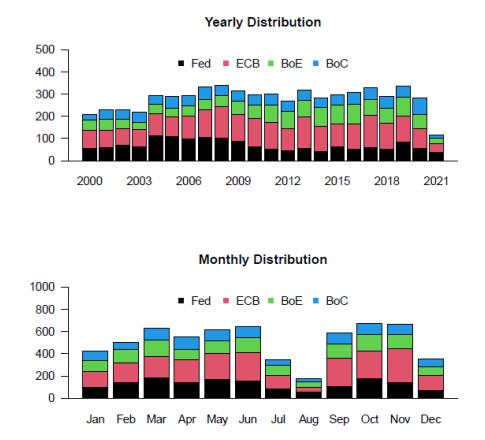
Central banks communication has lately become an important tool to guide expectations and its impact on the economy has been acknowledged by the literature. Nowadays central banks speeches face an increasing variety of topics, which are not discriminated by text analysis. In this paper we build a topic-weighted central bank sentiment index as a combination of machine learning and text analysis techniques to investigate large datasets. First, we develop a methodological framework to grid search the best Latent Dirichlet Allocation (LDA) model to uncover the latent topics in central banks' speeches and releases published between 2000 and 2021. Then, we build a topic-specific sentiment index based on dictionary techniques. Next, we summarise the results in a topic-weighted Central Bank Sentiment Index (CBSIw) for the Bank of Canada (BoC), the Bank of England (BoE), the European Central Bank (ECB) and the Federal Reserve (Fed). We find that the main common driver of the CBSIw is the monetary policy topic, followed by macroprudential policy and payments and settlements. We also uncover bank-specific topics and topics related to new challenges, for example innovation and climate change. Moreover, we find that the CBSIw decreases after the Great Recession, signalling a worsening in sentiment, as well as during the COVID-19 crisis. Finally, we employ a probit regression to further assess the predictive power of our monetary policy topic-specific index. We find that the indicator helps predicting future changes in policy rate, corroborating the evidence that central banks communication signals future monetary policy decisions.
Citation: Maria Paola Priola, Annalisa Molino, Giacomo Tizzanini, Lea Zicchino. The informative value of central banks talks: a topic model application to sentiment analysis[J]. Data Science in Finance and Economics, 2022, 2(3): 181-204. doi: 10.3934/DSFE.2022009
Central banks communication has lately become an important tool to guide expectations and its impact on the economy has been acknowledged by the literature. Nowadays central banks speeches face an increasing variety of topics, which are not discriminated by text analysis. In this paper we build a topic-weighted central bank sentiment index as a combination of machine learning and text analysis techniques to investigate large datasets. First, we develop a methodological framework to grid search the best Latent Dirichlet Allocation (LDA) model to uncover the latent topics in central banks' speeches and releases published between 2000 and 2021. Then, we build a topic-specific sentiment index based on dictionary techniques. Next, we summarise the results in a topic-weighted Central Bank Sentiment Index (CBSIw) for the Bank of Canada (BoC), the Bank of England (BoE), the European Central Bank (ECB) and the Federal Reserve (Fed). We find that the main common driver of the CBSIw is the monetary policy topic, followed by macroprudential policy and payments and settlements. We also uncover bank-specific topics and topics related to new challenges, for example innovation and climate change. Moreover, we find that the CBSIw decreases after the Great Recession, signalling a worsening in sentiment, as well as during the COVID-19 crisis. Finally, we employ a probit regression to further assess the predictive power of our monetary policy topic-specific index. We find that the indicator helps predicting future changes in policy rate, corroborating the evidence that central banks communication signals future monetary policy decisions.

| [1] |
Apel M, Grimaldi MB (2014) How informative are central bank minutes? Review Econ 65: 53-76.https://doi.org/10.1515/roe-2014-0104 doi: 10.1515/roe-2014-0104

|
| [2] |
Armelius H, Bertsch C, Hull I, et al. (2020) Spread the word: International spillovers from central bank communication. J Int Money Financ 103: 102116.https://doi.org/10.1016/j.jimonfin.2019.102116 doi: 10.1016/j.jimonfin.2019.102116
|
| [3] | Baeza-Yates R, Ribeiro-Neto B (1999) Modern information retrieval, 463. ACM press New York. |
| [4] |
Benamar H, Foucault T, Vega C (2021) Demand for information, uncertainty, and the response of us treasury securities to news. Rev Financ Stud 347: 3403-3455. https://doi.org/10.1093/rfs/hhaa072 doi: 10.1093/rfs/hhaa072
|
| [5] |
Bennani H, Fanta N, Gertler P, et al. (2020) Does central bank communication signal future monetary policy in a (post)-crisis era? the case of the ecb. J Int Money Financ 104: 102167. https://doi.org/10.1016/j.jimonfin.2020.102167 doi: 10.1016/j.jimonfin.2020.102167
|
| [6] |
Birz G, Lott Jr JR (2011) The effect of macroeconomic news on stock returns: New evidence from newspaper coverage. J Bank Finance 35: 2791-2800. https://doi.org/10.1016/j.jbankfin.2011.03.006 doi: 10.1016/j.jbankfin.2011.03.006
|
| [7] | Blei DM, Ng AY, Jordan MI (2003) Latent dirichlet allocation. J Mach Learn Res 3: 993-1022. |
| [8] | Carboni M, Farina V, Previati DA(2020) Ecb and fed governors' speeches: A topic modeling analysis (2007-2019). In Banking and Beyond, Springer, 9-25. |
| [9] | Correa R, Garud K, Londono JM, et al. (2017) Constructing a dictionary for financial stability. Board Governors Fed Reserve System, Washington, DC. https://doi.org/10.17016/2573-2129.33 |
| [10] | Cour-Thimann P (2020) Interest rate setting and communication at the ecb. http://dx.doi.org/10.2139/ssrn.3654147 |
| [11] | Dincer NN, Eichengreen B (2013) Central bank transparency and independence: updates and new measures. http://dx.doi.org/10.2139/ssrn.2579544 |
| [12] | Gelman A, Hill J (2006) Data analysis using regression and multilevel/hierarchical models. Cambridge university press. |
| [13] |
Griffiths TL, Steyvers M (2004) Finding scientific topics. P NATL A SCI INDIA B 101: 5228-5235. https://doi.org/10.1073/pnas.030775210 doi: 10.1073/pnas.030775210
|
| [14] | Grün B, Hornik K (2011) topicmodels: An r package for fitting topic models. J Stat Software 40: 1-30. http://www.jstatsoft.org/v40/i13 |
| [15] |
Hansen S, McMahon M, Prat A (2018) Transparency and deliberation within the fomc: a computational linguistics approach. Q J Econ 133: 801-870. https://doi.org/10.1093/qje/qjx045 doi: 10.1093/qje/qjx045
|
| [16] |
Hayo B, Neuenkirch M (2010) Do federal reserve communications help predict federal funds target rate decisions? J Macroecon 32: 1014-1024. https://doi.org/10.1016/j.jmacro.2010.06.003 doi: 10.1016/j.jmacro.2010.06.003
|
| [17] | Kalman RE (1960). A new approach to linear filtering and prediction problems" transaction of the asme journal of basic. https://doi.org/10.1115/1.3662552 |
| [18] | Keida M, Takeda Y (2018) The arts of central bank communication: A topic analysis on words of the bank of japan s governors. AEA Annual Conference. |
| [19] | Leskovec J, Rajaraman A, Ullman JD (2020). Mining of massive data sets. Cambridge university press. |
| [20] |
Logsdon BA, Hoffman GE, Mezey JG(2010) A variational bayes algorithm for fast and accurate multiple locus genome-wide association analysis. BMC Bioinformatics 11: 1-13. https://doi.org/10.1186/1471-2105-11-58 doi: 10.1186/1471-2105-11-58
|
| [21] |
Loughran T, McDonald B (2011). When is a liability not a liability? textual analysis, dictionaries, and 10-ks. J Financ 66: 35-65. https://doi.org/10.1111/j.1540-6261.2010.01625.x doi: 10.1111/j.1540-6261.2010.01625.x
|
| [22] | McFadden D (1974) Conditional logit analysis of qualitative choice behavior. Front Economet 50: 105-142. |
| [23] |
Navarro DJ, Griffiths TL, Steyvers M, et al. (2006) Modeling individual differences using dirichlet processes. J Math Psychol 50: 101-122. https://doi.org/10.1016/j.jmp.2005.11.006 doi: 10.1016/j.jmp.2005.11.006
|
| [24] |
Picault M, Renault T (2017) Words are not all created equal: A new measure of ecb communication. J Int Money Financ 79: 136-156. https://doi.org/10.1016/j.jimonfin.2017.09.005 doi: 10.1016/j.jimonfin.2017.09.005
|
| [25] | Priola MP, Lorenzini P, Tizzanini G, et al. (2021) Measuring central banks' sentiment and its spillover effects with a network approach. http://dx.doi.org/10.2139/ssrn.3764004 |
| [26] | Röder M, Both A, Hinneburg A (2015) Exploring the space of topic coherence measures. In Proceedings of the eighth ACM international conference on Web search and data mining 399-408. https://doi.org/10.1145/2684822.2685324 |
| [27] |
Rosa C (2009) Forecasting the direction of policy rate changes: The importance of ecb words. Econ Notes 38, 39-66. https://doi.org/10.1111/j.1468-0300.2009.00209.x doi: 10.1111/j.1468-0300.2009.00209.x
|
| [28] |
Shapiro AH, Sudhof M, Wilson DJ (2020). Measuring news sentiment. J Econom. https://doi.org/10.1016/j.jeconom.2020.07.053 doi: 10.1016/j.jeconom.2020.07.053
|
| [29] | Silge J, Robinson D (2017) Text mining with R: A tidy approach. "O'Reilly Media, Inc.". |
| [30] |
Silva JS, Cardoso F (2001) The chow-lin method using dynamic models. Econ model 18: 269-280. https://doi.org/10.1016/S0264-9993(00)00039-0 doi: 10.1016/S0264-9993(00)00039-0
|
| [31] |
Swanson ET, Williams JC (2014) Measuring the effect of the zero lower bound on medium-and longer-term interest rates. Am Econ Rev 104: 3154-3185. https://doi.org/10.1257/aer.104.10.3154 doi: 10.1257/aer.104.10.3154
|
| [32] |
Tumala MM, Omotosho BS (2019) A text mining analysis of central bank monetary policy communication in nigeria. CBN J Appl Stat 10. http://dx.doi.org/10.2139/ssrn.3545508 doi: 10.2139/ssrn.3545508
|
| [33] | Witmer J, Yang J (2015) Estimating canada's effective lower bound. Technical report, Bank of Canada. |
| [34] |
Wu JC, Xia FD (2016). Measuring the macroeconomic impact of monetary policy at the zero lower bound. J Money, Credit Banking 48: 253-291. https://doi.org/10.1111/jmcb.12300 doi: 10.1111/jmcb.12300
|
| [35] | Zipf G (1936) The psycho-biology of language, routledge, london. https://doi.org/10.2307/408930 |
 DSFE-02-03-009-s001.pdf DSFE-02-03-009-s001.pdf |
 |

















Figures(18) / Tables(14)
Maria Paola Priola, Annalisa Molino, Giacomo Tizzanini, Lea Zicchino. The informative value of central banks talks: a topic model application to sentiment analysis[J]. Data Science in Finance and Economics, 2022, 2(3): 181-204. doi: 10.3934/DSFE.2022009







 DownLoad:
DownLoad: