Madiraju, Improvising personalized travel recommendation system with recency effects, Big Data Min. Anal., 4 (2021), 139–154. https://doi.10.26599/BDMA.2020.9020026 doi: 10.26599/BDMA.2020.9020026
|
| [6] |
T. Li, C. Li, J. Luo, L. Song, Wireless recommendations for Internet of vehicles: Recent advances, challenges, and opportunities, Intell. Converged Networks, 1 (2020), 1–17. https://doi.10.23919/ICN.2020.0005 doi: 10.23919/ICN.2020.0005
|
| [7] | Z. Y. Ji, M. D. Wu, H. Yang, J. E. A. Í ñ igo, Temporal sensitive heterogeneous graph neural network for news recommendation, Future Gener. Comput. Syst., 125 (2021), 324–333. https://doi.10.1016/j.future.2021.06.007 |
| [8] |
A. H. Nabizadeh, J. P. Leal, H. N. Rafsanjani, R. R. Shah, Learning path personalization and recommendation methods: A survey of the state-of-the-art, Expert Syst. Appl., 159 (2020), 1–20. https://doi.10.1016/j.eswa.2020.113596 doi: 10.1016/j.eswa.2020.113596
|
| [9] | C. F. Xu, J. Feng, P. P. Zhao, F. Z. Zhuang, D. Wang, Y. Liu, et al., Long-and short-term self-attention network for sequential recommendation, Neurocomputing, 423 (2021), 580–589. https://Doi.10.1016/j.neucom.2020.10.066 |
| [10] |
J. Zhang, B. Qin, Y. F. Zhang, J. H. Zhou, H. W. Wang, A knowledge extraction framework for domain-specific application with simplified pre-trained language model and attention-based feature extractor, Serv. Oriented Comput. Appl., 16 (2022), 121–131. https://doi.10.1007/s11761-022-00337-5 doi: 10.1007/s11761-022-00337-5
|
| [11] | G. Hinton, A practical guide to training restricted Boltzmann machines, Momentum, 9 (2010), 926–947. |
| [12] |
C. Wang, Q. M. Li, Research on hybrid recommendation algorithm based on restricted Boltzmann machine and term frequency-inverse document frequency, J. Nanjing Univ. Sci. Technol., 45 (2021), 551–557. https://doi.10.14177/j.cnki.32-1397n.2021.45.05.005 doi: 10.14177/j.cnki.32-1397n.2021.45.05.005
|
| [13] |
C. H. Hu, X. Q. Tong, W. Liang, The real-valued restricted Boltzmann machine recommendation algorithm based on trust-distrust relationship, Syst. Eng. Theory Pract., 39 (2019), 1817–1830. https://doi.10.12011/1000-6788-2018-2504-14 doi: 10.12011/1000-6788-2018-2504-14
|
| [14] |
W. B. Wang, L. C. Zhang, Q. Xu, A recommendation algorithm based on restricted Boltzmann machine, J. Harbin Univ. Sci. Technol., 25 (2020), 62–67. https://doi.10.15938/j.jhust.2020.05.009 doi: 10.15938/j.jhust.2020.05.009
|
| [15] |
D. P. He, W. Y. Zhang, H. Huang, A hybrid recommendation algorithm based on multi-source information clustering and IRC-RBM, Comput. Eng. Sci., 42 (2020), 1089–1095. https://doi.10.3969/j.issn.1007-130X.2020.06.107 doi: 10.3969/j.issn.1007-130X.2020.06.107
|
| [16] | L. L. Pei, An improved real UI-RBM collaborative filtering recommendation algorithm, Ph.D thesis, Lan Zhou University, 2016. |
| [17] | K. Georiev, P. Nakov, A non-IID framework for collaborative filtering with restricted Boltzmann machine, in Proceedings of the 30th International Conference on Machine Learning, (2013), 1148–1156. |
| [18] |
Y. Xue, Y. K. Wang, J. Y. Liang, A. Slowik, A self-adaptive mutation neural architecture search algorithm based on blocks, IEEE Comput. Intell. Mag., 16 (2021), 67–78. https://doi.10.1109/MCI.2021.3084435 doi: 10.1109/MCI.2021.3084435
|
| [19] |
Y. Xue, P. Jiang, F. Neri, A multiobjective evolutionary approach based on graph-in-graph for neural architecture search of convolutional neural networks, Int. J. Neural Syst., 31 (2021), 1–17. https://doi.10.1142/S0129065721500350 doi: 10.1142/S0129065721500350
|
| [20] |
D. O'Neill, B. Xue, M. Zhang, Evolutionary neural architecture search for high-dimensional skip-connection structures on densenet style networks, IEEE Trans. Evol. Comput., 25 (2021), 1118–1132. https://doi.10.1109/TEVC.2021.3083315 doi: 10.1109/TEVC.2021.3083315
|
| [21] |
B. Jang, M. Kim, G. Harerimana, S. Kang, J. W. Kim, Bi-LSTM model to increase accuracy in text classification: Combining Word2vec CNN and attention mechanism, Appl. Sci., 10 (2020), 1–14. https://doi.10.3390/app10175841 doi: 10.3390/app10175841
|
| [22] |
S. H. Yu, D. L. Liu, W. F. Zhu, Y. Zhang, S. M. Zhao, Attention-based LSTM, GRU and CNN for short text classification, J. Intell. Fuzzy Syst., 39 (2020), 333–340. https://doi.10.3390/app10175841 doi: 10.3390/app10175841
|
| [23] |
F. Xu, J. Luo, M. W. Wang, G. D. Zhou, Speech-driven end-to-end language discrimination toward chinese dialects, ACM Trans. Asian Low Resour. Lang. Inf. Process., 19 (2020), 1–23. https://doi.10.1145/3389021 doi: 10.1145/3389021
|
| [24] |
Y. S. Zhao, Y. X. Duan, Convolutional neural networks text classification model based on attention mechanism, J. Appl. Sci., 37 (2019), 541–550. https://doi.10.3969/j.issn.0255-8297.2019.04.011 doi: 10.3969/j.issn.0255-8297.2019.04.011
|
| [25] | G. Kim, I. Choi, Q. L. Li, J. Kim, A CNN-Based Advertisement recommendation through real-time user face recognition, Applied Sci., 11 (2021). https://doi.10.3390/app11209705 |
| [26] |
Y. J. Yan, G. Yu, X. B. Yan, Online doctor recommendation with convolutional neural network and sparse inputs, Comput. Intell. Neurosci., 2020 (2020), 1–10. https://doi.10.1155/2020/8826557 doi: 10.1155/2020/8826557
|
| [27] |
Z. F. Liao, H. Y. Yang, T. H. Song, S. Yu, X. F. Qi, Developer project recommendation model based on CNN-LSTM in GitHub, Acta Electron. Sin., 48 (2020), 2202–2207. https://doi.10.3969/j.issn.0372-2112.2020.11.015 doi: 10.3969/j.issn.0372-2112.2020.11.015
|
| [28] |
K. Saraswathi, V. Mohanraj, Y. Sruesh, J. Senthilkumar, A hybrid multi-feature semantic similarity based online social recommendation system using CNN, Int. J. Uncertainty Fuzziness Knowl. Based Syst., 29 (2021), 333–352. https://doi.10.1142/S0218488521400183 doi: 10.1142/S0218488521400183
|
| [29] |
X. L. Shen, C. H. He, X. F. Meng, Research on hybrid recommendation algorithm of restricted Boltzmann machine and weighted Slope One, Appl. Res. Comput., 37 (2020), 684–687. https://doi.10.19734/j.issn.1001-3695.2018.08.0619 doi: 10.19734/j.issn.1001-3695.2018.08.0619
|
| [30] |
D. Q. Du, F. Zhou, Hybrid collaborative filtering algorithm based on TimeRBM and item attribute clustering, Appl. Res. Comput., 35 (2018), 239–353. https://doi.10.3969/j.issn.1001-3695.2018.02.007 doi: 10.3969/j.issn.1001-3695.2018.02.007
|
| [31] |
R. J. Kuo, J. T. Chen, An application of differential evolution algorithm-based restricted Boltzmann machine to recommendation systems, J. Int. Technol., 21 (2020), 701–712. https://doi.10.3966/160792642020052103008 doi: 10.3966/160792642020052103008
|
| [32] |
Y. P. Du, C. Q. Yao, S. H. Huo, J. X. Liu, A new item-based deep network structure using a restricted Boltzmann machine for collaborative filtering, Front. Inf. Technol. Electron. Eng., 18 (2018), 658–666. https://doi.10.1631/FITEE.1601732 doi: 10.1631/FITEE.1601732
|
| [33] | F. He, N. Li, Z. G. Zhang, Recommendation algorithm based on restricted Boltzmann machine and item type, in Proceedings of the 2018 3rd International Conference on Automation, Mechanical Control and Computational Engineering (AMCCE 2018), (2018), 238–244. https://dx.doi.org/10.2991/amcce-18.2018.42 |
| [34] |
Z. X. Chen, W. Q. Ma, W. Dai, W. K. Pan, Z. Ming, Conditional restricted Boltzmann machine for item recommendation, Neurocomputing, 385 (2020), 269–277. https://doi.10.1016/j.neucom.2019.12.088 doi: 10.1016/j.neucom.2019.12.088
|
| [35] |
J. Y. He, B. Ma, Based on real-valued conditional restricted Boltzmann machine and social network for collaborative filtering, Chin. J. Comput., 39 (2016), 183–195. https://doi.10.11897/SP.J.1016.2016.00183 doi: 10.11897/SP.J.1016.2016.00183
|




Figures(5) / Tables(2)

Jue Wu, Lei Yang, Fujun Yang, Peihong Zhang, Keqiang Bai. Hybrid recommendation algorithm based on real-valued RBM and CNN[J]. Mathematical Biosciences and Engineering, 2022, 19(10): 10673-10686. doi: 10.3934/mbe.2022499







 DownLoad:
DownLoad: