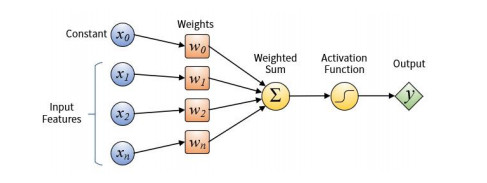
The rapid development of financial technology not only provides a lot of convenience to people's production and life, but also brings a lot of risks to financial security. To prevent financial risks, a better way is to build an accurate warning model before the financial risk occurs, not to find a solution after the outbreak of the risk. In the past decade, deep learning has made amazing achievements in the fields, such as image recognition, natural language processing. Therefore, some researchers try to apply deep learning methods to financial risk prediction and most of the results are satisfactory. The main work of this paper is to review the predecessors' work of deep learning for financial risk prediction according to three prominent characteristics of financial data: heterogeneity, multi-source, and imbalance. We first briefly introduced some classical deep learning models as the model basis of financial risk prediction. Then we analyzed the reasons for these characteristics of financial data. Meanwhile, we studied the differences of commonly used deep learning models according to different data characteristics. Finally, we pointed out some open issues with research significance in this field and suggested the future implementations that might be feasible.
Citation: Kuashuai Peng, Guofeng Yan. A survey on deep learning for financial risk prediction[J]. Quantitative Finance and Economics, 2021, 5(4): 716-737. doi: 10.3934/QFE.2021032
The rapid development of financial technology not only provides a lot of convenience to people's production and life, but also brings a lot of risks to financial security. To prevent financial risks, a better way is to build an accurate warning model before the financial risk occurs, not to find a solution after the outbreak of the risk. In the past decade, deep learning has made amazing achievements in the fields, such as image recognition, natural language processing. Therefore, some researchers try to apply deep learning methods to financial risk prediction and most of the results are satisfactory. The main work of this paper is to review the predecessors' work of deep learning for financial risk prediction according to three prominent characteristics of financial data: heterogeneity, multi-source, and imbalance. We first briefly introduced some classical deep learning models as the model basis of financial risk prediction. Then we analyzed the reasons for these characteristics of financial data. Meanwhile, we studied the differences of commonly used deep learning models according to different data characteristics. Finally, we pointed out some open issues with research significance in this field and suggested the future implementations that might be feasible.

| [1] |
Ahmadi Z, Martens P, Koch C, et al. (2018) Towards Bankruptcy Prediction: Deep Sentiment Mining to Detect Financial Distress from Business Management Reports. 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA): 293–302. doi: 10.1109/DSAA.2018.00040

|
| [2] |
Aljawazneh H, Mora AM, García-Sánchez P, et al. (2021) Comparing the Performance of Deep Learning Methods to Predict Companies' Financial Failure. IEEE Access 9: 97010–97038. doi: 10.1109/ACCESS.2021.3093461
|
| [3] |
Antweiler W, Frank MZ (2004) Is All That Talk Just Noise? The Information Content of Internet Stock Message Boards. J Financ 59: 1259–1294. doi: 10.1111/j.1540-6261.2004.00662.x
|
| [4] |
Baek Y, Kim HY (2018) ModAugNet: A new forecasting framework for stock market index value with an overfitting prevention LSTM module and a prediction LSTM module. Expert Syst Appl 113: 457–480. doi: 10.1016/j.eswa.2018.07.019
|
| [5] |
Bahmani-Oskooee M, Saha S (2019) On the effects of policy uncertainty on stock prices: an asymmetric analysis. Quant Financ Econ 3: 412–424. doi: 10.3934/QFE.2019.2.412
|
| [6] |
Baranoff EG, Brockett P, Sager TW (2019) Was the U.S. life insurance industry in danger of systemic risk by using derivative hedging prior to the 2008 financial crisis? Quant Financ Econ 3: 145–164. doi: 10.3934/QFE.2019.1.145
|
| [7] |
Becerra-Vicario R, Alaminos D, Aranda E, et al. (2020) Deep Recurrent Convolutional Neural Network for Bankruptcy Prediction: A Case of the Restaurant Industry. Sustainability 12: 5180. doi: 10.3390/su12125180
|
| [8] |
Buxton E, Kriz K, Cremeens M, et al. (2019) An Auto Regressive Deep Learning Model for Sales Tax Forecasting from Multiple Short Time Series. 2019 18th IEEE International Conference on Machine Learning and Applications (ICMLA), 1359–1364. doi: 10.1109/ICMLA.2019.00221
|
| [9] | Cao Y, Shao Y, Zhang H (2021) Study on early warning of E-commerce enterprise financial risk based on deep learning algorithm. Electron Commer Res. |
| [10] | Cao M, Qiu G, Lin X (2021) Research on big data financial risk behavior prediction based on deep learning. J Xinyang Agri Forestry Univ 31: 119–122. |
| [11] |
Castelvecchi D (2016) Can we open the black box of AI? Nature News 538: 20–23. doi: 10.1038/538020a
|
| [12] | Chen G, Ju C, Peng X (2018) The Knn-smote-lstm based credit card fraud risk detection network model (in Chinese). Zhejiang: Zhejiang Gongshang University. |
| [13] | Cohen S (2021) The basics of machine learning: strategies and techniques, In: Cohen S. Editor, Artificial Intelligence and Deep Learning in Pathology, Amsterdam: Elsevier, 13–40. |
| [14] | Davis D (2019) AI Unleashes the Power of Unstructured Data, 2019. Available from: https://www.cio.com/article/3406806/ai-unleashes-the-power-of-unstructured-data.html. |
| [15] | Devlin J, Chang MW, Lee K, et al. (2018) Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv: 1810.04805. |
| [16] | Erica (2019) Introduction to the Fundamentals of Panel Data, 2019. Available from: http://www.aptech.com/blog/introduction-to-the-fundamentals-of-panel-data. |
| [17] |
Feng W, Guan N, Li Y, et al. (2017) Audio visual speech recognition with multimodal recurrent neural networks. 2017 International Joint Conference on Neural Networks (IJCNN): 681–688. doi: 10.1109/IJCNN.2017.7965918
|
| [18] |
Fischer T, Krauss C (2018) Deep learning with long short-term memory networks for financial market predictions. Eur J Oper Res 270: 654–669. doi: 10.1016/j.ejor.2017.11.054
|
| [19] | González-Carvajal S, Garrido-Merchán EC (2020) Comparing BERT against traditional machine learning text classification. arXiv preprint arXiv: 1911.03829. |
| [20] | Gopika P, Sowmya V, Gopalakrishnan EA, et al. (2020) Transferable approach for cardiac disease classification using deep learning, In: Agarwal B, Balas VE, Jain LC, et al. Editors, Deep Learning Techniques for Biomedical and Health Informatics, Cham: Springer, 285–303. |
| [21] |
Havierniková K, Kordoš M (2019) The SMEs' perception of financial risks in the context of cluster cooperation. Quant Financ Econ 3: 586–607. doi: 10.3934/QFE.2019.3.586
|
| [22] | Haykin S (2000) Neural Networks: A Guided Tour, In: Sinha NK, Gupta MM. Editors, Soft Computing and Intelligent Systems: Theory and Applications, New York: Academic Press, 71–80. |
| [23] |
He K, Ji L, Tso GKF, et al. (2018) Forecasting Exchange Rate Value at Risk using Deep Belief Network Ensemble based Approach. Procedia Comput Sci 139: 25–32. doi: 10.1016/j.procs.2018.10.213
|
| [24] | Hiew JZG, Huang X, Mou H, et al. (2019) BERT-based financial sentiment index and LSTM-based stock return predictability. arXiv preprint arXiv: 1906.09024. |
| [25] |
Hosaka T (2019) Bankruptcy prediction using imaged financial ratios and convolutional neural networks. Expert Syst Appl 117: 287–299. doi: 10.1016/j.eswa.2018.09.039
|
| [26] |
Hsieh TJ, Hsiao HF, Yeh WC (2011) Forecasting stock markets using wavelet transforms and recurrent neural networks: An integrated system based on artificial bee colony algorithm. Appl Soft Comput 11: 2510–2525. doi: 10.1016/j.asoc.2010.09.007
|
| [27] |
Jan C (2021) Financial Information Asymmetry: Using Deep Learning Algorithms to Predict Financial Distress. Symmetry 13: 443. doi: 10.3390/sym13030443
|
| [28] |
Jan C (2021) Detection of Financial Statement Fraud Using Deep Learning for Sustainable Development of Capital Markets under Information Asymmetry. Sustainability 13: 9879. doi: 10.3390/su13179879
|
| [29] |
Jang Y, Jeong I, Cho YK (2020) Business Failure Prediction of Construction Contractors Using a LSTM RNN with Accounting, Construction Market, and Macroeconomic Variables. J Manage Eng 36: 04019039. doi: 10.1061/(ASCE)ME.1943-5479.0000733
|
| [30] |
Jiang M, Liu J, Zhang L, et al. (2020) An improved Stacking framework for stock index prediction by leveraging tree-based ensemble models and deep learning algorithms. Phys A 541: 122272. doi: 10.1016/j.physa.2019.122272
|
| [31] |
Jiang W (2021) Applications of deep learning in stock market prediction: recent progress. Expert Syst Appl 184: 115537. doi: 10.1016/j.eswa.2021.115537
|
| [32] |
Kim A, Yang Y, Lessmann S, et al. (2020) Can deep learning predict risky retail investors? A case study in financial risk behavior forecasting. Eur J Oper Res 283: 217–234. doi: 10.1016/j.ejor.2019.11.007
|
| [33] |
Kim SH, Kim D (2014) Investor sentiment from internet message postings and the predictability of stock returns. J Econ Behav Organ 107: 708–729. doi: 10.1016/j.jebo.2014.04.015
|
| [34] |
Lang M, Stice-Lawrence L (2015) Textual analysis and international financial reporting: Large sample evidence. J Account Econ 60: 110–135. doi: 10.1016/j.jacceco.2015.09.002
|
| [35] |
Lecun Y, Bottou L, Bengio Y, et al. (1998) Gradient-based learning applied to document recognition. Proceed IEEE 86: 2278–2324. doi: 10.1109/5.726791
|
| [36] |
Leo M, Sharma S, Maddulety K (2019) Machine learning in banking risk management: A literature review. Risks 7: 29. doi: 10.3390/risks7010029
|
| [37] |
Li S, Shi W, Wang J, et al. (2021) A Deep Learning-Based Approach to Constructing a Domain Sentiment Lexicon: a Case Study in Financial Distress Prediction. Inf Process Manage 58: 102673. doi: 10.1016/j.ipm.2021.102673
|
| [38] |
Linsmeier TJ, Pearson ND (2000) Value at Risk. Financ Anal J 56: 47–67. doi: 10.2469/faj.v56.n2.2343
|
| [39] |
Liu K, Luo C, Li Z (2019) Investigating the risk spillover from crude oil market to BRICS stock markets based on Copula-POT-CoVaR models. Quant Financ Econ 3: 754–771. doi: 10.3934/QFE.2019.4.754
|
| [40] | Lv H (2019) International experience and enlightenment of financial foundation database construction. Financ Perspect J, 67–74. |
| [41] |
Ma X, Lv S (2019) Financial credit risk prediction in internet finance driven by machine learning. Neural Comput Appl 31: 8359–8367. doi: 10.1007/s00521-018-3963-6
|
| [42] |
Mai F, Tian S, Lee C, et al. (2019) Deep learning models for bankruptcy prediction using textual disclosures. Eur J Oper Res 274: 743–758. doi: 10.1016/j.ejor.2018.10.024
|
| [43] |
Nicola M, Alsafi Z, Sohrabi C, et al. (2020) The socio-economic implications of the coronavirus pandemic (COVID-19): A review. Int J Surg 78: 185–193. doi: 10.1016/j.ijsu.2020.04.018
|
| [44] | Nisha SS, Sathik MM, Meeral MN (2021) Application, algorithm, tools directly related to deep learning, In: Balas VE, Mishra BK, Kumar R. Editors, Handbook of Deep Learning in Biomedical Engineering, Amsterdam: Elsevier, 61–84. |
| [45] |
Ozbayoglu AM, Gudelek MU, Sezer OB (2020) Deep learning for financial applications: A survey. Appl Soft Comput 93: 106384. doi: 10.1016/j.asoc.2020.106384
|
| [46] |
Peng Y, Wang G, Kou G, et al. (2011) An empirical study of classification algorithm evaluation for financial risk prediction. Appl Soft Comput 11: 2906–2915. doi: 10.1016/j.asoc.2010.11.028
|
| [47] |
Qu Y, Quan P, Lei M, et al. (2019) Review of bankruptcy prediction using machine learning and deep learning techniques. Procedia Comput Sci 162: 895–899. doi: 10.1016/j.procs.2019.12.065
|
| [48] | Reimers C, Requena-Mesa C (2020) Deep Learning—an Opportunity and a Challenge for Geo- and Astrophysics, In: Škoda P, Adam F. Editors, Knowledge Discovery in Big Data from Astronomy and Earth Observation, Amsterdam: Elsevier, 251–265. |
| [49] | Roshan S, Srivathsan G, Deepak K, et al. (2020) Violence Detection in Automated Video Surveillance: Recent Trends and Comparative Studies, In: Peter D, Alavi AH, Javadi B, et al. Editors, The Cognitive Approach in Cloud Computing and Internet of Things Technologies for Surveillance Tracking Systems, Amsterdam: Elsevier, 157–171. |
| [50] |
Sezer OB, Gudelek MU, Ozbayoglu AM (2020) Financial time series forecasting with deep learning: A systematic literature review: 2005–2019. Appl Soft Comput 90: 106181. doi: 10.1016/j.asoc.2020.106181
|
| [51] | Sirignano J, Sadhwani A, Giesecke K (2016) Deep learning for mortgage risk. arXiv preprint arXiv: 1607.02470. |
| [52] | Skryjomski P, Krawczyk B (2017) Influence of minority class instance types on SMOTE imbalanced data oversampling. Proc Machine Learn Res 74: 7–21. |
| [53] |
Smiti S, Soui M (2020) Bankruptcy Prediction Using Deep Learning Approach Based on Borderline SMOTE. Infor Syst Front 22: 1067–1083. doi: 10.1007/s10796-020-10031-6
|
| [54] | Song Y, Cai W (2021) Visual feature representation in microscopy image classification, In: Chen M. Editor, Computer Vision for Microscopy Image Analysis, Amsterdam: Elsevier, 73–100. |
| [55] |
Song Y, Peng Y (2019) A MCDM-Based Evaluation Approach for Imbalanced Classification Methods in Financial Risk Prediction. IEEE Access 7: 84897–84906. doi: 10.1109/ACCESS.2019.2924923
|
| [56] | Sousa MG, Sakiyama K, Rodrigues LS, et al. (2019) BERT for Stock Market Sentiment Analysis. 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI): 1597–1601. |
| [57] |
Sukharev OS (2020) Structural analysis of income and risk dynamics in models of economic growth. Quant Financ Econ 4: 1–18. doi: 10.3934/QFE.2020001
|
| [58] |
Tserng HP, Chen PC, Huang WH, et al. (2014) Prediction of default probability for construction firms using the logit model. J Civil Eng Manage 20: 247–255. doi: 10.3846/13923730.2013.801886
|
| [59] |
Tsukioka Y, Yanagi J, Takada T (2018) Investor sentiment extracted from internet stock message boards and IPO puzzles. Int Rev Econ Financ 56: 205–217. doi: 10.1016/j.iref.2017.10.025
|
| [60] | Wang J, Xin F, Zhang W (2019) Research on bank green credit risk evaluation based on BP Neural Network (in Chinese). Jinan: University of Jinan. |
| [61] |
Wang KJ, Adrian AM, Chen KH, et al. (2015). A hybrid classifier combining Borderline-SMOTE with AIRS algorithm for estimating brain metastasis from lung cancer: A case study in Taiwan. Comput Methods Programs Biomed 119: 63–76. doi: 10.1016/j.cmpb.2015.03.003
|
| [62] | Wang Q, Yi B, Xie Y, et al. (2003) The hardware structure design of perceptron with FPGA implementation. 2003 IEEE International Conference on Systems, Man and Cybernetics, 762–767. |
| [63] |
Wang W, Liu M, Zhang Y, et al. (2019) Financial numeral classification model based on BERT. NTCIR 2019: NII Testbeds and Community for Information Access Research, 193–204. doi: 10.1007/978-3-030-36805-0_15
|
| [64] | Woo S, Lee CL (2018) Decision boundary formation of deep convolution networks with ReLU. 2018 IEEE 16th Intl Conf on Dependable, Autonomic and Secure Computing, 885–888. |
| [65] | Wyrobek J (2018) Predicting Bankruptcy at Polish Companies: A Comparison of Selected Machine Learning and Deep Learning Algorithms. Zeszyty Naukowe Uniwersytetu Ekonomicznego w Krakowie, 41–60. |
| [66] | Xiao J, Wang L, Li N, et al. (2021) Research on perceptual cognitive technology and its application in financial risk warning. CAAI Trans Intell Syst 16: 941–961. |
| [67] |
Xing Y, Lv C, Wang H, et al. (2019) Driver Lane Change Intention Inference for Intelligent Vehicles: Framework, Survey, and Challenges. IEEE Trans Vehicular Technol 68: 4377–4390. doi: 10.1109/TVT.2019.2903299
|
| [68] |
Yang X, Mao S, Gao H, et al. (2019) Novel Financial Capital Flow Forecast Framework Using Time Series Theory and Deep Learning: A Case Study Analysis of Yu'e Bao Transaction Data. IEEE Access 7: 70662–70672. doi: 10.1109/ACCESS.2019.2919189
|
| [69] | Yu SL, Li Z (2018) Forecasting Stock Price Index Volatility with LSTM Deep Neural Network, In: Tavana M, Patnaik S. Editors, Recent Developments in Data Science and Business Analytics, Cham: Springer Nature, 265–272. |
| [70] | Yu X (2017) Machine learning application in online lending risk prediction. arXiv preprint arXiv: 1707.04831. |
| [71] | Zhang H (2020) A forecasting method of short-term stock volatility based on deep learning. Modern Mark (Business Edition) 05: 179–181. |
| [72] |
Zhao D, Ding J, Chai S (2018) Systemic financial risk prediction using least squares support vector machines. Modern Phys Lett B 32: 1850183. doi: 10.1142/S021798491850183X
|
| [73] | Zhao J (2020) Corporate Financial Risk Prediction Based on Embedded System and Deep Learning. Microprocess Microsy, 103405. |
| [74] |
Zhou L (2013) Performance of corporate bankruptcy prediction models on imbalanced dataset: The effect of sampling methods. Knowledge-Based Syst 41: 16–25. doi: 10.1016/j.knosys.2012.12.007
|
| [75] | Zhou X (2017) Holding the bottom line of avoiding systemic financial risks, 2017. Available From: http://cpc.people.com.cn/n1/2017/1122/c64094-29660265.html. |




Figures(5) / Tables(3)

Kuashuai Peng, Guofeng Yan. A survey on deep learning for financial risk prediction[J]. Quantitative Finance and Economics, 2021, 5(4): 716-737. doi: 10.3934/QFE.2021032







 DownLoad:
DownLoad: