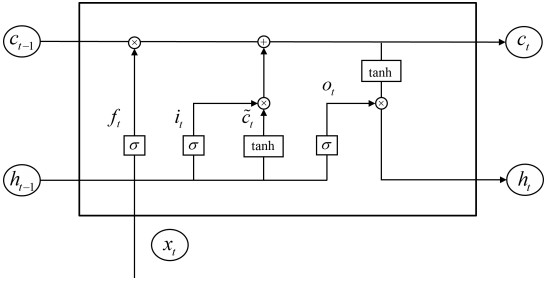
Short-term load forecasting is of great significance to the operation of power systems. Various uncertain factors, such as meteorological social data, have already been combined with historical power data to create more accurate load forecasting models. In traditional systems, data from various industries and regions are centralized for knowledge extraction. However, concerns regarding data security and privacy often prevent industries from sharing their data, limiting both the quantity and diversity of data available for forecasting models. These challenges drive the adoption of federated learning (FL) to address issues related to data silos and privacy. In this paper, a novel framework for short-term load forecasting was proposed using historical data from industries such as power, meteorology, and finance. Long short-term memory (LSTM) networks were utilized for forecasting, and federated learning (FL) was implemented to protect data privacy. FL allows clients in multiple regions to collaboratively train a shared model without exposing their data. To further enhance security, the homomorphic encryption (HE) using Paillier algorithm was introduced during the federated process. Experimental results demonstrate that the federated model, which extracts knowledge from different regions, outperforms locally trained models. Furthermore, longer HE keys have little effect on predictive performance but significantly slow down encryption and decryption, thereby increasing training time.
Citation: Mengdi Wang, Rui Xin, Mingrui Xia, Zhifeng Zuo, Yinyin Ge, Pengfei Zhang, Hongxing Ye. A federated LSTM network for load forecasting using multi-source data with homomorphic encryption[J]. AIMS Energy, 2025, 13(2): 265-289. doi: 10.3934/energy.2025011
Short-term load forecasting is of great significance to the operation of power systems. Various uncertain factors, such as meteorological social data, have already been combined with historical power data to create more accurate load forecasting models. In traditional systems, data from various industries and regions are centralized for knowledge extraction. However, concerns regarding data security and privacy often prevent industries from sharing their data, limiting both the quantity and diversity of data available for forecasting models. These challenges drive the adoption of federated learning (FL) to address issues related to data silos and privacy. In this paper, a novel framework for short-term load forecasting was proposed using historical data from industries such as power, meteorology, and finance. Long short-term memory (LSTM) networks were utilized for forecasting, and federated learning (FL) was implemented to protect data privacy. FL allows clients in multiple regions to collaboratively train a shared model without exposing their data. To further enhance security, the homomorphic encryption (HE) using Paillier algorithm was introduced during the federated process. Experimental results demonstrate that the federated model, which extracts knowledge from different regions, outperforms locally trained models. Furthermore, longer HE keys have little effect on predictive performance but significantly slow down encryption and decryption, thereby increasing training time.

| [1] |
Akhtar S, Shahzad S, Zaheer A, et al. (2023) Short-Term load forecasting models: A review of challenges, progress, and the road ahead. Energies 16: 4060. https://doi.org/10.3390/en16104060 doi: 10.3390/en16104060

|
| [2] | ENTSO-E (2021) Enhanced load forecasting. Available from: https://www.entsoe.eu/Technopedia/techsheets/enhanced-load-forecasting. |
| [3] | Lis R, Vanin A, Kotelnikova A (2017) Methods of training of neural networks for short term load forecasting in smart grids. Comput Collect Intell, 433–441. https://doi.org/10.1007/978-3-319-67074-4_42 |
| [4] |
Hsiao Y-H (2015) Household electricity demand forecast based on context information and user daily schedule analysis from meter data. IEEE Trans Ind Inf 11: 33–43. https://doi.org/10.1109/TII.2014.2363584 doi: 10.1109/TII.2014.2363584
|
| [5] |
Lusis P, Khalilpour KR, Andrew L, et al. (2017) Short-term residential load forecasting: Impact of calendar effects and forecast granularity. Appl Energy 205: 654–669. https://doi.org/10.1016/j.apenergy.2017.07.114 doi: 10.1016/j.apenergy.2017.07.114
|
| [6] |
Li L, Fan Y, Tse M, et al. (2020) A review of applications in federated learning. Comput Ind Eng 149: 106854. https://doi.org/10.1016/j.cie.2020.106854 doi: 10.1016/j.cie.2020.106854
|
| [7] | Taïk A, Cherkaoui S (2020) Electrical load forecasting using edge computing and federated learning. ICC 2020—2020 IEEE International Conference on Communications (ICC), 1–6. https://doi.org/10.1109/ICC40277.2020.9148937 |
| [8] |
Gholizadeh N, Musilek P (2022) Federated learning with hyperparameter-based clustering for electrical load forecasting. Int Things 17: 100470. https://doi.org/10.1016/j.iot.2021.100470 doi: 10.1016/j.iot.2021.100470
|
| [9] |
Briggs C, Fan Z, Andras P (2022) Federated learning for short-term residential load forecasting. IEEE Open Access J Power Energy 9: 573–583. https://doi.org/10.1109/OAJPE.2022.32062200 doi: 10.1109/OAJPE.2022.32062200
|
| [10] |
Wang Y, Gao N, Hug G (2023) Personalized federated learning for individual consumer load forecasting. CSEE J Power Energy Syst 9: 326–330. https://doi.org/10.17775/CSEEJPES.2021.07350 doi: 10.17775/CSEEJPES.2021.07350
|
| [11] |
Acar A, Aksu H, Uluagac AS, et al. (2018) A survey on homomorphic encryption schemes: Theory and implementation. ACM Comput Surv (CSUR) 51: 79. https://doi.org/10.1145/3214303 doi: 10.1145/3214303
|
| [12] | Fan Y, Chen Z, Zhai Z, et al. (2024) Distributed power load federated prediction for high-energy-consuming enterprises based on homomorphic encryption. 43rd Chinese Control Conference (CCC), 2876–2883. https://doi.org/10.23919/CCC63176.2024.10662589 |
| [13] |
Wang H, Zhao Y, He S, et al. (2024) Federated learning-based privacy-preserving electricity load forecasting scheme in edge computing scenario. Int J Commun Syst 37: e5670. https://doi.org/10.1002/dac.5670 doi: 10.1002/dac.5670
|
| [14] |
Fang C, Guo Y, Ma J, et al. (2022) A privacy-preserving and verifiable federated learning method based on blockchain. Comput Commun 186: 1–11. https://doi.org/10.1016/j.comcom.2022.01.002 doi: 10.1016/j.comcom.2022.01.002
|
| [15] |
Paillier P (1999) Public-Key cryptosystems based on composite degree residuosity classes. Lect Notes Comput Sci 1592: 223–238. https://doi.org/10.1007/3-540-48910-X_16 doi: 10.1007/3-540-48910-X_16
|
| [16] | Jin W, Yao Y, Han S, et al. (2023) FedML-HE: An efficient homomorphic-encryption-based privacy-preserving federated learning system. Comput Sci. https://doi.org/10.48550/arXiv.2303.10837 |
| [17] | Reddy GP, Pavan Kumar YV (2023) A beginner's guide to federated learning. 2023 Intell Methods, Syst, Appl (IMSA), 557–562. https://doi.org/10.1109/IMSA58542.2023.10217383 |
| [18] |
Sheller MJ, Edwards B, Reina GA, et al. (2020) Federated learning in medicine: Facilitating multi-institutional collaborations without sharing patient data. Sci Rep 10: 12598. https://doi.org/10.1038/s41598-020-69250-1 doi: 10.1038/s41598-020-69250-1
|
| [19] |
Sadilek A, Liu L, Nguyen D, et al. (2021) Privacy-first health research with federated learning. npj Digital Med 4: 132. https://doi.org/10.1038/s41746-021-00489-2 doi: 10.1038/s41746-021-00489-2
|
| [20] |
Ng D, Lan X, Yao MMS, et al. (2021) Federated learning: A collaborative effort to achieve better medical imaging models for individual sites that have small labelled datasets. Quant Imaging Med Surg 11: 852–857. https://doi.org/10.21037/qims-20-595 doi: 10.21037/qims-20-595
|
| [21] |
Wang S, Tuor T, Salonidis T, et al. (2019) Adaptive federated learning in resource constrained edge computing systems. IEEE J Sel Areas Commun 37: 1205–1221. https://doi.org/10.1109/JSAC.2019.2904348 doi: 10.1109/JSAC.2019.2904348
|
| [22] | Wang K, He Q, Chen F, et al. (2023) FedEdge: Accelerating edge-assisted federated learning. Proceedings of the ACM Web Conference 2023, 2895–2904. https://doi.org/10.1145/3543507.3583264 |
| [23] |
Al-Selwi SM, Hassan MF, Abdulkadir SJ, et al. (2024) RNN-LSTM: From applications to modeling techniques and beyond—Systematic review. J King Saud Univ—Comput Inf Sci 36: 102068. https://doi.org/10.1016/j.jksuci.2024.102068 doi: 10.1016/j.jksuci.2024.102068
|
| [24] |
Lindemann B, Müller T, Vietz H, et al. (2021) A survey on long short-term memory networks for time series prediction. Procedia CIRP 99: 650–655. https://doi.org/10.1016/j.procir.2021.03.088 doi: 10.1016/j.procir.2021.03.088
|
| [25] |
Kong W, Dong ZY, Jia Y, et al. (2017) Short-term residential load forecasting based on LSTM recurrent neural network. IEEE Trans Smart Grid 10: 841–851. https://doi.org/10.1109/TSG.2017.2753802 doi: 10.1109/TSG.2017.2753802
|
| [26] |
Yu Y, Si X, Hu C, et al. (2019) A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput 31: 1235–1270. https://doi.org/10.1162/neco_a_01199 doi: 10.1162/neco_a_01199
|
| [27] |
Rafi SH, Nahid-Al-Masood, Deeba SR, et al. (2021) A short-term load forecasting method using integrated CNN and LSTM network. IEEE Access 9: 32436–32448. https://doi.org/10.1109/ACCESS.2021.3060654 doi: 10.1109/ACCESS.2021.3060654
|
| [28] |
Alhussein M, Aurangzeb K, Haider SI (2020) Hybrid CNN-LSTM model for short-term individual household load forecasting. IEEE Access 8: 180544–180557. https://doi.org/10.1109/ACCESS.2020.3028281 doi: 10.1109/ACCESS.2020.3028281
|
| [29] | Cheon JH, Costache A, Moreno RC, et al. (2021) Introduction to homomorphic encryption and schemes. In: Lauter K, Dai W, Laine K, Editors Prot Privacy Homomorphic Encryption, 3–28. https://doi.org/10.1007/978-3-030-77287-1_1 |
| [30] |
Zhang L, Xu J, Vijayakumar P, et al. (2022) Homomorphic encryption-based privacy-preserving federated learning in IoT-Enabled healthcare system. IEEE Trans Network Sci Eng 10: 2864–2880. https://doi.org/10.1109/TNSE.2022.3185327 doi: 10.1109/TNSE.2022.3185327
|
| [31] |
Hatip A, Zayood K, Scharif R, et al. (2024) Enhancing security and privacy in IoT-based learning with homomorphic encryption. Int J Wireless Ad Hoc Commun 8: 08–08. https://doi.org/10.54216/IJWAC.080101 doi: 10.54216/IJWAC.080101
|
| [32] |
Kachouh B, Hariss K, Sliman L, et al. (2021) Privacy preservation of genome data analysis using homomorphic encryption. Serv Oriented Comput Appl 15: 273–287. https://doi.org/10.1007/s11761-021-00326-0 doi: 10.1007/s11761-021-00326-0
|
| [33] |
Basuki AI, Setiawan I, Rosiyadi D (2022) Preserving privacy for blockchain-driven image watermarking using fully homomorphic encryption. Proceedings of the 2021 International Conference on Computer, Control, Informatics and Its Applications 21: 51–155. https://doi.org/10.1145/3489088.3489130 doi: 10.1145/3489088.3489130
|
| [34] | Gadiwala H, Bavani R, Panchal R, et al. (2024) Enabling privacy-preserving machine learning: Federated learning with homomorphic encryption. Proceedings of the 2024 10th International Conference on Smart Computing and Communication (ICSCC), 311–317. https://doi.org/10.1109/ICSCC62041.2024.10690391 |
| [35] |
Mohialden YM, Hussien NM, Salman SA, et al. (2023) Secure federated learning with a homomorphic encryption model. Int J Papier Adv Sci Rev 4: 1–7. https://doi.org/10.47667/ijpasr.v4i3.235 doi: 10.47667/ijpasr.v4i3.235
|
| [36] |
Wiese F, Schlecht I, Bunke W-D, et al. (2018) Open power system data—Frictionless data for electricity system modelling. Appl Energy 236: 401–409. https://doi.org/10.1016/j.apenergy.2018.11.097 doi: 10.1016/j.apenergy.2018.11.097
|
| [37] | Kingma DP, Ba J (2014) Adam: A method for stochastic optimization. Comput Sci. https://doi.org/10.48550/arXiv.1412.6980 |






Figures(7) / Tables(7)

Mengdi Wang, Rui Xin, Mingrui Xia, Zhifeng Zuo, Yinyin Ge, Pengfei Zhang, Hongxing Ye. A federated LSTM network for load forecasting using multi-source data with homomorphic encryption[J]. AIMS Energy, 2025, 13(2): 265-289. doi: 10.3934/energy.2025011







 DownLoad:
DownLoad: