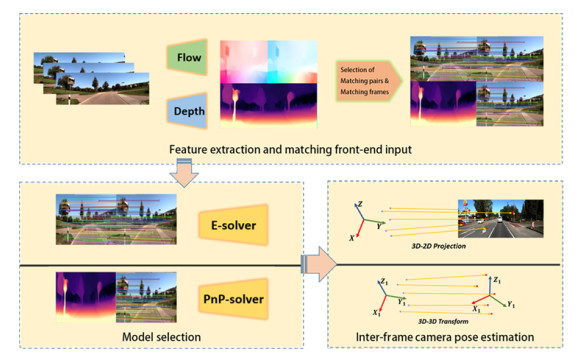
For the autonomous and intelligent operation of robots in unknown environments, simultaneous localization and mapping (SLAM) is essential. Since the proposal of visual odometry, the use of visual odometry in the mapping process has greatly advanced the development of pure visual SLAM techniques. However, the main challenges in current monocular odometry algorithms are the poor generalization of traditional methods and the low interpretability of deep learning-based methods. This paper presented a hybrid self-supervised visual monocular odometry framework that combined geometric principles and multi-frame temporal information. Moreover, a post-odometry optimization module was proposed. By using image synthesis techniques to insert synthetic views between the two frames undergoing pose estimation, more accurate inter-frame pose estimation was achieved. Compared to other public monocular algorithms, the proposed approach showed reduced average errors in various scene sequences, with a translation error of $ 2.211\% $ and a rotation error of $ 0.418\; ^{\circ}/100m $. With the help of the proposed optimizer, the precision of the odometry algorithm was further improved, with a relative decrease of approximately 10$ \% $ intranslation error and 15$ \% $ in rotation error.
Citation: Shuangjie Yuan, Jun Zhang, Yujia Lin, Lu Yang. Hybrid self-supervised monocular visual odometry system based on spatio-temporal features[J]. Electronic Research Archive, 2024, 32(5): 3543-3568. doi: 10.3934/era.2024163
For the autonomous and intelligent operation of robots in unknown environments, simultaneous localization and mapping (SLAM) is essential. Since the proposal of visual odometry, the use of visual odometry in the mapping process has greatly advanced the development of pure visual SLAM techniques. However, the main challenges in current monocular odometry algorithms are the poor generalization of traditional methods and the low interpretability of deep learning-based methods. This paper presented a hybrid self-supervised visual monocular odometry framework that combined geometric principles and multi-frame temporal information. Moreover, a post-odometry optimization module was proposed. By using image synthesis techniques to insert synthetic views between the two frames undergoing pose estimation, more accurate inter-frame pose estimation was achieved. Compared to other public monocular algorithms, the proposed approach showed reduced average errors in various scene sequences, with a translation error of $ 2.211\% $ and a rotation error of $ 0.418\; ^{\circ}/100m $. With the help of the proposed optimizer, the precision of the odometry algorithm was further improved, with a relative decrease of approximately 10$ \% $ intranslation error and 15$ \% $ in rotation error.

| [1] |
J. J. Leonard, H. F. Durrant-Whyte, Mobile robot localization by tracking geometric beacons, IEEE Trans. Rob. Autom., 7 (1991), 376–382. https://doi.org/10.1109/70.88147 doi: 10.1109/70.88147

|
| [2] | J. Liu, M. Zeng, Y. Wang, W. Liu, Visual SLAM technology based on weakly supervised semantic segmentation in dynamic environment, in International Symposium on Artificial Intelligence and Robotics 2020, 11574 (2020). https://doi.org/10.1117/12.2580074 |
| [3] |
J. Fuentes-Pacheco, J. Ruiz-Ascencio, J. M. Rendon-Mancha, Visual simultaneous localization and mapping: A survey, Artif. Intell. Rev., 43 (2015), 55–81. https://doi.org/10.1007/s10462-012-9365-8 doi: 10.1007/s10462-012-9365-8
|
| [4] |
A. Li, J. Wang, M. Xu, Z. Chen, DP-SLAM: A visual SLAM with moving probability towards dynamic environments, Inf. Sci., 556 (2021), 128–142. https://doi.org/10.1016/j.ins.2020.12.019 doi: 10.1016/j.ins.2020.12.019
|
| [5] | A. Geiger, P. Lenz, R. Urtasun, Are we ready for autonomous driving? The KITTI vision benchmark suite, in 2012 IEEE Conference on Computer Vision and Pattern Recognition, (2012), 3354–3361. https://doi.org/10.1109/CVPR.2012.6248074 |
| [6] |
C. Zach, T. Pock, H. Bischof, A duality based approach for realtime $TV-L^1$ optical flow, Pattern Recognit., 4713 (2007), 214–223. https://doi.org/10.1007/978-3-540-74936-3_22 doi: 10.1007/978-3-540-74936-3_22
|
| [7] |
D. G. Lowe, Distinctive image features from scale-invariant keypoints, Int. J. Comput. Vision, 60 (2004), 91–110. https://doi.org/10.1023/B:VISI.0000029664.99615.94 doi: 10.1023/B:VISI.0000029664.99615.94
|
| [8] | H. Bay, T. Tuytelaars, L. Van Gool, SURF: Speeded up robust features, in Computer Vision-ECCV 2006, 3951 (2006), 404–417. https://doi.org/10.1007/11744023_32 |
| [9] | E. Rublee, V. Rabaud, K. Konolige, G. Bradski, ORB: An efficient alternative to SIFT or SURF, in 2011 International Conference on Computer Vision, (2011), 2564–2571. https://doi.org/10.1109/ICCV.2011.6126544 |
| [10] | G. Klein, D. Murray, Parallel tracking and mapping for small AR workspaces, in 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, (2007), 225–234. https://doi.org/10.1109/ISMAR.2007.4538852 |
| [11] | J. Engel, T. Schoeps, D. Cremers, LSD-SLAM: Large-scale direct monocular SLAM, 8690 (2014), 834–849. https://doi.org/10.1007/978-3-319-10605-2_54 |
| [12] |
R. Mur-Artal, J. M. M. Montiel, J. D. Tardós, ORB-SLAM: a versatile and accurate monocular SLAM system, IEEE Trans. Rob., 31 (2015), 1147–1163. https://doi.org/10.1109/TRO.2015.2463671 doi: 10.1109/TRO.2015.2463671
|
| [13] |
B. M. Nordfeldt-Fiol, F. Bonin-Font, G. Oliver, Evolving real-time stereo odometry for auv navigation in challenging marine environments, J. Intell. Rob. Syst., 108 (2023). https://doi.org/10.1007/s10846-023-01932-0 doi: 10.1007/s10846-023-01932-0
|
| [14] |
M. Birem, R. Kleihorst, N. El-Ghouti, Visual odometry based on the fourier transform using a monocular ground-facing camera, J. Real-Time Image Process., 14 (2018), 637–646. https://doi.org/10.1007/s11554-017-0706-3 doi: 10.1007/s11554-017-0706-3
|
| [15] |
L. De-Maeztu, U. Elordi, M. Nieto, J. Barandiaran, O. Otaegui, A temporally consistent grid-based visual odometry framework for multi-core architectures, J. Real-Time Image Process., 10 (2015), 759–769. https://doi.org/10.1007/s11554-014-0425-y doi: 10.1007/s11554-014-0425-y
|
| [16] |
G. Costante, M. Mancini, P. Valigi, T. A. Ciarfuglia, Exploring representation learning with CNNs for frame-to-frame ego-motion estimation, IEEE Rob. Autom. Lett., 1 (2016), 18–25. https://doi.org/10.1109/LRA.2015.2505717 doi: 10.1109/LRA.2015.2505717
|
| [17] | S. Wang, R. Clark, H. Wen, N. Trigoni, DeepVO: Towards end-to-end visual odometry with deep recurrent convolutional neural networks, in 2017 IEEE International Conference on Robotics and Automation (ICRA), (2017), 2043–2050. https://doi.org/10.1109/ICRA.2017.7989236 |
| [18] | M. R. U. Saputra, P. P. B. de Gusmao, S. Wang, A. Markham, N. Trigoni, Learning monocular visual odometry through geometry-aware curriculum learning, in 2019 International Conference on Robotics and Automation (ICRA), (2019), 3549–3555. https://doi.org/10.1109/ICRA.2019.8793581 |
| [19] | M. R. U. Saputra, P. Gusmao, Y. Almalioglu, A. Markham, N. Trigoni, Distilling knowledge from a deep pose regressor network, in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), (2019), 263–272. https://doi.org/10.1109/ICCV.2019.00035 |
| [20] | F. Xue, X. Wang, S. Li, Q. Wang, J. Wang, H. Zha, Beyond tracking: Selecting memory and refining poses for deep visual odometry, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 8567–8575. https://doi.org/10.1109/CVPR.2019.00877 |
| [21] | T. Zhou, M. Brown, N. Snavely, D. G. Lowe, Unsupervised learning of depth and ego-motion from video, in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 6612–6619. https://doi.org/10.1109/CVPR.2017.700 |
| [22] | C. Godard, O. M. Aodha, M. Firman, G. Brostow, Digging into self-supervised monocular depth estimation, in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), (2019), 3827–3837. https://doi.org/10.1109/ICCV.2019.00393 |
| [23] | S. Vijayanarasimhan, S. Ricco, C. Schmid, R. Sukthankar, K. Fragkiadaki, SfM-Net: Learning of structure and motion from video, preprint, arXiv: 1704.07804. |
| [24] | Z. Yin, J. Shi, GeoNet: Unsupervised learning of dense depth, optical flow and camera pose, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 1983–1992. https://doi.org/10.1109/CVPR.2018.00212 |
| [25] | H. Jiang, L. Ding, Z. Sun, R. Huang, DiPE: Deeper into photometric errors for unsupervised learning of depth and ego-motion from monocular videos, in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), (2020), 10061–10067. https://doi.org/10.1109/IROS45743.2020.9341074 |
| [26] |
J. Xu, L. Su, F. Ye, K. Li, Y. Lai, Densefilter: Feature correspondence filter based on dense networks for VSLAM, J. Intell. Rob. Syst., 106 (2022). https://doi.org/10.1007/s10846-022-01735-9 doi: 10.1007/s10846-022-01735-9
|
| [27] |
Z. Hongru, Q. Xiuquan, Graph attention network-optimized dynamic monocular visual odometry, Appl. Intell., 53 (2023), 23067–23082. https://doi.org/10.1007/s10489-023-04687-1 doi: 10.1007/s10489-023-04687-1
|
| [28] |
B. Chen, W. Wu, Z. Li, T. Han, Z. Chen, W. Zhang, Attention-guided cross-modal multiple feature aggregation network for RGB-D salient object detection, Electron. Res. Arch., 32 (2024), 643–669. https://doi.org/10.3934/era.2024031 doi: 10.3934/era.2024031
|
| [29] |
R. Yadav, R. Kala, Fusion of visual odometry and place recognition for SLAM in extreme conditions, Appl. Intell., 52 (2022), 11928–11947. https://doi.org/10.1007/s10489-021-03050-6 doi: 10.1007/s10489-021-03050-6
|
| [30] | A. Rosinol, J. J. Leonard, L. Carlone, NeRF-SLAM: Real-time dense monocular SLAM with neural radiance fields, in 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), (2023), 3437–3444. https://doi.org/10.1109/IROS55552.2023.10341922 |
| [31] | C. Chung, Y. Tseng, Y. Hsu, X. Shi, Y. Hua, J. Yeh, et al., Orbeez-SLAM: A real-time monocular visual SLAM with ORB features and NeRF-realized mapping, in 2023 IEEE International Conference on Robotics and Automation (ICRA), (2023), 9400–9406. https://doi.org/10.1109/ICRA48891.2023.10160950 |
| [32] |
R. Liang, J. Yuan, B. Kuang, Q. Liu, Z. Guo, DIG-SLAM: an accurate RGB-D SLAM based on instance segmentation and geometric clustering for dynamic indoor scenes, Meas. Sci. Technol., 35 (2024). https://doi.org/10.1088/1361-6501/acfb2d doi: 10.1088/1361-6501/acfb2d
|
| [33] | T. Hui, X. Tang, C. C. Loy, Liteflownet: A lightweight convolutional neural network for optical flow estimation, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 8981–8989. https://doi.org/10.1109/CVPR.2018.00936 |
| [34] |
J. Zhang, L. Yang, MonodepthPlus: self-supervised monocular depth estimation using soft-attention and learnable outlier-masking, J. Electron. Imaging, 30 (2021), 023017. https://doi.org/10.1117/1.JEI.30.2.023017 doi: 10.1117/1.JEI.30.2.023017
|
| [35] |
G. Wang, J. Zhong, S. Zhao, W. Wu, Z. Liu, H. Wang, 3D hierarchical refinement and augmentation for unsupervised learning of depth and pose from monocular video, IEEE Trans. Circuits Syst. Video Technol., 33 (2023), 1776–1786. https://doi.org/10.1109/TCSVT.2022.3215587 doi: 10.1109/TCSVT.2022.3215587
|
| [36] | D. Eigen, R. Fergus, Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture, in 2015 IEEE International Conference on Computer Vision (ICCV), (2015), 2650–2658. https://doi.org/10.1109/ICCV.2015.304 |
| [37] | A. Geiger, J. Ziegler, C. Stiller, Stereoscan: Dense 3d reconstruction in real-time, in 2011 IEEE Intelligent Vehicles Symposium (IV), (2011), 963–968. https://doi.org/10.1109/IVS.2011.5940405 |
| [38] |
R. Mur-Artal, J. D. Tardos, ORB-SLAM2: An open-source SLAM system for monocular, stereo, and RGB-D cameras, IEEE Trans. Rob., 33 (2017), 1255–1262. https://doi.org/10.1109/TRO.2017.2705103 doi: 10.1109/TRO.2017.2705103
|
| [39] | J. Bian, Z. Li, N. Wang, H. Zhan, C. Shen, M. Cheng, et al., Unsupervised scale-consistent depth and ego-motion learning from monocular video, preprint, arXiv: 1908.10553. |
| [40] | H. Zhan, R. Garg, C. S. Weerasekera, K. Li, H. Agarwal, I. Reid, Unsupervised learning of monocular depth estimation and visual odometry with deep feature reconstruction, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 340–349. https://doi.org/10.1109/CVPR.2018.00043 |
| [41] | A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, et al., Pytorch: An imperative style, high-performance deep learning library, preprint, arXiv: 1912.01703. |
| [42] | D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, preprint, arXiv: 1412.6980. |
| [43] | W. Zhao, S. Liu, Y. Shu, Y. Liu, Towards better generalization: Joint depth-pose learning without posenet, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2020), 9148–9158. https://doi.org/10.1109/CVPR42600.2020.00917 |
| [44] | Y. Zou, P. Ji, Q. Tran, J. Huang, M. Chandraker, Learning monocular visual odometry via self-supervised long-term modeling, in Computer Vision-ECCV 2020, 12359 (2020), 710–727. https://doi.org/10.1007/978-3-030-58568-6_42 |









Figures(10) / Tables(5)
Shuangjie Yuan, Jun Zhang, Yujia Lin, Lu Yang. Hybrid self-supervised monocular visual odometry system based on spatio-temporal features[J]. Electronic Research Archive, 2024, 32(5): 3543-3568. doi: 10.3934/era.2024163







 DownLoad:
DownLoad: