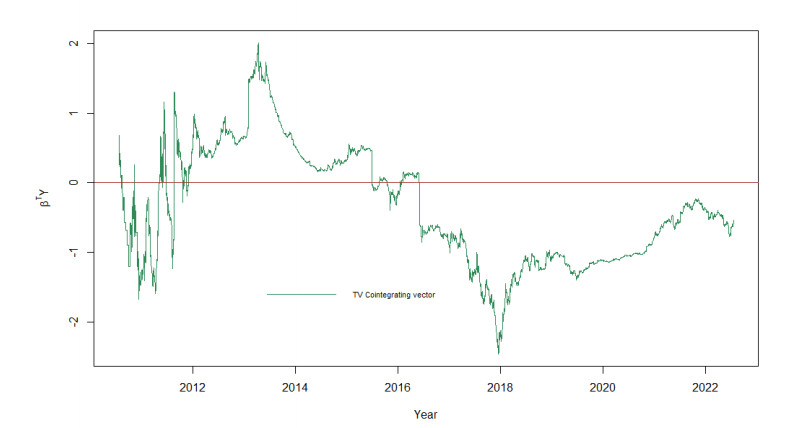
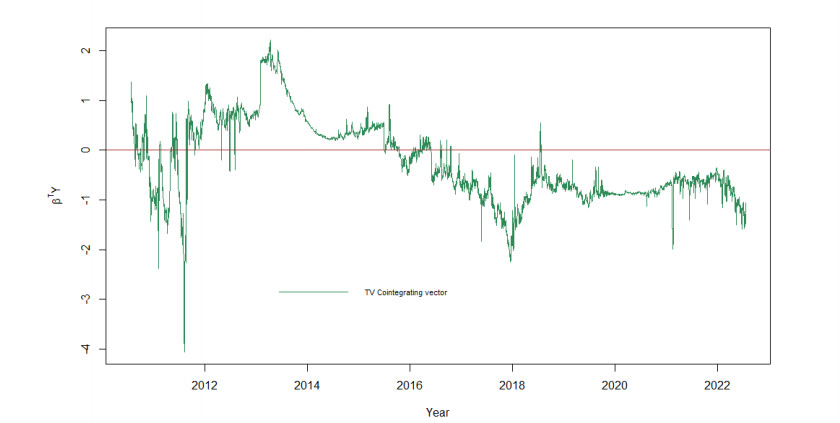
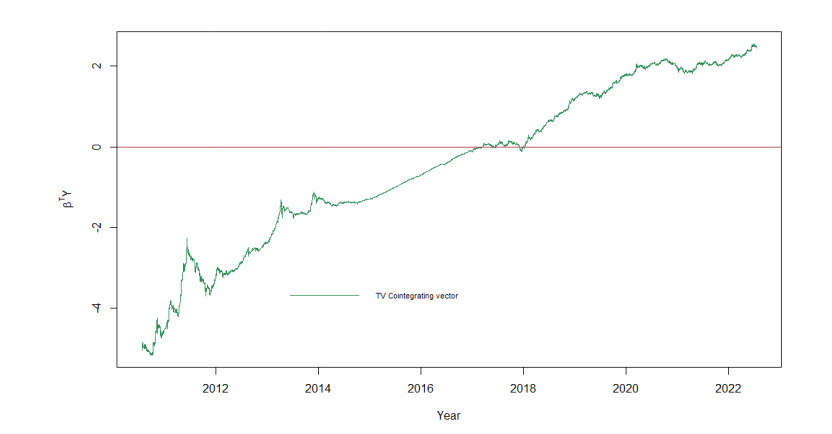
The paper investigates the long-run relationship between bitcoin and its marginal cost between July 2010 and July 2022. We derive Bitcoin's marginal cost of production from a model of Bitcoin mining grounded in the Bitcoin code, and show that its production cost is a function of only two variables, the electricity price and the mining hardware efficiency. We then estimate a time-varying vector error correction model, and also the cointegration between bitcoin's price and Bitcoin network's hash rate, a commonly used production cost proxy. Our results show that the time-varying cointegration between bitcoin's price and its hash rate is permanently in disequilibrium, bar a short time interval between March 2017 and January 2018. Consequently, although bitcoin's price and the hash rate are cointegrated, it is clear that the latter does not function as a stable long-run explanatory variable for bitcoin price dynamics. On the contrary, we found that bitcoin's price and its marginal cost of production have been cointegrated since its inception, and that their time-varying long-run relationship always reverts towards equilibrium - and often to equilibrium- after long periods of divergence. These results contrast with most of the empirical literature that attempted to model the relationship betweeen bitcoin and its fundamentals in a time-invariant framework, but are consistent with recent research showing a significant role for production cost in the determination of bitcoin's price dynamics.
Citation: Sylvia Gottschalk. Digital currency price formation: A production cost perspective[J]. Quantitative Finance and Economics, 2022, 6(4): 669-695. doi: 10.3934/QFE.2022030
The paper investigates the long-run relationship between bitcoin and its marginal cost between July 2010 and July 2022. We derive Bitcoin's marginal cost of production from a model of Bitcoin mining grounded in the Bitcoin code, and show that its production cost is a function of only two variables, the electricity price and the mining hardware efficiency. We then estimate a time-varying vector error correction model, and also the cointegration between bitcoin's price and Bitcoin network's hash rate, a commonly used production cost proxy. Our results show that the time-varying cointegration between bitcoin's price and its hash rate is permanently in disequilibrium, bar a short time interval between March 2017 and January 2018. Consequently, although bitcoin's price and the hash rate are cointegrated, it is clear that the latter does not function as a stable long-run explanatory variable for bitcoin price dynamics. On the contrary, we found that bitcoin's price and its marginal cost of production have been cointegrated since its inception, and that their time-varying long-run relationship always reverts towards equilibrium - and often to equilibrium- after long periods of divergence. These results contrast with most of the empirical literature that attempted to model the relationship betweeen bitcoin and its fundamentals in a time-invariant framework, but are consistent with recent research showing a significant role for production cost in the determination of bitcoin's price dynamics.

| [1] | Aoyagi J, Hattori T (2019) The empirical analysis of bitcoin market in the general equilibrium framework. http://dx.doi.org/10.2139/ssrn.3433833 |
| [2] |
Bedford Taylor M (2017) The evolution of Bitcoin hardware. Computer 50: 58-66. http://dx.doi.org/10.1109/MC.2017.3571056 doi: 10.1109/MC.2017.3571056

|
| [3] | Bianchetti M, Ricci C, Scaringi M (2018) Are cryptocurrencies real financial bubbles? evidence from quantitative analyses. http://dx.doi.org/10.2139/ssrn.3092427 |
| [4] |
Bierens HJ, Martins LF (2010) Time-varying cointegration. Econ Theory 26: 1453–1490. https://doi.org/10.1017/S0266466609990648 doi: 10.1017/S0266466609990648
|
| [5] |
Bouri E, Gupta R, Roubaud D (2019) Herding behaviour in cryptocurrencies. Financ Res Lett 29: 216-221. https://doi.org/10.1016/j.frl.2018.07.008 doi: 10.1016/j.frl.2018.07.008
|
| [6] |
Caferra R, Tedeschi G, Morone A (2021) Bitcoin: Bubble that bursts or gold that glitters?. Econ Lett 205: 109942. https://doi.org/10.1016/j.econlet.2021.109942 doi: 10.1016/j.econlet.2021.109942
|
| [7] | Caporale GM, Timur Z (2019) Modelling volatility of cryptocurrencies using markov-switching GARCH models. Res Int Bus Financ 48: 143. |
| [8] |
Chaim P, Laurini MP (2019) Is Bitcoin a bubble? Physica A 517: 222-232. https://doi.org/10.1016/j.physa.2018.11.031 doi: 10.1016/j.physa.2018.11.031
|
| [9] |
Cheah ET, Fry J (2015) Speculative bubbles in bitcoin markets? an empirical investigation into the fundamental value of bitcoin. Econ Lett 130: 32-36. https://doi.org/10.1016/j.econlet.2015.02.029 doi: 10.1016/j.econlet.2015.02.029
|
| [10] | Cheung AWK, Roca E, Su JJ (2015) Crypto-currency bubbles: An application of the Phillips–Shi–Yu (2013) methodology on Mt. Gox bitcoin prices. Appl Econ 47: 2348-2358. https://doi.org/10.1080/00036846.2015.1005827 |
| [11] | Chu J, Chan S, Nadarajah S, et al. (2017) GARCH modelling of cryptocurrencies. J Risk Financial Manag 10. https://www.mdpi.com/1911-8074/10/4/17 |
| [12] |
De Vries A (2018) Bitcoin's growing energy problem. Joule 2: 801-805. https://doi.org/10.3390/jrfm10040017 doi: 10.3390/jrfm10040017
|
| [13] |
Delgado-Mohatar O, Felis-Rota M, Fernández-Herraiz C (2019) The Bitcoin mining breakdown: Is mining still profitable? Econ Lett 184: 108492. https://doi.org/10.1016/j.econlet.2019.05.044 doi: 10.1016/j.econlet.2019.05.044
|
| [14] |
Derks J, Gordijn J, Siegmann A (2018) From chaining blocks to breaking even: A study on the profitability of bitcoin mining from 2012 to 2016. Electron Mark 28: 321-338.https://doi.org/10.1007/s12525-018-0308-3 doi: 10.1007/s12525-018-0308-3
|
| [15] |
Dodd N (2018) The social life of Bitcoin. Theory Cult Soc 35: 35-56. https://doi.org/10.1177/0263276417746464 doi: 10.1177/0263276417746464
|
| [16] | Fantazzini D, Kolodin N (2020) Does the hashrate affect the Bitcoin price? J Risk Financial Manag 13. https://doi.org/10.3390/jrfm13110263 |
| [17] |
Garcia D, Tessone CJ, Mavrodiev P, et al. (2014) The digital traces of bubbles: Feedback cycles between socio-economic signals in the bitcoin economy. J R Soc Interface 11: 20140623. http://doi.org/10.1098/rsif.2014.0623 doi: 10.1098/rsif.2014.0623
|
| [18] | Gyamerah SA (2019) Modelling the volatility of bitcoin returns using GARCH models. Quant Financ Econ 3: 739-753. https://www.aimspress.com/article/doi/10.3934/QFE.2019.4.739 |
| [19] |
Hafner CM (2018) Testing for Bubbles in Cryptocurrencies with Time-Varying Volatility. J Financ Econ 18: 233-249. https://doi.org/10.1093/jjfinec/nby023 doi: 10.1093/jjfinec/nby023
|
| [20] |
Hayes AS (2017) Cryptocurrency value formation: An empirical study leading to a cost of production model for valuing bitcoin. Telemat Inform 34: 1308-1321. https://doi.org/10.1016/j.tele.2016.05.005 doi: 10.1016/j.tele.2016.05.005
|
| [21] | Hayes AS (2019) Bitcoin price and its marginal cost of production: Support for a fundamental value Appl Econ Lett 26: 554-560. https://doi.org/10.1080/13504851.2018.1488040 |
| [22] |
Johansen S (1991) Estimation and hypothesis testing of cointegration vectors in gaussian vector autoregressive models. Econometrica 59: 1551-1580. https://doi.org/10.2307/2938278 doi: 10.2307/2938278
|
| [23] | Kaiser B, Jurado M, Ledger A (2018) The looming threat of China: An analysis of Chinese influence on bitcoin. arXiv. https://doi.org/10.48550/arXiv.1810.02466 |
| [24] |
Katsiampa P (2017) Volatility estimation for bitcoin: A comparison of GARCH models. Econ Lett 158: 3 - 6. https://doi.org/10.1016/j.econlet.2017.06.023 doi: 10.1016/j.econlet.2017.06.023
|
| [25] | Khatun MN, Mitra S, Sarker MNI (2021) Mobile banking during covid-19 pandemic in Bangladesh: A novel mechanism to change and accelerate people's financial access. Green Financ 3: 253-267. https://www.aimspress.com/article/doi/10.3934/GF.2021013 |
| [26] | Kjærland F, Khazal A, Krogstad EA, et al. (2018) An analysis of bitcoin's price dynamics. J Risk Financial Manage 11. https://doi.org/10.3390/jrfm11040063 |
| [27] |
Kristoufek L (2019) Is the bitcoin price dynamics economically reasonable? Evidence from fundamental laws. Physica A 536: 120873. https://doi.org/10.1016/j.physa.2019.04.109 doi: 10.1016/j.physa.2019.04.109
|
| [28] |
Kristoufek L (2020) Bitcoin and its mining on the equilibrium path. Energy Econ 85: 104588. https://doi.org/10.1016/j.eneco.2019.104588 doi: 10.1016/j.eneco.2019.104588
|
| [29] |
Kyriazis N, Papadamou S, Corbet S (2020) A systematic review of the bubble dynamics of cryptocurrency prices. Res Int Bus Finance 54: 101254. https://doi.org/10.1016/j.ribaf.2020.101254 doi: 10.1016/j.ribaf.2020.101254
|
| [30] |
Lee Y, Rhee JH (2022) A VECM analysis of bitcoin price using time-varying cointegration approach. J Deriv Quant Stud 30: 197-218. https://doi.org/10.1108/JDQS-01-2022-0001 doi: 10.1108/JDQS-01-2022-0001
|
| [31] |
Li X, Wang CA (2017) The technology and economic determinants of cryptocurrency exchange rates: The case of bitcoin. Decis Support Syst 95: 49-60. https://doi.org/10.1016/j.dss.2016.12.001 doi: 10.1016/j.dss.2016.12.001
|
| [32] |
Magtanggol III De Guzman RA, So MKP (2018) Empirical analysis of bitcoin prices using threshold time series models. Ann Financ Econ 134: 1-24. https://doi.org/10.1142/S2010495218500173 doi: 10.1142/S2010495218500173
|
| [33] | Makarov I, Schoar A (2021) Blockchain analysis of the bitcoin market. https://doi.org/10.3386/w29396 |
| [34] |
Marthinsen JE, Gordon SR (2022) The price and cost of bitcoin. Quart Rev Econ Financ 85: 280-288. https://doi.org/10.1016/j.qref.2022.04.003 doi: 10.1016/j.qref.2022.04.003
|
| [35] |
Khatun MN, Mitra S, Sarker MNI (2022) Mobile banking during COVID-19 pandemic in Bangladesh: A novel mechanism to change and accelerate people's financial access. Green Financ 3: 253-267. https://doi.org/10.3934/GF.2021013 doi: 10.3934/GF.2021013
|
| [36] | Nakamoto S (2008) Bitcoin: A peer-to-peer electronic cash system. Decentralized Business Review. |
| [37] | O'Dwyer KJ, Malone D (2014) Bitcoin mining and its energy footprint. In: 25th IET Irish Signals & Systems Conference 2014 and 2014 China-Ireland International Conference on Information and Communications Technologies (ISSC 2014/CIICT 2014), 280-285. https://doi.org/10.1049/cp.2014.0699 |
| [38] | Park JY, Hahn SB (1999) Cointegrating regressions with time varying coefficients. Econ Theory 15: 664-703. |
| [39] | Shiller RJ (2000) Irrational exuberance. Princeton University Press. |
| [40] |
Siu TK, Elliott RJ (2021) Bitcoin option pricing with a SETAR-GARCH model. Eur J Finance 27: 564-595. https://doi.org/10.1080/1351847X.2020.1828962 doi: 10.1080/1351847X.2020.1828962
|
| [41] |
Song YD, Aste T (2020) The cost of Bitcoin mining has never really increased. Front Blockchain 3: 565497. https://doi.org/10.3389/fbloc.2020.565497 doi: 10.3389/fbloc.2020.565497
|
| [42] | Stoll C, Klaaßen L, Gallersdörfer U (2019) The carbon footprint of Bitcoin', Joule 3: 1647-1661.https://doi.org/10.1016/j.joule.2019.05.012 |
| [43] |
Vranken H (2017) Sustainability of Bitcoin and blockchains. Curr Opin Env Sust 28: 1-9. https://doi.org/10.1016/j.cosust.2017.04.011 doi: 10.1016/j.cosust.2017.04.011
|
| [44] |
Xiong J, Liu Q, Zhao L (2020) A new method to verify bitcoin bubbles: Based on the production cost. North Am J Econ Finance 51: 101095. https://doi.org/10.1016/j.najef.2019.101095 doi: 10.1016/j.najef.2019.101095
|
| [45] | Youssef M (2022) What drives herding behavior in the cryptocurrency market? J Behav Financ 23: 230-239. https://doi.org/10.1080/15427560.2020.1867142 |
| [46] | Zadé M, Myklebost J (2018) Bitcoin and Ethereum mining hardware. https://doi.org/10.17632/4dw6j3pxz5.1 |
| [47] |
Zadé M, Myklebost J, Tzscheutschler P, et al. (2019) Is Bitcoin the only problem? A scenario model for the power demand of blockchains. Front Energy Res 7: 21. https://doi.org/10.3389/fenrg.2019.00021 doi: 10.3389/fenrg.2019.00021
|
| [48] |
Zhou S (2021) Exploring the driving forces of the bitcoin currency exchange rate dynamics: an EGARCH approach. Empir Econ 60: 557-606. https://doi.org/10.3389/fenrg.2019.00021 doi: 10.3389/fenrg.2019.00021
|
 QFE-06-04-030-s001.pdf QFE-06-04-030-s001.pdf |
 |
Figures(5) / Tables(11)

Sylvia Gottschalk. Digital currency price formation: A production cost perspective[J]. Quantitative Finance and Economics, 2022, 6(4): 669-695. doi: 10.3934/QFE.2022030







 DownLoad:
DownLoad: