Citation: Elena Kotenkova, Dagmara Bataeva, Mikhail Minaev, Elena Zaiko. Application of EvaGreen for the assessment of Listeria monocytogenes АТСС 13932 cell viability using flow cytometry[J]. AIMS Microbiology, 2019, 5(1): 39-47. doi: 10.3934/microbiol.2019.1.39

| [1] |
Díaz M, Herrero M, García LA, et al. (2010) Application of flow cytometry to industrial microbial bioprocesses. Biochem Eng J 48: 385–407. doi: 10.1016/j.bej.2009.07.013

|
| [2] |
Yagüe P, Manteca A, Simon A, et al. (2010) New method for monitoring programmed cell death and differentiation in submerged Streptomyces cultures. Appl Environ Microb 76: 3401–3404. doi: 10.1128/AEM.00120-10
|
| [3] |
Berney M, Hammes F, Bosshard F, et al. (2007) Assessment and interpretation of bacterial viability by using the LIVE/DEAD BacLight Kit in combination with flow cytometry. Appl Environ Microb 73: 3283–3290. doi: 10.1128/AEM.02750-06
|
| [4] |
Stiefel P, Schmidt-Emrich S, Maniura-Weber K, et al. (2015) Critical aspects of using bacterial cell viability assays with the fluorophores SYTO9 and propidium iodide. BMC Microbiol 15: 36. doi: 10.1186/s12866-015-0376-x
|
| [5] | Osés SM, Pascual-Maté A, Fuente D, et al. (2015) Comparison of methods to determine antibacterial activity of honeys against Staphylococcus aureus. NJAS-Wagen J Life Sc 78: 29–33. |
| [6] | Uddhav SB, Sivagurunathan MS (2016) Antibiotic susceptibility testing: A review on current practices. Int J Pharm 6: 11–17. |
| [7] | Nayef A (2016) Determination of minimum inhibitory concentrations (MICs) of antibacterial agents for bacteria isolated from malva. MOJ Proteom Bioinf 3: 7‒9. |
| [8] |
Balouiri M, Sadiki M, Ibnsouda SK (2016) Methods for in vitro evaluating antimicrobial activity: A review. J Pharm Anal 6: 71–79. doi: 10.1016/j.jpha.2015.11.005
|
| [9] |
Dewanjee S, Gangopadhyay M, Bhattacharya N, et al. (2015) Bioautography and its scope in the field of natural product chemistry. J Pharm Anal 5: 75–84. doi: 10.1016/j.jpha.2014.06.002
|
| [10] |
Choma IM, Grzelak EM (2011) Bioautography detection in thin-layer chromatography. J Chromatogr A 1218: 2684–2691. doi: 10.1016/j.chroma.2010.12.069
|
| [11] |
Syal K, Mo M, Yu H, et al. (2017) Current and emerging techniques for antibiotic susceptibility tests. Theranostics 7: 1795–1805. doi: 10.7150/thno.19217
|
| [12] |
Feng J, Wang T, Zhang S, et al. (2014) An optimized SYBR Green I/PI assay for rapid viability assessment and antibiotic susceptibility testing for Borrelia burgdorferi. PLoS One 9: e111809. doi: 10.1371/journal.pone.0111809
|
| [13] | Safety Report for EvaGreen® dye, A summary of mutagenicity and environmental safety test results from three independent laboratories, Biotium, 2013. Available from: https://biotium.com/wp-content/uploads/2013/07/EvaGreen-safety-report.pdf. |
| [14] |
Chiaraviglio L, Kirby JE (2014) Evaluation of impermeant, DNA-binding dye fluorescence as a real-time readout of eukaryotic cell toxicity in a high throughput screening format. Assay Drug Dev Techn 12: 219–228. doi: 10.1089/adt.2014.577
|
| [15] | Silhavy TJ, Kahne D, Walker S (2010) The bacterial cell envelope. CSH Perspect Biol 2: a000414. |
| [16] | Rouzina I, Bloomfield VA (1999) Heat capacity effects on the melting of DNA. 1. General aspects. Biophys J 77: 3242–3251. |
| [17] |
Yang W (2011) Nucleases: Diversity of structure, function and mechanism. Q Rev Biophys 44: 1–93. doi: 10.1017/S0033583510000181
|
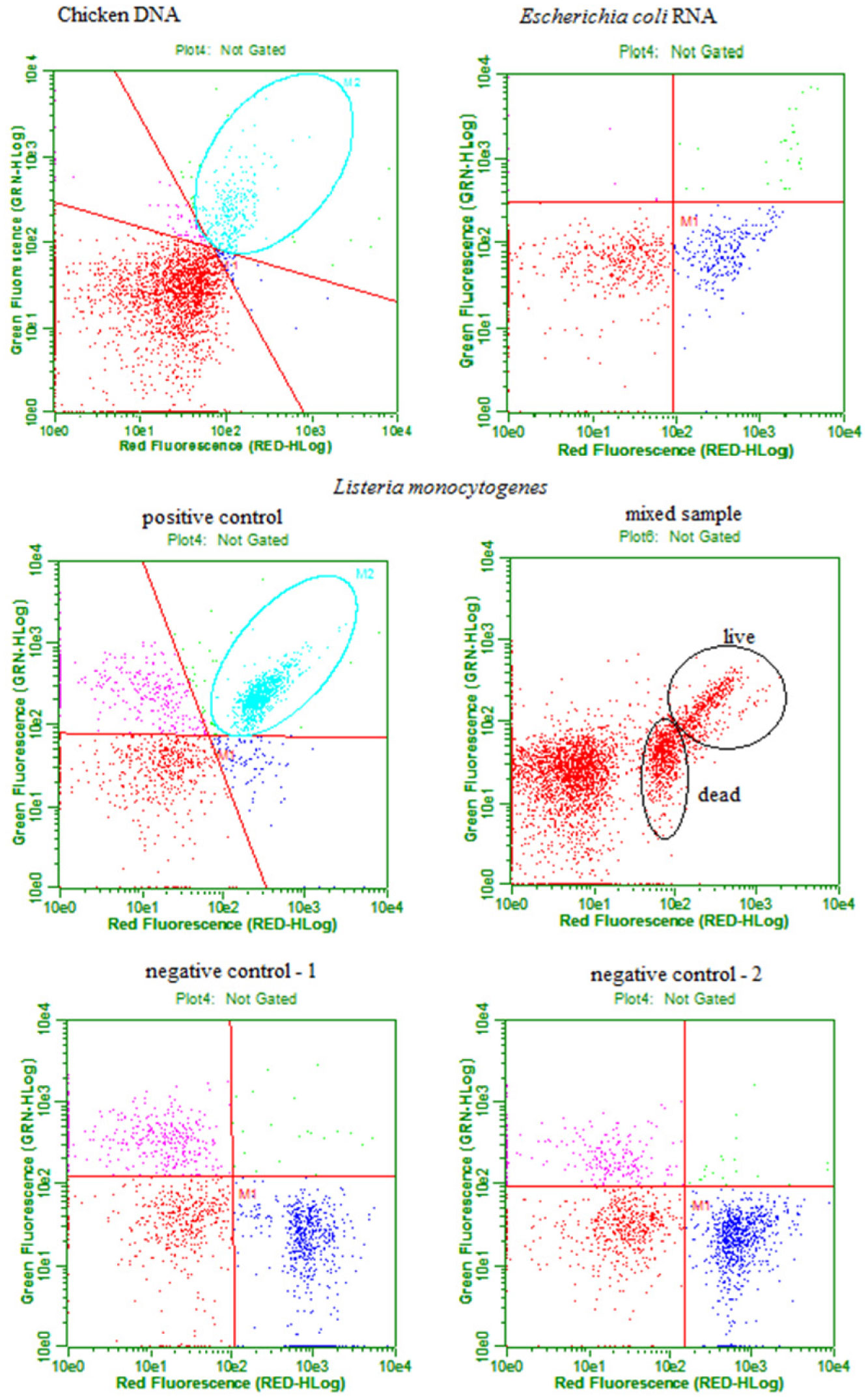
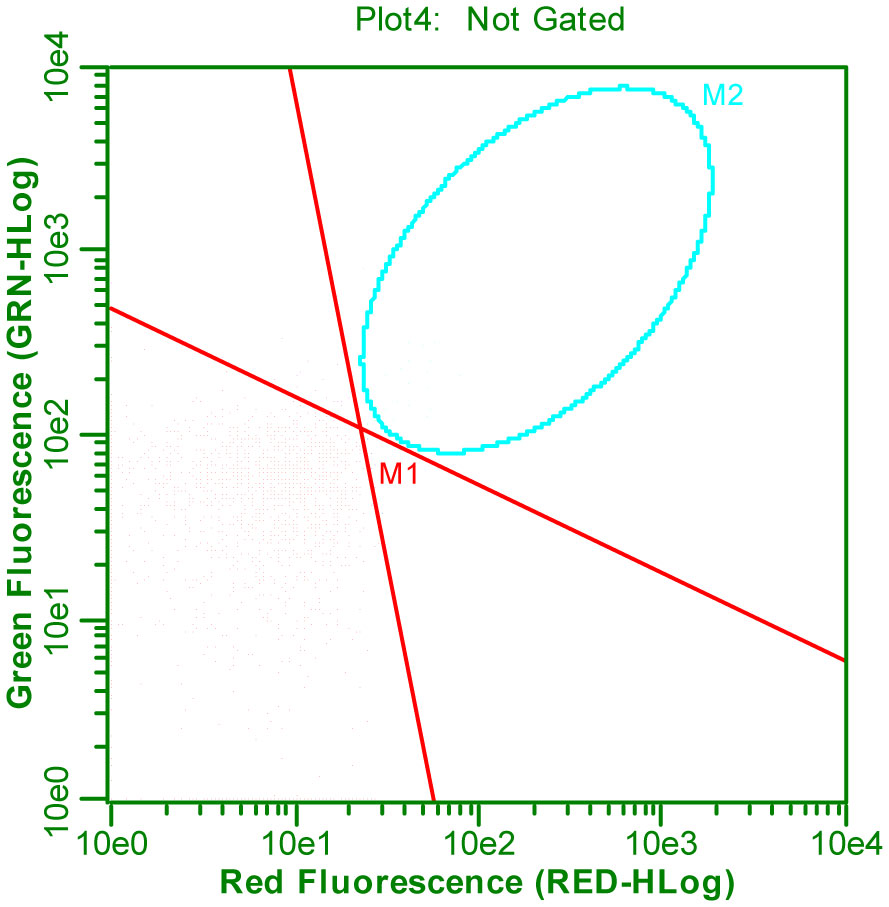
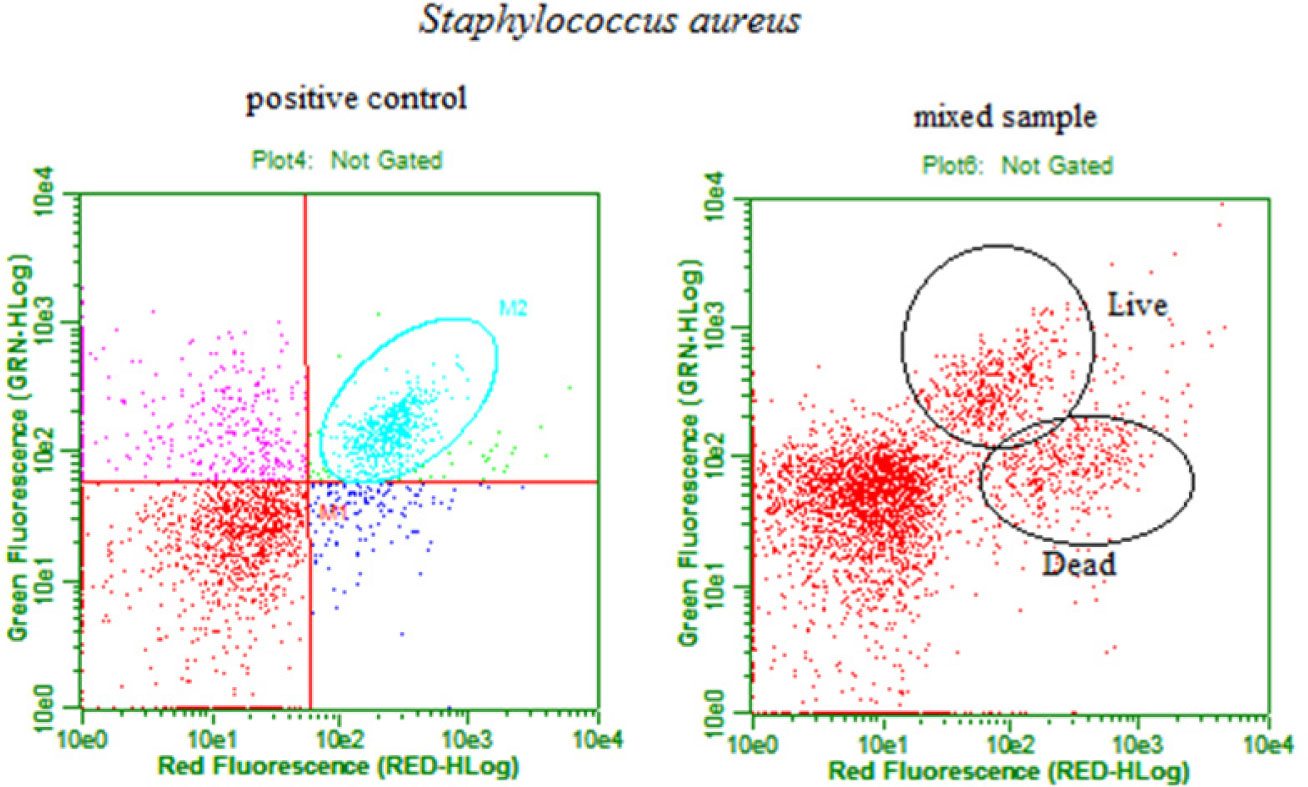
Figures(3) / Tables(1)

Elena Kotenkova, Dagmara Bataeva, Mikhail Minaev, Elena Zaiko. Application of EvaGreen for the assessment of Listeria monocytogenes АТСС 13932 cell viability using flow cytometry[J]. AIMS Microbiology, 2019, 5(1): 39-47. doi: 10.3934/microbiol.2019.1.39







 DownLoad:
DownLoad: