The objective of reinforcement learning (RL) is to find an optimal strategy for solving a dynamical control problem. Evolution strategy (ES) has been shown great promise in many challenging reinforcement learning (RL) tasks, where the underlying dynamical system is only accessible as a black box such that adjoint methods cannot be used. However, existing ES methods have two limitations that hinder its applicability in RL. First, most existing methods rely on Monte Carlo based gradient estimators to generate search directions. Due to low accuracy of Monte Carlo estimators, the RL training suffers from slow convergence and requires more iterations to reach the optimal solution. Second, the landscape of the reward function can be deceptive and may contain many local maxima, causing ES algorithms to prematurely converge and be unable to explore other parts of the parameter space with potentially greater rewards. In this work, we employ a Directional Gaussian Smoothing Evolutionary Strategy (DGS-ES) to accelerate RL training, which is well-suited to address these two challenges with its ability to (i) provide gradient estimates with high accuracy, and (ii) find nonlocal search direction which lays stress on large-scale variation of the reward function and disregards local fluctuation. Through several benchmark RL tasks demonstrated herein, we show that the DGS-ES method is highly scalable, possesses superior wall-clock time, and achieves competitive reward scores to other popular policy gradient and ES approaches.
Citation: Jiaxin Zhang, Hoang Tran, Guannan Zhang. Accelerating reinforcement learning with a Directional-Gaussian-Smoothing evolution strategy[J]. Electronic Research Archive, 2021, 29(6): 4119-4135. doi: 10.3934/era.2021075
The objective of reinforcement learning (RL) is to find an optimal strategy for solving a dynamical control problem. Evolution strategy (ES) has been shown great promise in many challenging reinforcement learning (RL) tasks, where the underlying dynamical system is only accessible as a black box such that adjoint methods cannot be used. However, existing ES methods have two limitations that hinder its applicability in RL. First, most existing methods rely on Monte Carlo based gradient estimators to generate search directions. Due to low accuracy of Monte Carlo estimators, the RL training suffers from slow convergence and requires more iterations to reach the optimal solution. Second, the landscape of the reward function can be deceptive and may contain many local maxima, causing ES algorithms to prematurely converge and be unable to explore other parts of the parameter space with potentially greater rewards. In this work, we employ a Directional Gaussian Smoothing Evolutionary Strategy (DGS-ES) to accelerate RL training, which is well-suited to address these two challenges with its ability to (i) provide gradient estimates with high accuracy, and (ii) find nonlocal search direction which lays stress on large-scale variation of the reward function and disregards local fluctuation. Through several benchmark RL tasks demonstrated herein, we show that the DGS-ES method is highly scalable, possesses superior wall-clock time, and achieves competitive reward scores to other popular policy gradient and ES approaches.

| [1] | M. Abramowitz and I. Stegun (eds.), Handbook of Mathematical Functions, Dover, New York, 1972. |
| [2] | M. Andrychowicz, F. Wolski, A. Ray, J. Schneider, R. Fong, P. Welinder, B. McGrew, J. Tobin, O. P. Abbeel and W. Zaremba, Hindsight experience replay, in Advances in Neural Information Processing Systems, (2017), 5048–5058. |
| [3] | A. S. Berahas, L. Cao, K. Choromanskiv and K. Scheinberg, A theoretical and empirical comparison of gradient approximations in derivative-free optimization, arXiv: 1905.01332. |
| [4] | G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang and W. Zaremba, Openai gym, arXiv preprint arXiv: 1606.01540. |
| [5] | K. Choromanski, A. Pacchiano, J. Parker-Holder and Y. Tang, From complexity to simplicity: Adaptive es-active subspaces for blackbox optimization, NeurIPS. |
| [6] | K. Choromanski, A. Pacchiano, J. Parker-Holder and Y. Tang, Provably robust blackbox optimization for reinforcement learning, arXiv: 1903.02993. |
| [7] | E. Conti, V. Madhavan, F. P. Such, J. Lehman, K. O. Stanley and J. Clune, Improving exploration in evolution strategies for deep reinforcement learning via a population of novelty-seeking agents, NIPS. |
| [8] | E. Coumans and Y. Bai, Pybullet, a python module for physics simulation for games, robotics and machine learning, GitHub Repository. |
| [9] | P. Dhariwal, C. Hesse, O. Klimov, A. Nichol, M. Plappert, A. Radford, J. Schulman, S. Sidor, Y. Wu and P. Zhokhov, Openai Baselines, https://github.com/openai/baselines, 2017. |
| [10] | A. D. Flaxman, A. T. Kalai and H. B. McMahan, Online convex optimization in the bandit setting: Gradient descent without a gradient, Proceedings of the 16th Annual ACM-SIAM symposium on Discrete Algorithms, 385–394, ACM, New York, (2005). |
| [11] | S. Fujimoto, H. Van Hoof and D. Meger, Addressing function approximation error in actor-critic methods, arXiv preprint, arXiv: 1802.09477. |
| [12] |
N. Hansen, The CMA evolution strategy: A comparing review, in Towards a new Evolutionary Computation, Springer, 192 (2006), 75–102. doi: 10.1007/3-540-32494-1_4

|
| [13] |
Completely derandomized self-adaptation in evolution strategies. Evolutionary Computation (2001) 9: 159-195.
|
| [14] | T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver and D. Wierstra, Continuous control with deep reinforcement learning, ICLR. |
| [15] | N. Maheswaranathan, L. Metz, G. Tucker, D. Choi and J. Sohl-Dickstein, Guided evolutionary strategies: Augmenting random search with surrogate gradients, Proceedings of the 36th International Conference on Machine Learning. |
| [16] | F. Meier, A. Mujika, M. M. Gauy and A. Steger, Improving gradient estimation in evolutionary strategies with past descent directions, Optimization Foundations for Reinforcement Learning Workshop at NeurIPS. |
| [17] | V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver and K. Kavukcuoglu, Asynchronous methods for deep reinforcement learning, ICML, 1928–1937. |
| [18] |
V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al., Human-level control through deep reinforcement learning, Nature, 518 (2015), 529-533. doi: 10.1038/nature14236
|
| [19] | P. Moritz, R. Nishihara, S. Wang, A. Tumanov, R. Liaw, E. Liang, M. Elibol, Z. Yang, W. Paul, M. I. Jordan et al., Ray: A distributed framework for emerging $\{$AI$\}$ applications, in 13th $\{USENIX\}$ Symposium on Operating Systems Design and Implementation ($\{OSDI\}$ 18), (2018), 561–577. |
| [20] |
Random gradient-free minimization of convex functions. Found. Comput. Math. (2017) 17: 527-566.
|
| [21] | A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga and A. Lerer, Automatic differentiation in pytorch., |
| [22] |
A. Quarteroni, R. Sacco and F. Saleri, Numerical Mathematics, Texts in Applied Mathematics, 37. Springer-Verlag, Berlin, 2007. doi: 10.1007/b98885
|
| [23] | T. Salimans, J. Ho, X. Chen, S. Sidor and I. Sutskever, From complexity to simplicity as a scalable alternative to reinforcement learning, arXiv preprint, arXiv: 1703.03864. |
| [24] | J. Schulman, S. Levine, P. Abbeel, M. I. Jordan and P. Moritz, Trust region policy optimization, ICML, 1889–1897. |
| [25] | J. Schulman, F. Wolski, P. Dhariwal, A. Radford and O. Klimov, Proximal policy optimization algorithms, arXiv preprint, arXiv: 1707.06347. |
| [26] |
Parameter-exploring policy gradients. Neural Networks (2010) 23: 551-559.
|
| [27] | Robot skill learning: From reinforcement learning to evolution strategies. Paladyn Journal of Behavioral Robotics (2013) 4: 49-61. |
| [28] |
D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. v. d. Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, et al., Mastering the game of go with deep neural networks and tree search, Nature, 529 (2016), 484-489. doi: 10.1038/nature16961
|
| [29] | F. P. Such, V. Madhavan, E. Conti, J. Lehman, K. O. Stanley and J. Clune, Deep neuroevolution: Genetic algorithms are a competitive alternative for training deep neural networks for reinforcement learning, arXiv preprint, arXiv: 1712.06567. |
| [30] | R. S. Sutton and A. G. Barto (eds.), Reinforcement Learning: An introduction, Second edition. Adaptive Computation and Machine Learning. MIT Press, Cambridge, MA, 2018. |
| [31] |
Fast buckling load numerical prediction method for imperfect shells under axial compression based on pod and vibration correlation technique. Composite Structures (2020) 252: 112721.
|
| [32] |
K. Tian, Z. Li, L. Huang, K. Du, L. Jiang and B. Wang, Enhanced variable-fidelity surrogate-based optimization framework by gaussian process regression and fuzzy clustering, Comput. Methods Appl. Mech. Engrg., 366 (2020), 113045, 19 pp. doi: 10.1016/j.cma.2020.113045
|
| [33] | J. Zhang, H. Tran, D. Lu and G. Zhang, Enabling long-range exploration in minimization of multimodal functions, Proceedings of 37th on Uncertainty in Artificial Intelligence (UAI). |
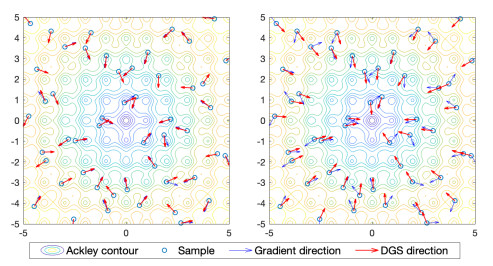






Figures(7)
Jiaxin Zhang, Hoang Tran, Guannan Zhang. Accelerating reinforcement learning with a Directional-Gaussian-Smoothing evolution strategy[J]. Electronic Research Archive, 2021, 29(6): 4119-4135. doi: 10.3934/era.2021075







 DownLoad:
DownLoad: