Citation: Maureen C. Ashe, Christina L. Ekegren, Anna M. Chudyk, Lena Fleig, Tiffany K. Gill, Dolores Langford, Lydia Martin-Martin, Patrocinio Ariza-Vega. Telerehabilitation for community-dwelling middle-aged and older adults after musculoskeletal trauma: A systematic review[J]. AIMS Medical Science, 2018, 5(4): 316-336. doi: 10.3934/medsci.2018.4.316

| [1] |
Mock C, Cherian MN (2008) The global burden of musculoskeletal injuries: Challenges and solutions. Clin Orthop Relat Res 466: 2306–2316. doi: 10.1007/s11999-008-0416-z

|
| [2] |
Wu D, Zhu X, Zhang S (2018) Effect of home-based rehabilitation for hip fracture: A meta-analysis of randomized controlled trials. J Rehabil Med 50: 481–486. doi: 10.2340/16501977-2328
|
| [3] |
Hirdes JP, Fries BE, Morris JN, et al. (2004) Home care quality indicators (HCQIs) based on the MDS-HC. Gerontologist 44: 665–679. doi: 10.1093/geront/44.5.665
|
| [4] |
Armstrong JJ, Sims-Gould J, Stolee P (2016) Allocation of Rehabilitation Services for Older Adults in the Ontario Home Care System. Physiother Can 68: 346–354. doi: 10.3138/ptc.2014-66
|
| [5] |
Tran D, Davis A, Mcgillis HL, et al. (2012) Comparing Recruitment and Retention Strategies for Rehabilitation Professionals among Hospital and Home Care Employers. Physiother Can 64: 31–41. doi: 10.3138/ptc.2010-43
|
| [6] | Roots RK, Brown H, Bainbridge L, et al. (2014) Rural rehabilitation practice: Perspectives of occupational therapists and physical therapists in British Columbia, Canada. Rural Remote Health 14: 2506. |
| [7] |
Russell TG (2007) Physical rehabilitation using telemedicine. J Telemed Telecare 13: 217–220. doi: 10.1258/135763307781458886
|
| [8] |
Clarke M, Shah A, Sharma U (2011) Systematic review of studies on telemonitoring of patients with congestive heart failure: A meta-analysis. J Telemed Telecare 17: 7–14. doi: 10.1258/jtt.2010.100113
|
| [9] | Laver KE, Schoene D, Crotty M, et al. (2013) Telerehabilitation services for stroke. Cochrane Database Syst Rev 12: CD010255. |
| [10] |
Chen J, Jin W, Zhang XX, et al. (2015) Telerehabilitation Approaches for Stroke Patients: Systematic Review and Meta-analysis of Randomized Controlled Trials. J Stroke Cerebrovasc Dis 24: 2660–2668. doi: 10.1016/j.jstrokecerebrovasdis.2015.09.014
|
| [11] | Reeder B, Chung J, Stevens-Lapsley J (2016) Current Telerehabilitation Research With Older Adults at Home: An Integrative Review. J Gerontol Nurs 42: 15–20. |
| [12] |
Cottrell MA, Galea OA, O'Leary SP, et al. (2017) Real-time telerehabilitation for the treatment of musculoskeletal conditions is effective and comparable to standard practice: A systematic review and meta-analysis. Clin Rehabil 31: 625–638. doi: 10.1177/0269215516645148
|
| [13] |
Le MY, Collins G, Bhandari M, et al. (2015) Outcomes After Hip Fracture Surgery Compared With Elective Total Hip Replacement. JAMA 314: 1159–1166. doi: 10.1001/jama.2015.10842
|
| [14] |
Moher D, Liberati A, Tetzlaff J, et al. (2009) Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. PLoS Med 6: e1000097. doi: 10.1371/journal.pmed.1000097
|
| [15] |
Higgins JP, Altman DG, Gotzsche PC, et al. (2011) The Cochrane Collaboration's tool for assessing risk of bias in randomised trials. BMJ 343: d5928. doi: 10.1136/bmj.d5928
|
| [16] | Higgins JPT, Altman DG, Sterne JAC (2017) Chapter 8: Assessing risk of bias in included studies, In: Higgins JPT, Churchill R, Chandler J, Cumpston MS. Editors, Cochrane Handbook for Systematic Reviews of Interventions version 520 (updated June 2017), Cochrane, Available from: www.training.cochrane.org/handbook. |
| [17] |
Villamar MF, Contreras VS, Kuntz RE, et al. (2013) The reporting of blinding in physical medicine and rehabilitation randomized controlled trials: A systematic review. J Rehabil Med 45: 6–13. doi: 10.2340/16501977-1071
|
| [18] | Avellar SA, Thomas J, Kleinman R, et al. (2016) External Validity: The Next Step for Systematic Reviews? Eval Rev 41: 283–325. |
| [19] |
Michie S, Richardson M, Johnston M, et al. (2013) The behavior change technique taxonomy (v1) of 93 hierarchically clustered techniques: Building an international consensus for the reporting of behavior change interventions. Ann Behav Med 46: 81–95. doi: 10.1007/s12160-013-9486-6
|
| [20] |
Cohen J (1960) A Coefficient of Agreement for Nominal Scales. Eduational Psychol Meas 20: 37–46. doi: 10.1177/001316446002000104
|
| [21] | Bedra M, Finkelstein J (2015) Feasibility of post-acute hip fracture telerehabilitation in older adults. Stud Health Technol Inf 210: 469–473. |
| [22] | Di MM, De ET, Gardin L, et al. (2015) A single postdischarge telephone call by an occupational therapist does not reduce the risk of falling in women after hip fracture: A randomized controlled trial. Eur J Phys Rehabil Med 51: 15–22. |
| [23] | Langford DP, Fleig L, Brown KC, et al. (2015) Back to the future-feasibility of recruitment and retention to patient education and telephone follow-up after hip fracture: A pilot randomized controlled trial. Patient Prefer Adherence 9: 1343–1351. |
| [24] |
O'Halloran PD, Shields N, Blackstock F, et al. (2016) Motivational interviewing increases physical activity and self-efficacy in people living in the community after hip fracture: A randomized controlled trial. Clin Rehabil 30: 1108–1119. doi: 10.1177/0269215515617814
|
| [25] |
Suwanpasu S, Aungsuroch Y, Jitapanya C (2014) Post-surgical physical activity enhancing program for elderly patients after hip fracture: A randomized controlled trial. Asian Biomed 8: 525–532. doi: 10.5372/1905-7415.0804.323
|
| [26] | Tousignant M, Giguere AM, Morin M, et al. (2014) In-home telerehabilitation for proximal humerus fractures: A pilot study. Int J Telerehabil 6: 31–37. |
| [27] |
Landis JR, Koch GG (1977) The Measurement of Observer Agreement for Categorical Data. Biometrics 33: 159–174. doi: 10.2307/2529310
|
| [28] |
Yang YT, Iqbal U, Ching JH, et al. (2015) Trends in the growth of literature of telemedicine: A bibliometric analysis. Comput Methods Programs Biomed 122: 471–479. doi: 10.1016/j.cmpb.2015.09.008
|
| [29] |
Johansson T, Wild C (2011) Telerehabilitation in stroke care-a systematic review. J Telemed Telecare 17: 1–6. doi: 10.1258/jtt.2010.100105
|
| [30] |
Veras M, Kairy D, Rogante M, et al. (2017) Scoping review of outcome measures used in telerehabilitation and virtual reality for post-stroke rehabilitation. J Telemed Telecare 23: 567–587. doi: 10.1177/1357633X16656235
|
| [31] |
Chan C, Yamabayashi C, Syed N, et al. (2016) Exercise Telemonitoring and Telerehabilitation Compared with Traditional Cardiac and Pulmonary Rehabilitation: A Systematic Review and Meta-Analysis. Physiother Can 68: 242–251. doi: 10.3138/ptc.2015-33
|
| [32] |
Frederix I, Vanhees L, Dendale P, et al. (2015) A review of telerehabilitation for cardiac patients. J Telemed Telecare 21: 45–53. doi: 10.1177/1357633X14562732
|
| [33] |
Hwang R, Bruning J, Morris N, et al. (2015) A Systematic Review of the Effects of Telerehabilitation in Patients With Cardiopulmonary Diseases. J Cardiopulm Rehabil Prev 35: 380–389. doi: 10.1097/HCR.0000000000000121
|
| [34] |
Jiang S, Xiang J, Gao X, et al. (2018) The comparison of telerehabilitation and face-to-face rehabilitation after total knee arthroplasty: A systematic review and meta-analysis. J Telemed Telecare 24: 257–262. doi: 10.1177/1357633X16686748
|
| [35] |
Shukla H, Nair SR, Thakker D (2017) Role of telerehabilitation in patients following total knee arthroplasty: Evidence from a systematic literature review and meta-analysis. J Telemed Telecare 23: 339–346. doi: 10.1177/1357633X16628996
|
| [36] |
Amatya B, Galea MP, Kesselring J, et al. (2015) Effectiveness of telerehabilitation interventions in persons with multiple sclerosis: A systematic review. Mult Scler Relat Disord 4: 358–369. doi: 10.1016/j.msard.2015.06.011
|
| [37] | Khan F, Amatya B, Kesselring J, et al. (2015) Telerehabilitation for persons with multiple sclerosis. A Cochrane review. Eur J Phys Rehabil Med 51: 311–325. |
| [38] |
Best A, Greenhalgh T, Lewis S, et al. (2012) Large-system transformation in health care: A realist review. Milbank Q 90: 421–456. doi: 10.1111/j.1468-0009.2012.00670.x
|
| [39] |
Ranhoff AH, Holvik K, Martinsen MI, et al. (2010) Older hip fracture patients: three groups with different needs. BMC Geriatr 10: 65. doi: 10.1186/1471-2318-10-65
|
| [40] |
Irwin J, Carter A (2013) Major trauma patients with musculoskeletal injuries: Rehabilitation pathway inadequacies. Int J Ther Rehabil 20: 376–377. doi: 10.12968/ijtr.2013.20.8.376
|
| [41] |
Greenwald P, Stern ME, Clark S, et al. (2018) Older adults and technology: In telehealth, they may not be who you think they are. Int J Emerg Med 11: 2. doi: 10.1186/s12245-017-0162-7
|
| [42] | Pew Internet and American Life Project, Older adults and the internet, 2004. Available via Pew Internet and American Life Project. Available from: http://www.pewinternet.org/2017/05/17/tech-adoption-climbs-among-older-adults/. Accessed 6 June 2018. |
| [43] |
Nahm ES, Resnick B, Plummer L, et al. (2013) Use of discussion boards in an online hip fracture resource center for caregivers. Orthop Nurs 32: 89–95. doi: 10.1097/NOR.0b013e318289fa22
|
| [44] |
Yamato T, Maher C, Saragiotto B, et al. (2016) Improving completeness and transparency of reporting in clinical trials using the template for intervention description and replication (TIDieR) checklist will benefit the physiotherapy profession. J Man Manip Ther 24: 183–184. doi: 10.1080/10669817.2016.1210343
|
| [45] | Webb TL, Joseph J, Yardley L, et al. (2010) Using the internet to promote health behavior change: A systematic review and meta-analysis of the impact of theoretical basis, use of behavior change techniques, and mode of delivery on efficacy. J Med Int Res 12: e4. |

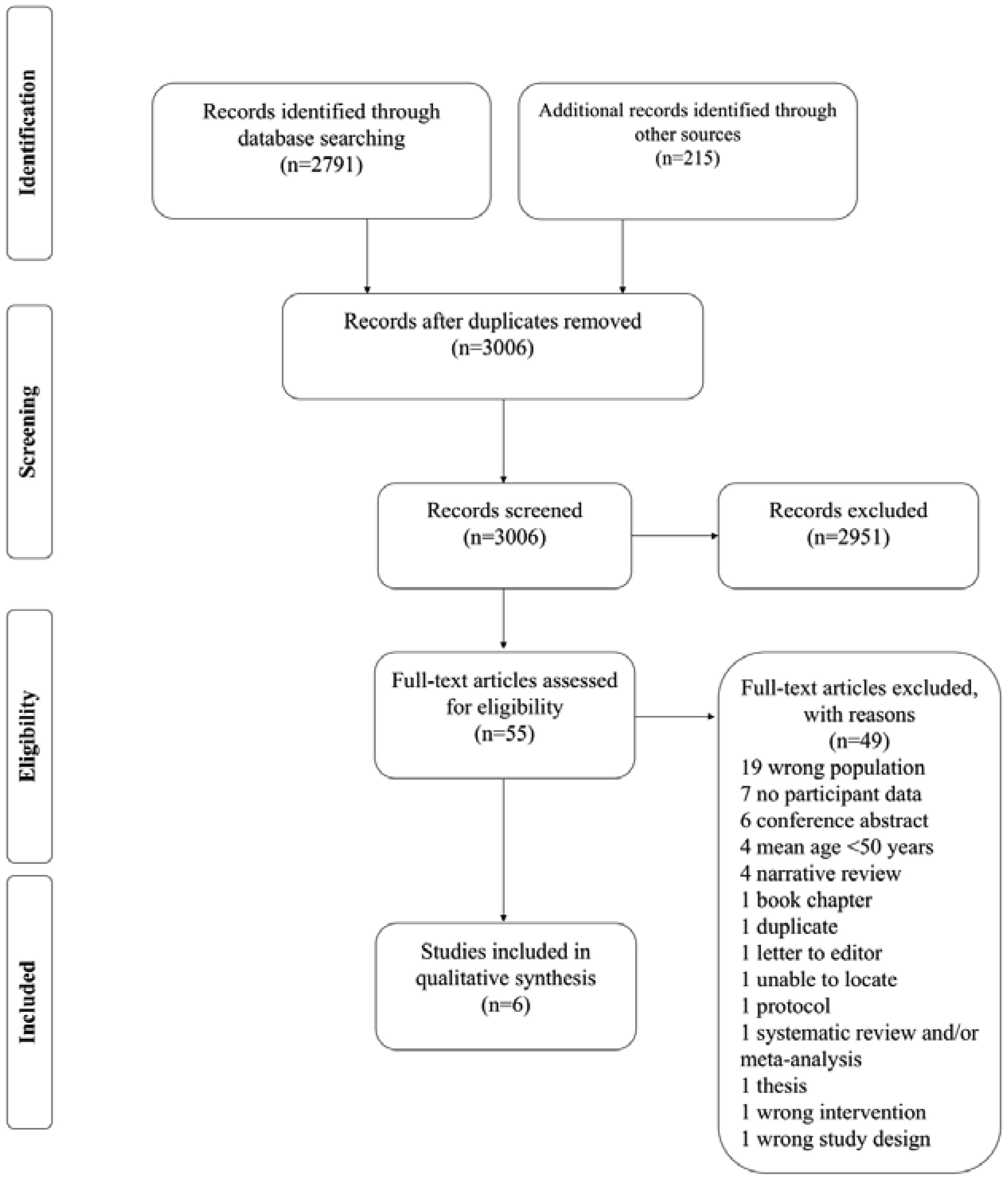
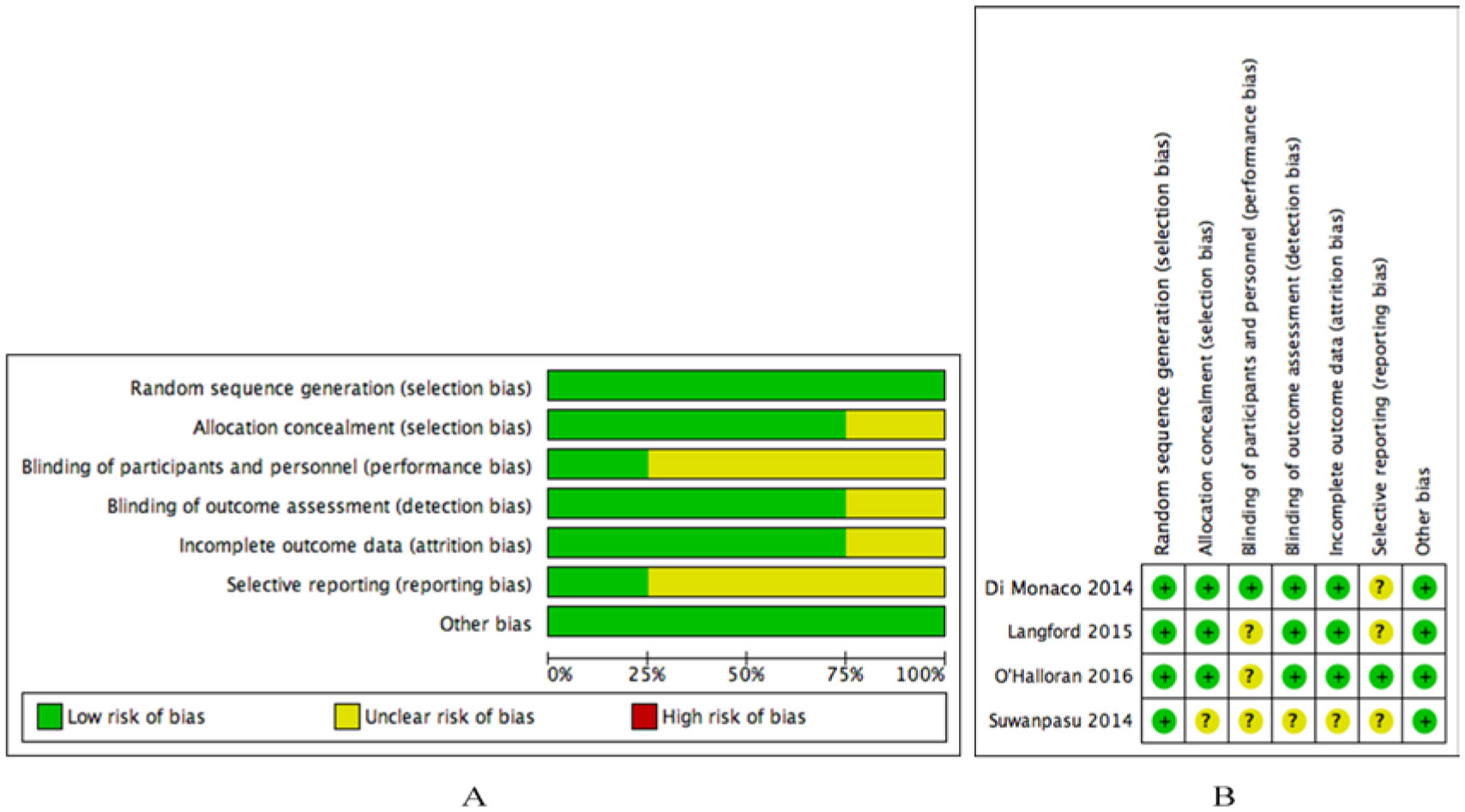
Figures(3) / Tables(4)

Maureen C. Ashe, Christina L. Ekegren, Anna M. Chudyk, Lena Fleig, Tiffany K. Gill, Dolores Langford, Lydia Martin-Martin, Patrocinio Ariza-Vega. Telerehabilitation for community-dwelling middle-aged and older adults after musculoskeletal trauma: A systematic review[J]. AIMS Medical Science, 2018, 5(4): 316-336. doi: 10.3934/medsci.2018.4.316







 DownLoad:
DownLoad: