Citation: Yuanyuan Ma, Jinwei Wang, Xiangyang Luo, Zhenyu Li, Chunfang Yang, Jun Chen. Image steganalysis feature selection based on the improved Fisher criterion[J]. Mathematical Biosciences and Engineering, 2020, 17(2): 1355-1371. doi: 10.3934/mbe.2020068

| [1] | J. Wang, T. Li, X. Luo, et al., Identifying computer generated images based on quaternion central moments in color quaternion wavelet domain, IEEE Trans. Circuits Syst. Video Technol., 29 (2019), 2775-2785. |
| [2] | Z. Zhou, Y. Mu and Q. M. J. Wu, Coverless image steganography using partial-duplicate image retrieval, Soft Comput., 23 (2019), 4927-4938. |
| [3] | J. Fridrich, Feature-based steganalysis for JPEG images and its implications for future design of steganographic schemes, International Workshop on Information Hiding, Springer, Berlin, Heidelberg, 2004, 67-81. Available from: https://linkspringer.xilesou.top/chapter/10.1007/978-3-540-30114-16. |
| [4] | Y. Zhang, D. Ye, J. Gan, et al., An image steganography algorithm based on quantization index modulation resisting scaling attacksand statistical detection, Comput. Mater. Continua, 56 (2018), 151-167. |
| [5] | Z. Qu, T. Zhu, J. Wang, et al., A Novel Quantum Stegonagraphy Based on Brown States, Comput. Mater. Continua, 56 (2018), 47-59. |
| [6] | C. Qin, X. Chen, X. Luo, et. al., Perceptual image hashing via dual-cross pattern encoding and salient structure detection, Inf. Sci., 423 (2018), 284-302. |
| [7] | A. Cheddad, J. Condell, K. Curran, et. al., Digital image steganography: Survey and analysis of current methods, Signal Process., 90 (2010), 727-752. |
| [8] | Y. Zhang, C. Qin, W. Zhang, et.al., On the fault-tolerant performance for a class of robust image steganography, Signal Process., 146 (2018), 99-111. |
| [9] | Y. Kang, F. Liu, C. Yang, et al., Color Image Steganalysis Based on Residuals of Channel Differences, Comput. Mater. Continua, 59 (2019), 315-329. |
| [10] | Y. Zhang, X. Luo, Y. Guo, et al., Multiple Robustness Enhancements for Image Adaptive Steganography in Lossy Channels, IEEE Trans. Circuits Syst. Video Technol., 2019 (2019). |
| [11] | Y. Yeung, W. Lu, Y. Xue, et al., Secure Binary Image Steganography with Distortion Measurement Based on Prediction, IEEE Trans. Circuits Syst. Video Technol., 2019 (2019). |
| [12] | V. Holub, J. Fridrich and T. Denemark, Universal distortion function for steganography in an arbitrary domain, EURASIP J. Inf. Secur., 1 (2014), 1-13. |
| [13] | V. Sachnev and H. J. Kim, Binary coded genetic algorithm with ensemble classifier for feature selection in JPEG steganalysis, 2014 IEEE Ninth International Conference on Intelligent Sensors, Sensor Networks and Information Processing (ISSNIP), 2014, 21-24. Available from: https://ieeexploreieee.xilesou.top/abstract/document/6827700. |
| [14] | R. R. Chhikara, P. Sharma and L. Singh, A hybrid feature selection approach based on improved PSO and filter approaches for image steganalysis, Int. J. Mach. Learn. Cybern., 7 (2016), 1195-1206. |
| [15] | J. Kodovsky and J. Fridrich, Steganalysis of JPEG images using rich models, Proceedings Volume 8303, Media Watermarking, Security, and Forensics, California, 2012, 23-25. Available from: https://www.spiedigitallibrary.org/conference-proceedings-of-spie/8303/83030A/Steganalysis-ofJPEG-images-using-rich-models/10.1117/12.907495.short. |
| [16] | Steganalysis in high dimensions: Fusing classifiers built on random subspaces, Media Watermarking, Security, and Forensics III. International Society for Optics and Photonics, California, 2011, 23-26. Available from: https://www.spiedigitallibrary.org/conferenceproceedings-of-spie/7880/78800L/Steganalysis-in-high-dimensions-fusing-classifiers-built-onrandom/10.1117/12.872279.short?SSO=1. |
| [17] | J. Qin, X. Sun, X. Xiang, et al., Principal feature selection and fusion method for image steganalysis, J. Electron. Imaging, 18 (2009), 033009. |
| [18] | E. Oja, Principal components. and minor components. and linear neural networks, Neural Networks, 5 (1992), 927-935. |
| [19] | X. Luo, F. Liu, S. Lian, et al., On the typical statistic features for image blind steganalysis, IEEE J. Sel. Area. Comm., 29 (2011), 1404-1422. |
| [20] | Z. Li and A. G. Bors, Selection of robust features for the cover source mismatch problem in 3D steganalysis, 2016 23rd International Conference on Pattern Recognition (ICPR), IEEE, 2016 4256-4261. Available from: https://ieeexploreieee.xilesou.top/abstract/document/7900302. |
| [21] | Y. Ma, X. Luo, X. Li, et al., Selection of rich model steganalysis features based on decision rough set α-positive region reduction, IEEE Trans. Circuits Syst. Video Technol., 29 (2019), 336-350. |
| [22] | J. Lu, F. Liu and X. Luo, Selection of image features for steganalysis based on the Fisher criterion, Digit. Invest., 11, (2014), 57-66. |
| [23] | X. Song, F. Liu, C. Yang, et al., Steganalysis of adaptive JPEG steganography using 2D Gabor filters, Proceedings of the 3rd ACM Workshop on Information Hiding and Multimedia Security, 2015, 15-23. Available from: https://dlacm.xilesou.top/citation.cfm?id=2756608. |
| [24] | T. Pevny and J. Fridrich, Merging Markov and DCT features for multiclass JPEG steganalysis, Electronic Imaging, Security, Steganography, and Watermarking of Multimedia Contents IX, International Society for Optics and Photonics, 2007. Available from: https://www.spiedigitallibrary.org/conference-proceedings-of-spie/6505/650503/MergingMarkov-and-DCT-features-for-multi-class-JPEG-steganalysis/10.1117/12.696774.short?SSO=1. |
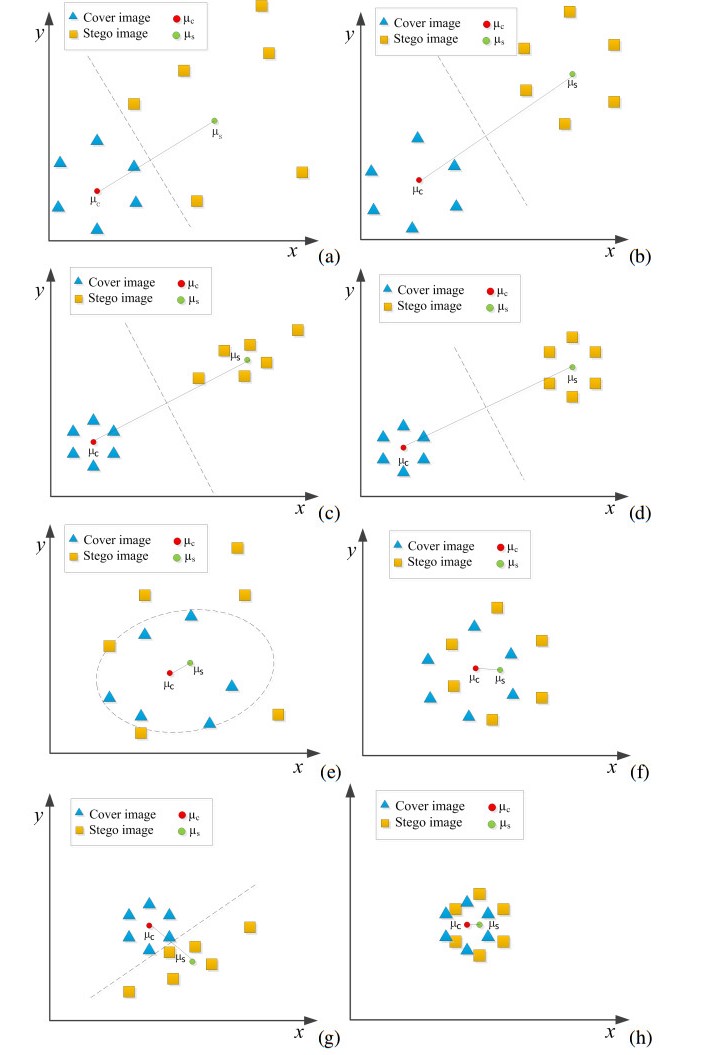
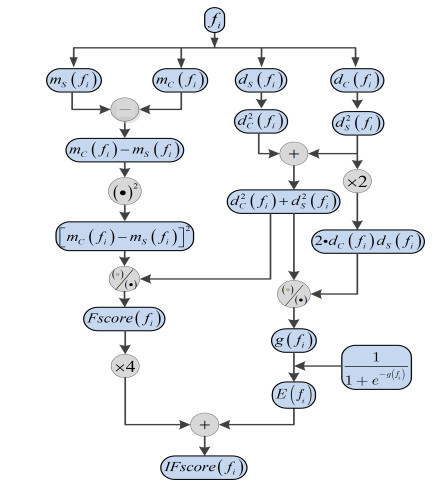
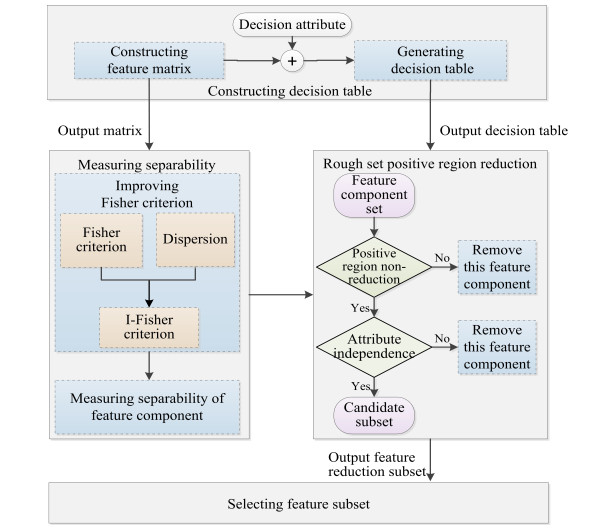
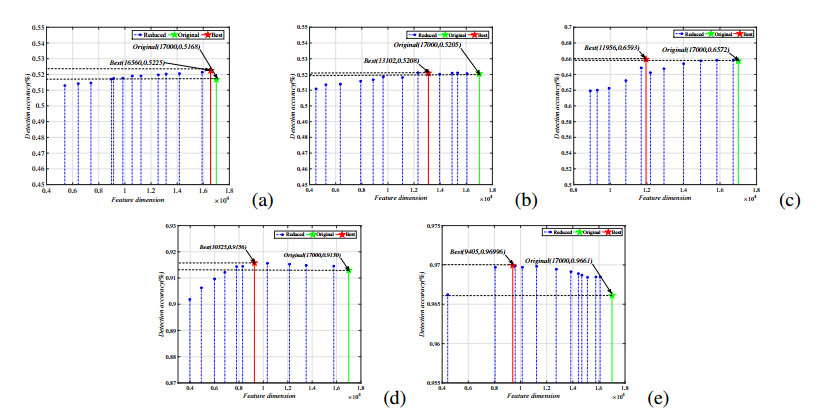
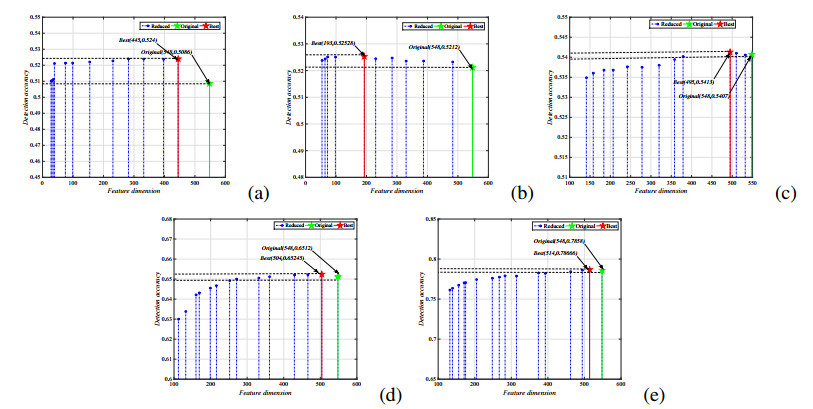
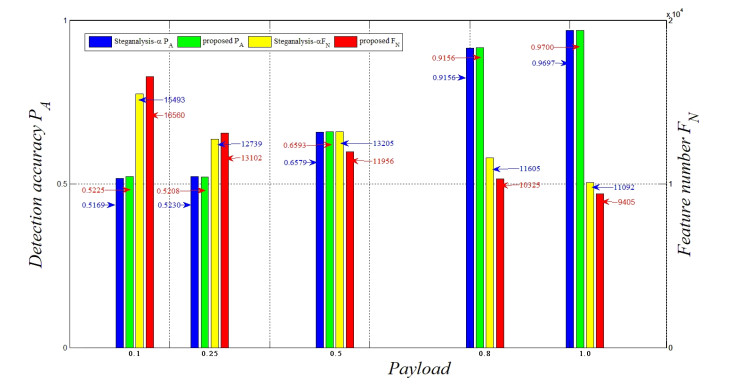
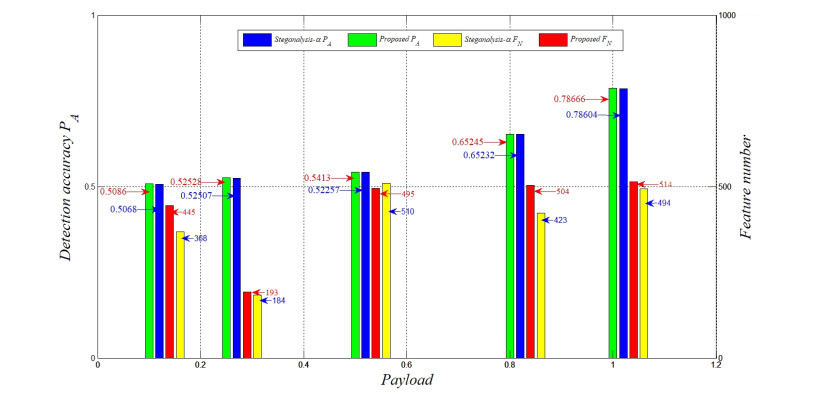
Figures(7) / Tables(3)

Yuanyuan Ma, Jinwei Wang, Xiangyang Luo, Zhenyu Li, Chunfang Yang, Jun Chen. Image steganalysis feature selection based on the improved Fisher criterion[J]. Mathematical Biosciences and Engineering, 2020, 17(2): 1355-1371. doi: 10.3934/mbe.2020068







 DownLoad:
DownLoad: