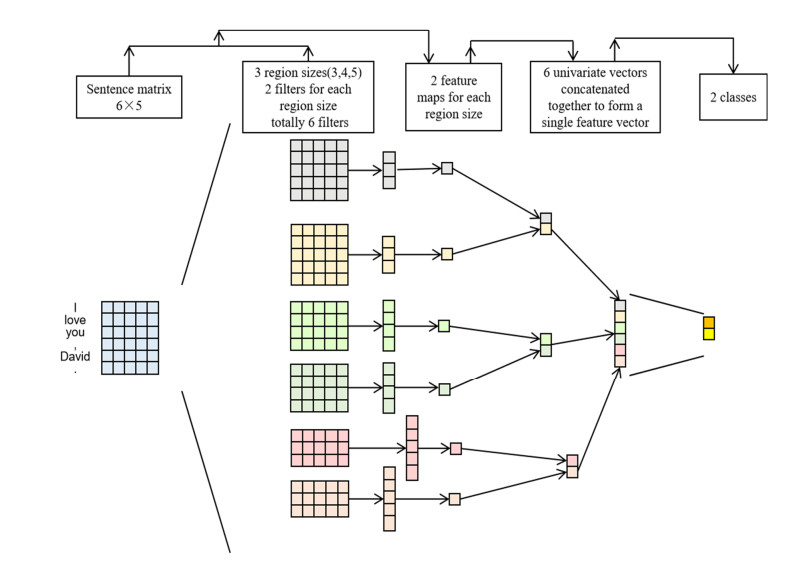
The automatic text summarization task faces great challenges. The main issue in the area is to identify the most informative segments in the input text. Establishing an effective evaluation mechanism has also been identified as a major challenge in the area. Currently, the mainstream solution is to use deep learning for training. However, a serious exposure bias in training prevents them from achieving better results. Therefore, this paper introduces an extractive text summarization model based on a graph matrix and advantage actor-critic (GA2C) method. The articles were pre-processed to generate a graph matrix. Based on the states provided by the graph matrix, the decision-making network made decisions and sent the results to the evaluation network for scoring. The evaluation network got the decision results of the decision-making network and then scored them. The decision-making network modified the probability of the action based on the scores of the evaluation network. Specifically, compared with the baseline reinforcement learning-based extractive summarization (Refresh) model, experimental results on the CNN/Daily Mail dataset showed that the GA2C model led on Rouge-1, Rouge-2 and Rouge-A by 0.70, 9.01 and 2.73, respectively. Moreover, we conducted multiple ablation experiments to verify the GA2C model from different perspectives. Different activation functions and evaluation networks were used in the GA2C model to obtain the best activation function and evaluation network. Two different reward functions (Set fixed reward value for accumulation (ADD), Rouge) and two different similarity matrices (cosine, Jaccard) were combined for the experiments.
Citation: Senqi Yang, Xuliang Duan, Xi Wang, Dezhao Tang, Zeyan Xiao, Yan Guo. Extractive text summarization model based on advantage actor-critic and graph matrix methodology[J]. Mathematical Biosciences and Engineering, 2023, 20(1): 1488-1504. doi: 10.3934/mbe.2023067
The automatic text summarization task faces great challenges. The main issue in the area is to identify the most informative segments in the input text. Establishing an effective evaluation mechanism has also been identified as a major challenge in the area. Currently, the mainstream solution is to use deep learning for training. However, a serious exposure bias in training prevents them from achieving better results. Therefore, this paper introduces an extractive text summarization model based on a graph matrix and advantage actor-critic (GA2C) method. The articles were pre-processed to generate a graph matrix. Based on the states provided by the graph matrix, the decision-making network made decisions and sent the results to the evaluation network for scoring. The evaluation network got the decision results of the decision-making network and then scored them. The decision-making network modified the probability of the action based on the scores of the evaluation network. Specifically, compared with the baseline reinforcement learning-based extractive summarization (Refresh) model, experimental results on the CNN/Daily Mail dataset showed that the GA2C model led on Rouge-1, Rouge-2 and Rouge-A by 0.70, 9.01 and 2.73, respectively. Moreover, we conducted multiple ablation experiments to verify the GA2C model from different perspectives. Different activation functions and evaluation networks were used in the GA2C model to obtain the best activation function and evaluation network. Two different reward functions (Set fixed reward value for accumulation (ADD), Rouge) and two different similarity matrices (cosine, Jaccard) were combined for the experiments.

| [1] |
G. Erkan, D. R. Radev, Lexrank, Graph-based lexical centrality as salience in text summarization, J. Artif. Intell. Res., 22 (2004), 457–479. https://doi.org/10.1613/jair.1523 doi: 10.1613/jair.1523

|
| [2] |
D. R. Radev, H. Jing, M. Styś, D. Tam, Centroid-based summarization of multiple documents, Inf. Process. Manage., 40 (2004), 919–938. https://doi.org/10.1016/j.ipm.2003.10.006 doi: 10.1016/j.ipm.2003.10.006
|
| [3] | S. Li, D. Lei, P. Qin, W. Y. Wang, Deep reinforcement learning with distributional semantic rewards for abstractive summarization, preprint, arXiv: 1909.00141. https://doi.org/10.48550/arXiv.1909.00141 |
| [4] | A. See, P. J. Liu, C. D. Manning, Get to the point: summarization with pointer-generator networks, preprint, arXiv: 1704.04368. https://doi.org/10.48550/arXiv.1704.04368 |
| [5] |
H. P. Luhn, The automatic creation of literature abstracts, IBM J. Res. Dev., 2 (1958), 159–165. https://doi.org/10.1147/rd.22.0159 doi: 10.1147/rd.22.0159
|
| [6] | D. Radev, T. Allison, S. Blair-Goldensohn, J. Blitzer, Z. Zhang, MEAD—a platform for multidocument multilingual text summarization, in 4th International Conference on Language Resources and Evaluation, (2004), 699–702. |
| [7] | R. Mihalcea, P. Tarau, E. Figa, PageRank on semantic networks, with application to word sense disambiguation, in COLING 2004: Proceedings of the 20th International Conference on Computational Linguistics, (2004), 1126–1132. |
| [8] | S. Ma, Z. H. Deng, Y. Yang, An unsupervised multi-document summarization framework based on neural document model, in Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, (2016), 1514–1523. |
| [9] | J. Cheng, L. Dong, M. Lapata, Long short-term memory-networks for machine reading, preprint, arXiv: 1601.06733. https://doi.org/10.48550/arXiv.1601.06733 |
| [10] | R. Nallapati, F. Zhai, B. Zhou, Summarunner: A recurrent neural network based sequence model for extractive summarization of documents, in Thirty-first AAAI Conference on Artificial Intelligence, 2017. |
| [11] | A. Jadhav, V. Rajan, Extractive summarization with swap-net: Sentences and words from alternating pointer networks, in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, 1 (2018), 142–151, https://doi.org/10.18653/v1/P18-1014. |
| [12] | Q. Zhou, N. Yang, F. Wei, S. Huang, M. Zhou, T. Zhao, Neural document summarization by jointly learning to score and select sentences, preprint, arXiv: 1807.02305. https://doi.org/10.48550/arXiv.1807.02305 |
| [13] | D. Wang, P. Liu, Y. Zheng, X. Qiu, X. Huang, Heterogeneous graph neural networks for extractive document summarization, preprint, arXiv: 2004.12393. https://doi.org/10.48550/arXiv.2004.12393 |
| [14] | M. Zhong, P. Liu, Y. Chen, D. Wang, X. Qiu, X. Huang, Extractive summarization as text matching, preprint, arXiv: 2004.08795. https://doi.org/10.48550/arXiv.2004.08795 |
| [15] | Y. Dong, Z. Li, M. Rezagholizadeh, J. C. K. Cheung, EditNTS: An neural programmer-interpreter model for sentence simplification through explicit editing, preprint, arXiv: 1906.08104. https://doi.org/10.48550/arXiv.1906.08104 |
| [16] | M. A. Ranzato, S. Chopra, M. Auli, W. Zaremba, Sequence level training with recurrent neural networks, preprint, arXiv: 1511.06732. https://doi.org/10.48550/arXiv.1511.06732 |
| [17] | D. Bahdanau, P. Brakel, K. Xu, A. Goyal, R. Lowe, J. Pineau, et al., An actor-critic algorithm for sequence prediction, preprint, arXiv: 1607.07086. https://doi.org/10.48550/arXiv.1607.07086 |
| [18] | R. Paulus, C. Xiong, R. Socher, A deep reinforced model for abstractive summarization, preprint, arXiv: 1705.04304. https://doi.org/10.48550/arXiv.1705.04304 |
| [19] | S. Narayan, S. B. Cohen, M. Lapata, Ranking sentences for extractive summarization with reinforcement learning, preprint, arXiv: 1802.08636. https://doi.org/10.48550/arXiv.1802.08636 |
| [20] | Y. Mao, Y. Qu, Y. Xie, X. Ren, J. Han, Multi-document summarization with maximal marginal relevance-guided reinforcement learning, preprint, arXiv: 2010.00117. https://doi.org/10.48550/arXiv.2010.00117 |
| [21] | L. Page, S. Brin, R. Motwani, T. Winograd, The Pagerank Citation Ranking: Bringing Order to the Web, Technical Report, Stanford InfoLab, 1998. |
| [22] |
P. Zhang, X. Huang, Y. Wang, C. Jiang, S. He, H. Wang, Semantic similarity computing model based on multi model fine-grained nonlinear fusion, IEEE Access, 9 (2021), 8433–8443. https://doi.org/10.1109/ACCESS.2021.3049378 doi: 10.1109/ACCESS.2021.3049378
|
| [23] | G. Malik, M. Cevik, D. Parikh, A. Basar, Identifying the requirement conflicts in SRS documents using transformer-based sentence embeddings, preprint, arXiv: 2206.13690. https://doi.org/10.48550/arXiv.2206.13690 |
| [24] | Y. Kim, Convolutional neural networks for sentence classification, in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), (2014), 1746–1751. https://doi.org/10.3115/v1/D14-1181 |
| [25] | Y. Zhang, B. Wallace, A sensitivity analysis of (and practitioners' guide to) convolutional neural networks for sentence classification, preprint, arXiv: 1510.03820. https://doi.org/10.48550/arXiv.1510.03820 |
| [26] | C. Y. Lin, F. Och, Looking for a few good metrics: ROUGE and its evaluation, in Ntcir workshop, 2004. |
| [27] |
T. Ma, H. Wang, Y. Zhao, Y. Tian, N. Al-Nabhan, Topic-based automatic summarization algorithm for Chinese short text, Math. Biosci. Eng., 17 (2020), 3582–3600. https://doi.org/10.3934/mbe.2020202 doi: 10.3934/mbe.2020202
|
| [28] | T. Zhang, I. C. Irsan, F. Thung, D. Han, D. Lo, L. Jiang, iTiger: An automatic issue title generation tool, preprint, arXiv: 2206.10811. https://doi.org/10.48550/arXiv.2206.10811 |
| [29] | A. Mullick, A. Nandy, M. N. Kapadnis, S. Patnaik, R. Raghav, R. Kar, An evaluation framework for legal document summarization, preprint, arXiv: 2205.08478. https://doi.org/10.48550/arXiv.2205.08478 |
| [30] |
S. Li, Y. Yan, J. Ren, Y. Zhou, Y. Zhang, A sample-efficient actor-critic algorithm for recommendation diversification, Chin. J. Electron., 29 (2020), 89–96. https://doi.org/10.1049/cje.2019.10.004 doi: 10.1049/cje.2019.10.004
|
| [31] | Project Webpage, Available from: https://github.com/vietnguyen91/Super-mario-bros-A3C-pytorch. |
| [32] | N. Xie, S. Li, H. Ren, Q. Zhai, Abstractive summarization improved by wordnet-based extractive sentences, in CCF International Conference on Natural Language Processing and Chinese Computing, Springer, Cham, (2018), 404–415. https://doi.org/10.1007/978-3-319-99495-6_34 |
| [33] |
K. Yao, L. Zhang, T. Luo, Y. Wu, Deep reinforcement learning for extractive document summarization, Neurocomputing, 284 (2018), 52–62. https://doi.org/10.1016/j.neucom.2018.01.020 doi: 10.1016/j.neucom.2018.01.020
|
| [34] |
J. Tong, Z. Wang, X. Rui, A multi-model-based deep learning framework for short text multiclass classification with the imbalanced and extremely small data set, Comput. Math. Appl., 113 (2022), 34–44. https://doi.org/10.1016/j.camwa.2022.03.005 doi: 10.1016/j.camwa.2022.03.005
|
| [35] |
M. Liu, Z. Cai, J. Chen, Adaptive two-layer ReLU neural network: I. Best least-squares approximation, Comput. Math. Appl., 113 (2021), 34–44. https://doi.org/10.1016/j.camwa.2022.03.005 doi: 10.1016/j.camwa.2022.03.005
|
| [36] |
A. Maniatopoulos, N. Mitianoudis, Learnable Leaky ReLU (LeLeLU): An alternative accuracy-optimized activation function, Information, 12 (2021), 513. https://doi.org/10.3390/info12120513 doi: 10.3390/info12120513
|
| [37] |
B. H. Nayef, S. N. H. S. Abdullah, R. Sulaiman, Z. A. A. Alyasseri, Applications, Optimized leaky ReLU for handwritten Arabic character recognition using convolution neural networks, Multimedia Tools Appl., 81 (2022), 2065–2094. https://doi.org/10.1007/s11042-021-11593-6 doi: 10.1007/s11042-021-11593-6
|
| [38] | S. K. Karn, N. Liu, H. Schuetze, O. J. Farri, Differentiable multi-agent actor-critic for multi-step radiology report summarization, preprint, arXiv: 2203.08257. https://doi.org/10.48550/arXiv.2203.08257 |
| [39] |
Y. Guo, D. Z. Tang, W. Tang, S. Q. Yang, Q. C. Tang, Y. Feng, et al., Agricultural price prediction based on combined forecasting model under spatial-temporal influencing factors, Sustainability, 14 (2022). https://doi.org/10.3390/su141710483. doi: 10.3390/su141710483
|






Figures(7) / Tables(5)

Senqi Yang, Xuliang Duan, Xi Wang, Dezhao Tang, Zeyan Xiao, Yan Guo. Extractive text summarization model based on advantage actor-critic and graph matrix methodology[J]. Mathematical Biosciences and Engineering, 2023, 20(1): 1488-1504. doi: 10.3934/mbe.2023067







 DownLoad:
DownLoad: