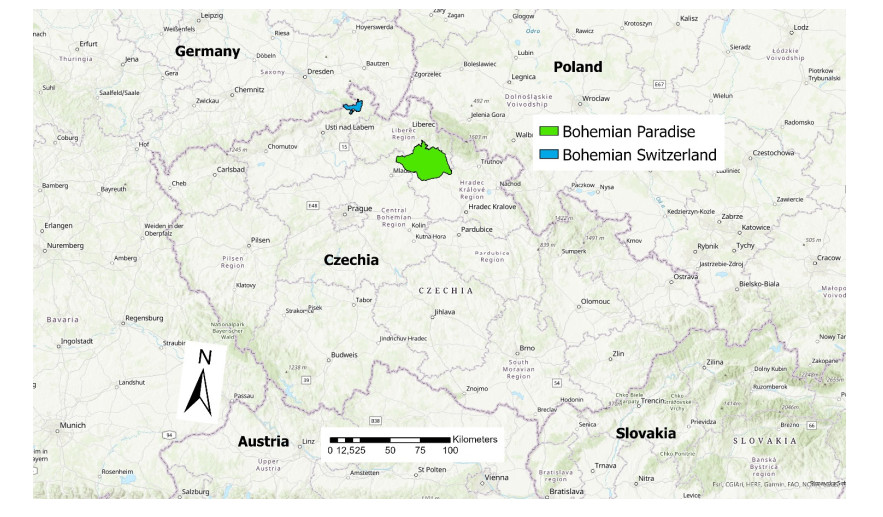
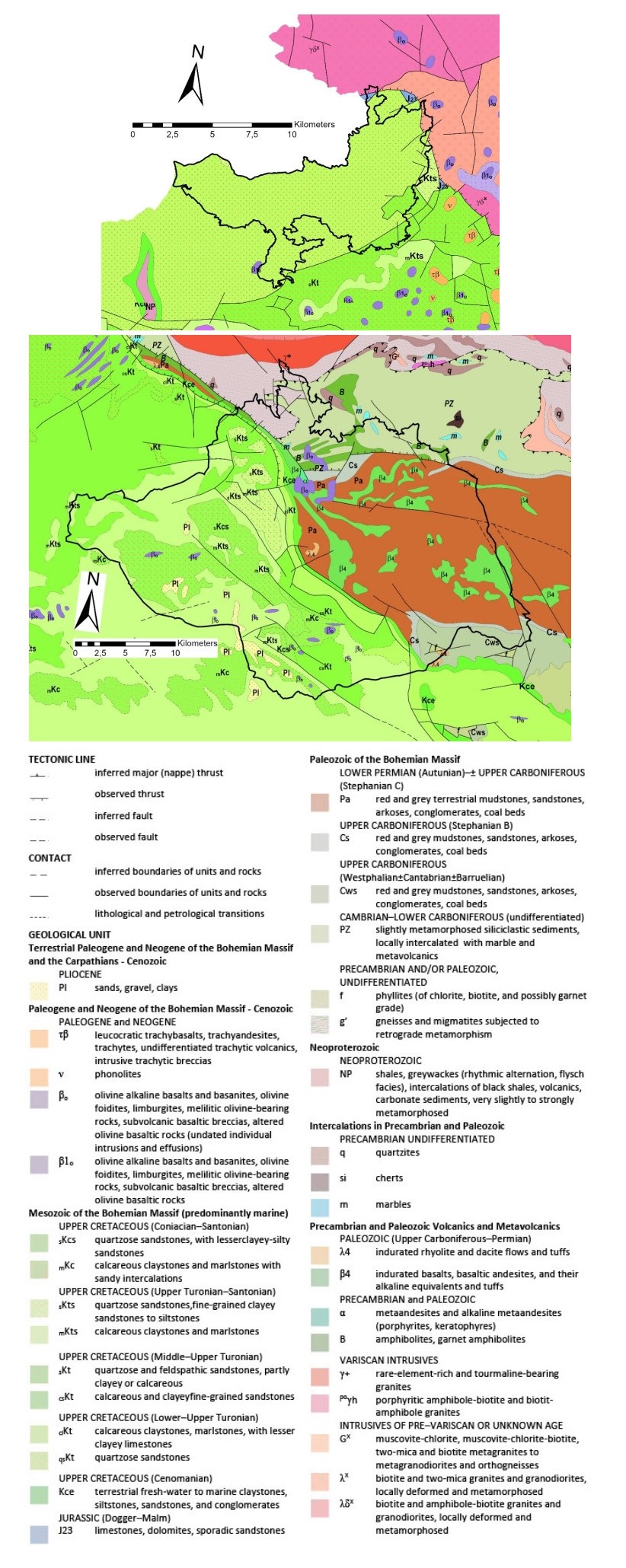
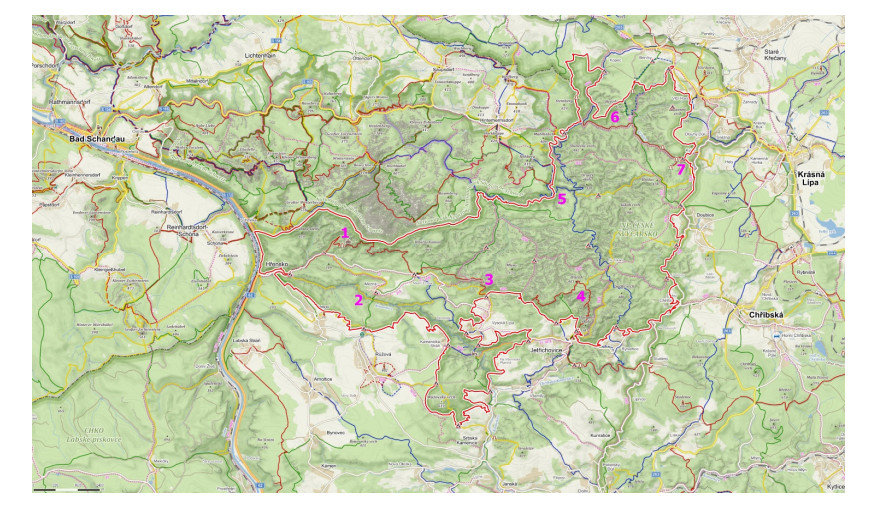
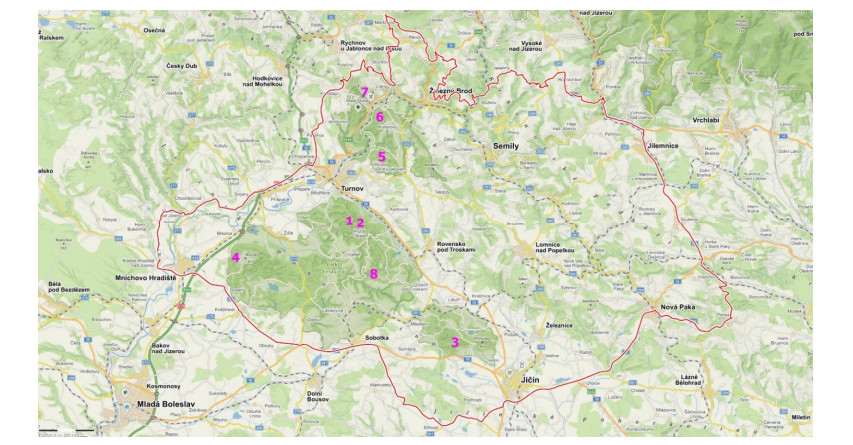
One of the most interesting natural tourist destinations in the Czech Republic are sandstone rocks, located mainly in the Bohemian Cretaceous Basin. Sandstones in these areas create a number of aesthetically valuable geomorphological formations, such as rock towers, gates, windows, overhangs etc. In addition, they provide beautiful views. Regions with a concentration of sandstone rocks are thus among the most visited natural areas in the Czech Republic. Unfortunately, mass tourism also brings negative impacts that negatively affect the condition of sandstone rocks—these are mainly engraving in the rocks, painting or spraying on the rocks, vandalism, pollution by garbage or excrements and destruction of natural rock shapes. However, it is not true that a larger number of visitors automatically means a larger number of negative impacts. This paper analyses the factors that influence the occurrence of the above-mentioned negative impacts in areas of sandstone rocks. The basis for the analysis was mapping of negative impacts in the field, data on traffic to individual geosites, GIS database of business entities in the tourism sector in the area of interest and field survey, aimed at explaining the structure of visitors to individual geosites according to their motivation and preferences. First, data on tourists' motivation and preferences were processed using cluster analysis into their typology. Then, the relationship between the intensity of the occurrence of negative impacts and potential factors—the absolute number of visitors, the distance to a major tourist facility and the type of visitor—was analysed. The results showed that damage to geosites is most affected by some types of visitors and little social control.
Citation: Emil Drápela. Prevention of damage to sandstone rocks in protected areas of nature in northern Bohemia[J]. AIMS Geosciences, 2021, 7(1): 56-73. doi: 10.3934/geosci.2021003
One of the most interesting natural tourist destinations in the Czech Republic are sandstone rocks, located mainly in the Bohemian Cretaceous Basin. Sandstones in these areas create a number of aesthetically valuable geomorphological formations, such as rock towers, gates, windows, overhangs etc. In addition, they provide beautiful views. Regions with a concentration of sandstone rocks are thus among the most visited natural areas in the Czech Republic. Unfortunately, mass tourism also brings negative impacts that negatively affect the condition of sandstone rocks—these are mainly engraving in the rocks, painting or spraying on the rocks, vandalism, pollution by garbage or excrements and destruction of natural rock shapes. However, it is not true that a larger number of visitors automatically means a larger number of negative impacts. This paper analyses the factors that influence the occurrence of the above-mentioned negative impacts in areas of sandstone rocks. The basis for the analysis was mapping of negative impacts in the field, data on traffic to individual geosites, GIS database of business entities in the tourism sector in the area of interest and field survey, aimed at explaining the structure of visitors to individual geosites according to their motivation and preferences. First, data on tourists' motivation and preferences were processed using cluster analysis into their typology. Then, the relationship between the intensity of the occurrence of negative impacts and potential factors—the absolute number of visitors, the distance to a major tourist facility and the type of visitor—was analysed. The results showed that damage to geosites is most affected by some types of visitors and little social control.

| [1] | European Geoparks Network (2000) The EGN Charter. Lesvos. Available from: http://www.europeangeoparks.org/?page_id=357. |
| [2] |
Ruban DA (2010) Quantification of geodiversity and its loss. Proc Geol Assoc 121: 326-333. doi: 10.1016/j.pgeola.2010.07.002

|
| [3] |
Kiernan K (2012) Impacts of War on Geodiversity and Geoheritage: Case Studies of Karst Caves from Northern Laos. Geoheritage 4: 225-247. doi: 10.1007/s12371-012-0063-3
|
| [4] |
AbdelMaksoud KM, Al-Metwaly WM, Ruban DA, et al. (2018) Geological heritage under strong urbanization pressure: El-Mokattam and Abu Roash as examples from Cairo, Egypt. J Afr Earth Sci 141: 86-93. doi: 10.1016/j.jafrearsci.2018.02.008
|
| [5] |
Kong WL, Li YH, Li KL, et al. (2020) Urban Geoheritage Sites Under Strong Anthropogenic Pressure: Example from the Chaohu Lake Region, Hefei, China. Geoheritage 12: 1-24. doi: 10.1007/s12371-020-00440-z
|
| [6] |
Percival IG (2014) Protection and Preservation of Australia's Palaeontological Heritage. Geoheritage 6: 205-216. doi: 10.1007/s12371-014-0106-z
|
| [7] |
Tičar J, Tomić N, Valjavec MB, et al. (2018) Speleotourism in Slovenia: balancing between mass tourism and geoheritage protection. Open Geosci 10: 344-357. doi: 10.1515/geo-2018-0027
|
| [8] |
Cho JN, Woo KS (2018) Proposal for legal protection of the geosites in National Geoparks in Korea. J Geol Soc Korea 54: 237-256. doi: 10.14770/jgsk.2018.54.3.237
|
| [9] |
Wang ZJ, Li JJ, Yao JX, et al. (2018) Protection of stratigraphic sections in China a suggested model for important global reference outcrop sections. Episodes 41: 1-6. doi: 10.18814/epiiugs/2018/v41i1/018001
|
| [10] |
López-García JA, Oyarzun R, Andrés SL, et al. (2011) Scientific, Educational, and Environmental Considerations Regarding Mine Sites and Geoheritage: A Perspective from SE Spain. Geoheritage 3: 267-275. doi: 10.1007/s12371-011-0040-2
|
| [11] |
Brocx M, Semeniuk V (2019) The "8Gs"—a blueprint for Geoheritage, Geoconservation, Geo-education and Geotourism. Aust J Earth Sci 66: 803-821. doi: 10.1080/08120099.2019.1576767
|
| [12] |
Migoń P, Pijet-Migoń E (2017) Viewpoint geosites - values, conservation and management issues. Proc Geol Assoc 128: 511-522. doi: 10.1016/j.pgeola.2017.05.007
|
| [13] |
Peña L, Monge-Ganuzas M, Onaindia M, et al. (2017) A Holistic Approach Including Biological and Geological Criteria for Integrative Management in Protected Areas. Environ Manage 59: 325-337. doi: 10.1007/s00267-016-0781-4
|
| [14] | Drápela E (2020) Overtourism in the Czech Sandstone Rocks: Causes of the Problem, the Current Situation and Possible Solutions. In: Martí-Parreño J, Gómez-Calvet R, Muñoz de Prat J, (eds.), Proceedings of the 3rd International Conference on Tourism Research ICTR 2020. Valencia: ACPI, 35-41. |
| [15] | Drápela E, Büchner J (2019) Neisseland Geopark: Concept, Purpose and Role in Promoting Sustainable Tourism. In: Fialova J (ed.), Public Recreation and Landscape Protection—With Sense Hand in Hand... Brno: Mendel Univ, 268-272. |
| [16] | Drápela E (2020) Mass tourism in the Bohemian Paradise: both a threat and an opportunity. In: Linderova I (ed.), Topical Issues of Tourism: Overtourism—Risk for a Destination. Jihlava: VSPS, 31-40. |
| [17] |
Uličný D (2001) Depositional systems and sequence stratigraphy of coarse-grained deltas in a shallow-marine, strike-slip setting: The Bohemian Cretaceous Basin, Czech Republic. Sedimentology 48: 599-628. doi: 10.1046/j.1365-3091.2001.00381.x
|
| [18] | Czech geological service (2020) Geological map 1: 500000, Prague. Available from: https://mapy.geology.cz/geological_map500/?locale=en. |
| [19] | Czech Switzerland National Park (2020) Main Topics. Available from: https://www.npcs.cz/. |
| [20] | UNESCO Global Geopark Bohemian Paradise (2020) Global Geopark UNESCO Bohemian Paradise. Available from: http://www.geoparkceskyraj.cz/. |
| [21] | Czech Statistical Office (2020) Public Database. Available from: https://vdb.czso.cz/vdbvo2/faces/en/index.jsf. |
| [22] | Hastie T, Tibshirani R, Friedman J (2009) The Elements of Statistical Learning. 2nd Ed. New York: Springer. |
| [23] |
Butler RW (1980) The concept of tourism area cycle of evolution: implications for management of resources. Can Geogr 24: 5-12. doi: 10.1111/j.1541-0064.1980.tb00970.x
|
| [24] |
Butler RW (2009) Tourism in the future: Cycles, waves or wheels? Futures 41: 346-352. doi: 10.1016/j.futures.2008.11.002
|
| [25] |
Butler R, Wall G (1985) Introduction: Themes in research on the evolution of tourism. Ann Tour Res 12: 287-296. doi: 10.1016/0160-7383(85)90001-5
|
| [26] | Drápela E, Bašta J (2018) Quantifying the power of border effect on Liberec region borders. Geogr Inf 22: 51-60. |
| [27] | Kubalíková L, Bajer A, Drápela E, et al. (2019) Cultural functions and services of geodiversity within urban areas (with a special regard on tourism and recreation). In: Fialova J (ed.), Public Recreation and Landscape Protection—With Sense Hand in Hand... Brno: Mendel Univ, 84-89. |
| [28] |
Shekhar S, Kumar P, Chauhan G, et al. (2019) Conservation and Sustainable Development of Geoheritage, Geopark, and Geotourism: A Case Study of Cenozoic Successions of Western Kutch, India. Geoheritage 11: 1475-1488. doi: 10.1007/s12371-019-00362-5
|
| [29] |
Erikstad L (2013) Geoheritage and geodiversity management—the questions for tomorrow. Proc Geol Assoc 124: 713-719. doi: 10.1016/j.pgeola.2012.07.003
|
| [30] | Eder W (2008) Geoparks—Promotion of Earth Sciences through Geoheritage Conservation, Education and Tourism. J Geol Soc India 72: 149-154. |
| [31] |
Mariotto FP, Venturini C (2017) Strategies and Tools for Improving Earth Science Education and Popularization in Museums. Geoheritage 9: 187-194. doi: 10.1007/s12371-016-0194-z
|
| [32] |
Catana MM, Brilha JB (2020) The Role of UNESCO Global Geoparks in Promoting Geosciences Education for Sustainability. Geoheritage 12: 1. doi: 10.1007/s12371-020-00440-z
|



Figures(7) / Tables(5)

Emil Drápela. Prevention of damage to sandstone rocks in protected areas of nature in northern Bohemia[J]. AIMS Geosciences, 2021, 7(1): 56-73. doi: 10.3934/geosci.2021003







 DownLoad:
DownLoad: