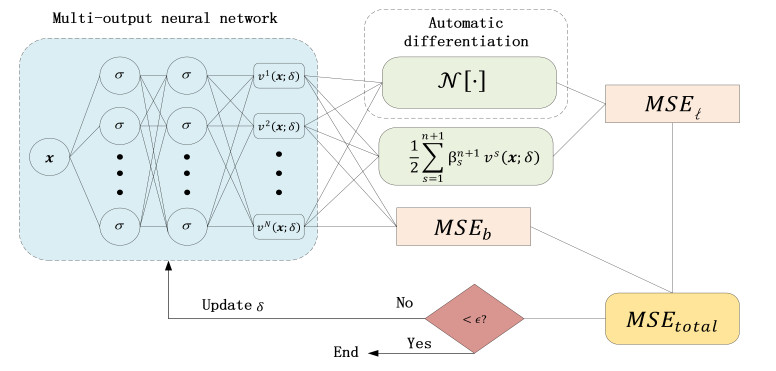
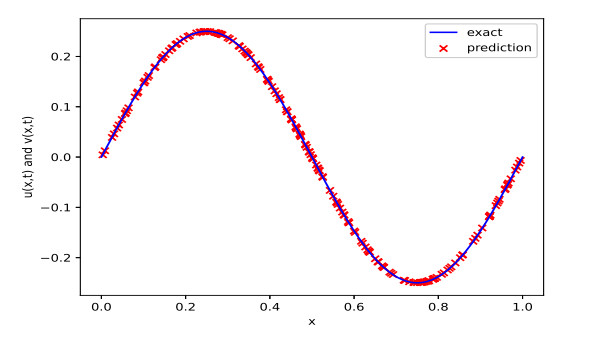
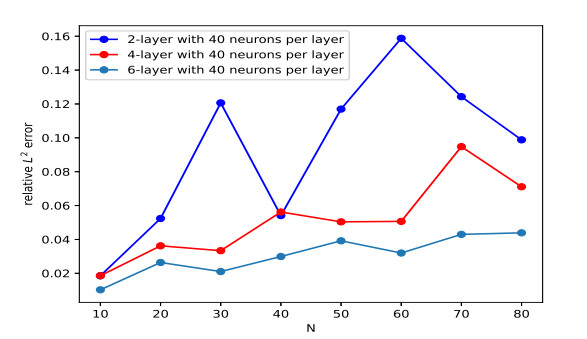
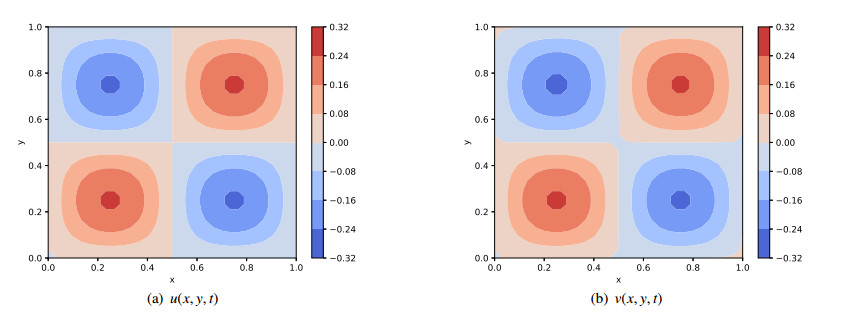
In this article, a physics-informed neural network based on the time difference method is developed to solve one-dimensional (1D) and two-dimensional (2D) nonlinear time distributed-order models. The FBN-$ \theta $, which is constructed by combining the fractional second order backward difference formula (BDF2) with the fractional Newton-Gregory formula, where a second-order composite numerical integral formula is used to approximate the distributed-order derivative, and the time direction at time $ t_{n+\frac{1}{2}} $ is approximated by making use of the Crank-Nicolson scheme. Selecting the hyperbolic tangent function as the activation function, we construct a multi-output neural network to obtain the numerical solution, which is constrained by the time discrete formula and boundary conditions. Automatic differentiation technology is developed to calculate the spatial partial derivatives. Numerical results are provided to confirm the effectiveness and feasibility of the proposed method and illustrate that compared with the single output neural network, using the multi-output neural network can effectively improve the accuracy of the predicted solution and save a lot of computing time.
Citation: Wenkai Liu, Yang Liu, Hong Li, Yining Yang. Multi-output physics-informed neural network for one- and two-dimensional nonlinear time distributed-order models[J]. Networks and Heterogeneous Media, 2023, 18(4): 1899-1918. doi: 10.3934/nhm.2023080
In this article, a physics-informed neural network based on the time difference method is developed to solve one-dimensional (1D) and two-dimensional (2D) nonlinear time distributed-order models. The FBN-$ \theta $, which is constructed by combining the fractional second order backward difference formula (BDF2) with the fractional Newton-Gregory formula, where a second-order composite numerical integral formula is used to approximate the distributed-order derivative, and the time direction at time $ t_{n+\frac{1}{2}} $ is approximated by making use of the Crank-Nicolson scheme. Selecting the hyperbolic tangent function as the activation function, we construct a multi-output neural network to obtain the numerical solution, which is constrained by the time discrete formula and boundary conditions. Automatic differentiation technology is developed to calculate the spatial partial derivatives. Numerical results are provided to confirm the effectiveness and feasibility of the proposed method and illustrate that compared with the single output neural network, using the multi-output neural network can effectively improve the accuracy of the predicted solution and save a lot of computing time.

| [1] | J. Yang, Q. H. Zhu, A local deep learning method for solving high order partial differential equtaions, arXiv: 2103.08915 [Preprint], (2021), [cited 2023 Nov 22]. Available from: https://doi.org/10.48550/arXiv.2103.08915 |
| [2] |
J. Q. Han, A. Jentzen, W. N. E, Solving high-dimensonal partial differential equations using deep learning, Proc. Natl. Acad. Sci. U.S.A., 115 (2018), 8505–8510. https://doi.org/10.1073/pnas.1718942115 doi: 10.1073/pnas.1718942115

|
| [3] |
Y. Li, Z. J. Zhou, S. H. Ying, DeLISA: Deep learning based iteration scheme approximation for solving PDEs, J. Comput. Phys., 451 (2022), 110884. https://doi.org/10.1016/j.jcp.2021.110884 doi: 10.1016/j.jcp.2021.110884
|
| [4] |
X. J. Xu, M. H. Chen, Discovery of subdiffusion problem with noisy data via deep learning, J. Sci. Comput., 92 (2022), 23. https://doi.org/10.1007/s10915-022-01879-8 doi: 10.1007/s10915-022-01879-8
|
| [5] |
M. Raissi, P. Perdikaris, G. E. Karniadakis, Physics-informend neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, J. Comput. Phys., 378 (2019), 686–707. https://doi.org/10.1016/j.jcp.2018.10.045 doi: 10.1016/j.jcp.2018.10.045
|
| [6] |
L. Yuan, Y. Q. Ni, X. Y. Deng, S. Hao, A-PINN: Auxiliary physics informed neural networks for forward and inverse problems of nonlinear integro-differential equations, J. Comput. Phys., 462 (2022), 111260. https://doi.org/10.1016/j.jcp.2022.111260 doi: 10.1016/j.jcp.2022.111260
|
| [7] |
S. N. Lin, Y. Chen, A two-stage physics-informed neural network method based on conserved quantities and applications in localized wave solutions, J. Comput. Phys., 457 (2022), 111053. https://doi.org/10.1016/j.jcp.2022.111053 doi: 10.1016/j.jcp.2022.111053
|
| [8] |
L. Yang, X. H. Meng, G. E. Karniadakis, B-PINNs: Bayesian physics-informed neural networks for forward and inverse PDE problems with noisy data, J. Comput. Phys., 425 (2021), 109913. https://doi.org/10.1016/j.jcp.2020.109913 doi: 10.1016/j.jcp.2020.109913
|
| [9] |
P. Peng, J. G. Pan, H. Xu, X. L. Feng, RPINNs: Rectified-physics informed neural networks for solving stationary partial differential equations, Comput. Fluids., 245 (2022), 105583. https://doi.org/10.1016/j.compfluid.2022.105583 doi: 10.1016/j.compfluid.2022.105583
|
| [10] |
E. Kharazmi, Z. Q. Zhang, G. E. Karniadakis, $hp$-VPINNs: Variational physics-informed neural networks with domain decomposition, Comput. Meth. Appl. Mech. Eng., 374 (2021), 113547. https://doi.org/10.1016/j.cma.2020.113547 doi: 10.1016/j.cma.2020.113547
|
| [11] |
Z. P. Mao, A. D. Jagtap, G. E. Karniadakis, Physics-informed neural networks for high-speed flows, Comput. Meth. Appl. Mech. Eng., 360 (2020), 112789. https://doi.org/10.1016/j.cma.2019.112789 doi: 10.1016/j.cma.2019.112789
|
| [12] |
S. Z. Cai, Z. C. Wang, S. F. Wang, P. Perdikaris, G. E. Karniadakis, Physics-informed neural networks for heat transfer problems, J. Heat Trans., 143 (2021), 060801. https://doi.org/10.1115/1.4050542 doi: 10.1115/1.4050542
|
| [13] |
G. F. Pang, L. Lu, G. E. Karniadakis, fPINNs: Fractional physics-informed neural networks, SIAM J. Sci. Comput., 41 (2019), A2603–A2626. https://doi.org/10.1137/18M12298 doi: 10.1137/18M12298
|
| [14] |
L. Guo, H. Wu, X. C. Yu, T. Zhou, Monte Carlo PINNs: deep learning approach for forward and inverse problems involving high dimensional fractional partial differential equations, Comput. Meth. Appl. Mech. Engrg., 400 (2022), 115523. https://doi.org/10.1016/j.cma.2022.115523 doi: 10.1016/j.cma.2022.115523
|
| [15] |
W. K. Liu, Y. Liu, H. Li, Time difference physics-informed neural network for fractional water wave models, Results Appl. Math., 17 (2023), 100347. https://doi.org/10.1016/j.rinam.2022.100347 doi: 10.1016/j.rinam.2022.100347
|
| [16] |
P. Gatto, J. S. Hesthaven, Numerical approximation of the fractional laplacian via $hp$-finite elements, with an application to image denoising, J. Sci. Comput., 65 (2015), 249–270. https://doi.org/10.1007/s10915-014-9959-1 doi: 10.1007/s10915-014-9959-1
|
| [17] |
E. Barkai, R. Metzler, J. Klafter, From continuous time random walks to the fractional Fokker-Planck equation, Phys. Rev. E, 61 (2000), 132–138. https://doi.org/10.1103/PhysRevE.61.132 doi: 10.1103/PhysRevE.61.132
|
| [18] |
L. Feng, F. Liu, I. Turner, L. Zheng, Novel numerical analysis of multi-term time fractional viscoelastic non-Newtonian fluid models for simulating unsteady MHD Couette flow of a generalized Oldroyd-B fluid, Frac. Calc. Appl. Anal., 21 (2018), 1073–1103. https://doi.org/10.1515/fca-2018-0058 doi: 10.1515/fca-2018-0058
|
| [19] |
S. Vong, Z. B. Wang, A compact difference scheme for a two dimensional fractional Klein-Gordon equation with Neumann boundary conditions, J. Comput. Phys., 274 (2014), 268–282. https://doi.org/10.1016/j.jcp.2014.06.022 doi: 10.1016/j.jcp.2014.06.022
|
| [20] |
G. H. Gao, A. A. Alikhanov, Z. Z. Sun, The temporal second order difference schemes based on the interpolation approximation foe solving the time multi-term and distributed-order fractional sub-diffusion equations, J. Sci. Comput., 73 (2017), 93–121. https://doi.org/10.1007/s10915-017-0407-x doi: 10.1007/s10915-017-0407-x
|
| [21] |
H. Y. Jian, T. Z. Huang, X. M. Gu, X. L. Zhao, Y. L. Zhao, Fast second-order implicit difference schemes for time distributed-order and Riesz space fractional diffusion-wave equations, Comput. Math. Appl., 94 (2021), 136–154. https://doi.org/10.1016/j.camwa.2021.05.003 doi: 10.1016/j.camwa.2021.05.003
|
| [22] |
J. Li, F. Liu, L. Feng, I. Turner, A novel finite volume method for the Riesz space distributed-order advection-diffusion equation, Appl. Math. Model., 46 (2017), 536–553. https://doi.org/10.1016/j.apm.2017.01.065 doi: 10.1016/j.apm.2017.01.065
|
| [23] |
C. Wen, Y. Liu, B. L. Yin, H. Li, J. F. Wang, Fast second-order time two-mesh mixed finite element method for a nonlinear distributed-order sub-diffusion model, Numer. Algor., 88 (2021), 523–553. https://doi.org/10.1007/s11075-020-01048-8 doi: 10.1007/s11075-020-01048-8
|
| [24] |
S. Guo, L. Mei, Z. Zhang, Y. Jiang, Finite difference/spectral-Galerkin method for a two-dimensional distributed-order time-space fractional reaction-diffusion equation, Appl. Math. Lett., 85 (2018), 157–163. https://doi.org/10.1016/j.aml.2018.06.005 doi: 10.1016/j.aml.2018.06.005
|
| [25] |
H. Zhang, F. Liu, X. Jiang, F. Zeng, I. Turner, A Crank-Nicolson ADI Galerkin-Legendre spectral method for the two-dimensional Riesz space distributed-order advection-diffusion equation, Comput. Math. Appl., 76 (2018), 2460–2476. https://doi.org/10.1016/j.camwa.2018.08.042 doi: 10.1016/j.camwa.2018.08.042
|
| [26] |
M. H. Ran, C. J. Zhang, New compact difference scheme for solving the fourth-order time fractional sub-diffusion equation of the distributed order, Appl. Numer. Math., 129 (2018), 58–70. https://doi.org/10.1016/j.apnum.2018.03.005 doi: 10.1016/j.apnum.2018.03.005
|
| [27] |
M. F. Fei, C. M. Huang, Galerkin-Legendre spectral method for the distributed-order time fractional fourth-order partial differential equation, Int. J. Comput. Math., 97 (2020), 1183–1196. https://doi.org/10.1080/00207160.2019.1608968 doi: 10.1080/00207160.2019.1608968
|
| [28] |
F. Fakhar-Izadi, Fully Petrov-Galerkin spectral method for the distributed-order time-fractional fourth-order partial differential equation, Eng. Comput., 37 (2021), 2707–2716. https://doi.org/10.1007/s00366-020-00968-2 doi: 10.1007/s00366-020-00968-2
|
| [29] |
K. Diethelm, N. J. Ford, Numerical analysis for distributed-order differential equations, J. Comput. Appl. Math., 225 (2009), 96–104. https://doi.org/10.1016/j.cam.2008.07.018 doi: 10.1016/j.cam.2008.07.018
|
| [30] |
K. Diethelm, N. J. Ford, Analysis of fractional differential equations, J. Math. Anal. Appl., 265 (2002), 229–248. https://doi.org/10.1006/jmaa.2000.7194 doi: 10.1006/jmaa.2000.7194
|
| [31] |
B. L. Yin, Y. Liu, H. Li, Z. M. Zhang, Finite element methods based on two families of second-order numerical formulas for the fractional Cable model with smooth solutions, J. Sci. Comput., 84 (2020), 2. https://doi.org/10.1007/s10915-020-01258-1 doi: 10.1007/s10915-020-01258-1
|
| [32] |
B. L. Yin, Y. Liu, H. Li, Z. M. Zhang, Two families of second-order fractional numerical formulas and applications to fractional differential equations, Fract. Calc. Appl. Anal., 26 (2023), 1842–1867. https://doi.org/10.1007/s13540-023-00172-1 doi: 10.1007/s13540-023-00172-1
|
| [33] |
Y. LeCun, Y. Bengio, G. Hinton, Deep learning, Nature, 521 (2015), 436–444. https://doi.org/10.1038/nature14539 doi: 10.1038/nature14539
|
| [34] |
H. M. Chen, O. Engkvist, Y. H. Wang, M. Olivecrona, T. Blaschke, The rise of deep learning in drug discovery, Drug Discov. Today, 23 (2018), 1241–1250. https://doi.org/10.1016/j.drudis.2018.01.039 doi: 10.1016/j.drudis.2018.01.039
|
| [35] |
Y. B. Yang, P. Perdikaris, Adversarial uncertainty quantification in physics-informed neural networks, J. Comput. Phys., 394 (2019), 136–152. https://doi.org/10.1016/j.jcp.2019.05.027 doi: 10.1016/j.jcp.2019.05.027
|
| [36] |
B. L. Yin, Y. Liu, H. Li, Z. M. Zhang, On discrete energy dissipation of Maxwell's equations in a Cole-Cole dispersive medium, J. Comput. Math., 41 (2023), 980–1002. https://doi.org/10.4208/jcm.2210-m2021-0257 doi: 10.4208/jcm.2210-m2021-0257
|
| [37] |
J. Li, Y. Huang, Y. Lin, Developing finite element methods for Maxwell's equations in a Cole-Cole dispersive medium, SIAM J. Sci. Comput., 33 (2011), 3153–3174. https://doi.org/10.1137/110827624 doi: 10.1137/110827624
|
| [38] |
W. Wang, H. X. Zhang, X. X. Jiang, X. H. Yang, A high-order and efficient numerical technique for the nonlocal neutron diffusion equation representing neutron transport in a nuclear reactor, Ann. Nucl. Energy., 195 (2024), 110163. https://doi.org/10.1016/j.anucene.2023.110163 doi: 10.1016/j.anucene.2023.110163
|
| [39] |
Q. Q. Tian, X. H. Yang, H. X. Zhang, D. Xu, An implicit robust numerical scheme with graded meshes for the modified Burgers model with nonlocal dynamic properties, Comput. Appl. Math., 42 (2023), 246. https://doi.org/10.1007/s40314-023-02373-z doi: 10.1007/s40314-023-02373-z
|
| [40] |
Z. Y. Zhou, H. X. Zhang, X. H. Yang, $H^1$-norm error analysis of a robust ADI method on graded mesh for three-dimensional subdiffusion problems, Numer. Algor., (2023), 1–19. https://doi.org/10.1007/s11075-023-01676-w doi: 10.1007/s11075-023-01676-w
|
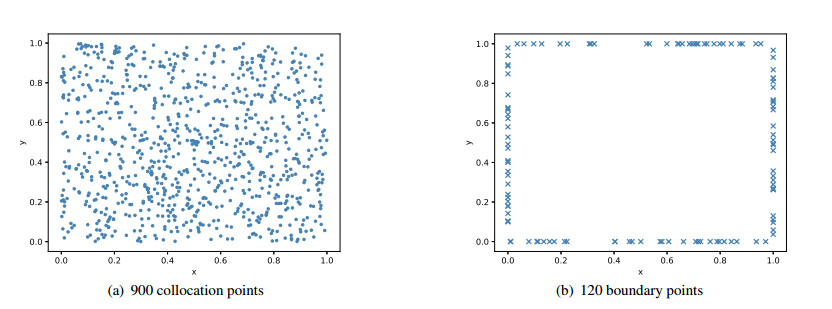
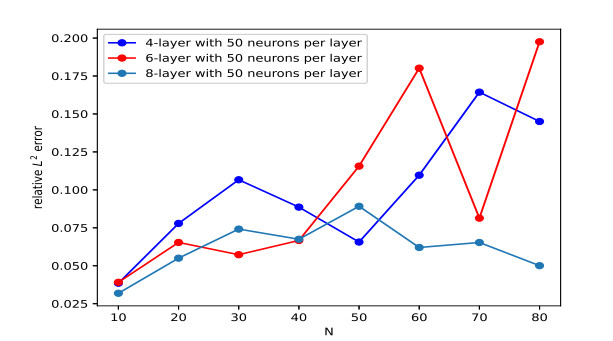
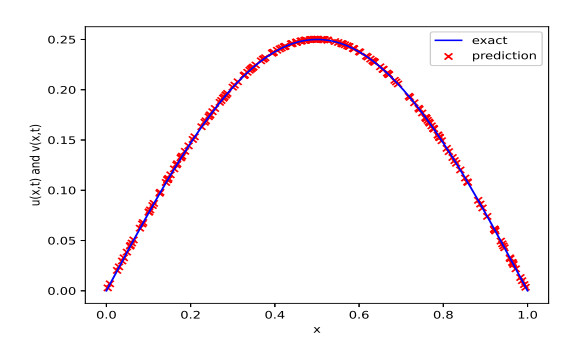
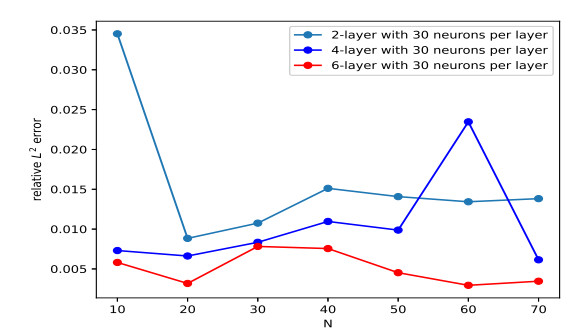

Figures(10) / Tables(9)
Wenkai Liu, Yang Liu, Hong Li, Yining Yang. Multi-output physics-informed neural network for one- and two-dimensional nonlinear time distributed-order models[J]. Networks and Heterogeneous Media, 2023, 18(4): 1899-1918. doi: 10.3934/nhm.2023080







 DownLoad:
DownLoad: