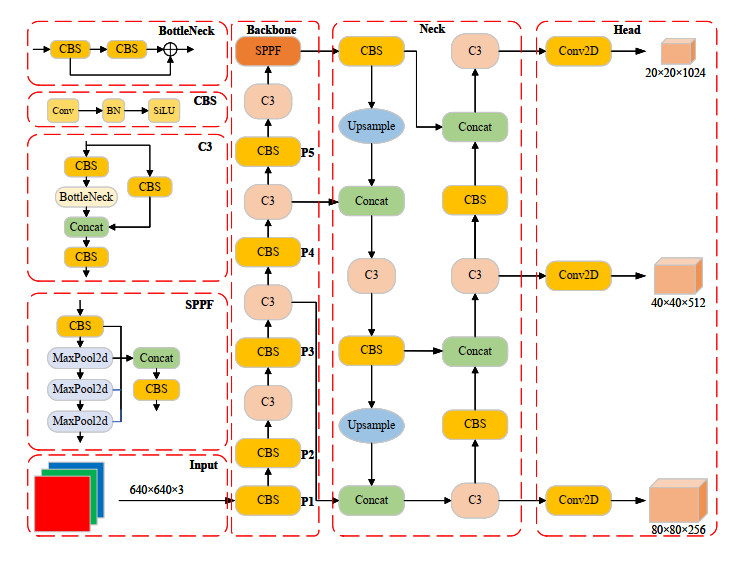
Outdoor, real-time, and accurate detection of insulator defect locations can effectively avoid the occurrence of power grid security accidents. This paper proposes an improved GhostNet-YOLOv5s algorithm based on GhostNet and YOLOv5 models. First, the backbone feature extraction network of YOLOv5 was reconstructed with the lightweight GhostNet module to reduce the number of parameters and floating point operations of the model, so as to achieve the purpose of being lightweight. Then, a 160 × 160 feature layer was added to the YOLOv5 network to extract more feature information of small targets and fuzzy targets. In addition, the introduction of lightweight GSConv convolution in the neck network further reduced the computing cost of the entire network. Finally, Focal-EIoU was introduced to optimize the CIoU bounding box regression loss function in the original algorithm to improve the convergence speed and target location accuracy of the model. The experimental results show that the parameter number, computation amount, and model size of the GhostNet-YOLOv5s model are reduced by 40%, 25%, and 36%, respectively, compared with the unimproved YOLOv5s model. The proposed method not only ensures the precision of insulator defect detection, but also greatly decreases the complexity of the model. Therefore, the GhostNet-YOLOv5s algorithm can meet the requirements of real-time detection in complex outdoor environments.
Citation: Jianjun Huang, Xuhong Huang, Ronghao Kang, Zhihong Chen, Junhan Peng. Improved insulator location and defect detection method based on GhostNet and YOLOv5s networks[J]. Electronic Research Archive, 2024, 32(9): 5249-5267. doi: 10.3934/era.2024242
Outdoor, real-time, and accurate detection of insulator defect locations can effectively avoid the occurrence of power grid security accidents. This paper proposes an improved GhostNet-YOLOv5s algorithm based on GhostNet and YOLOv5 models. First, the backbone feature extraction network of YOLOv5 was reconstructed with the lightweight GhostNet module to reduce the number of parameters and floating point operations of the model, so as to achieve the purpose of being lightweight. Then, a 160 × 160 feature layer was added to the YOLOv5 network to extract more feature information of small targets and fuzzy targets. In addition, the introduction of lightweight GSConv convolution in the neck network further reduced the computing cost of the entire network. Finally, Focal-EIoU was introduced to optimize the CIoU bounding box regression loss function in the original algorithm to improve the convergence speed and target location accuracy of the model. The experimental results show that the parameter number, computation amount, and model size of the GhostNet-YOLOv5s model are reduced by 40%, 25%, and 36%, respectively, compared with the unimproved YOLOv5s model. The proposed method not only ensures the precision of insulator defect detection, but also greatly decreases the complexity of the model. Therefore, the GhostNet-YOLOv5s algorithm can meet the requirements of real-time detection in complex outdoor environments.

| [1] |
H. Liu, S. Geng, J. Wang, B. Xu, Y. Yang, L. Liang, Aging analysis of porcelain insulators used in UHV AC transmission line (in Chinese), Insulators Surg. Arresters, 310 (2022), 159–164. https://doi.org/10.16188/j.isa.1003-8337.2022.06.023 doi: 10.16188/j.isa.1003-8337.2022.06.023

|
| [2] |
V. E. Ogbonna, P. I. Popoola, O. M. Popoola, S. O. Adeosun, A comparative study on the failure analysis of field failed high voltage composite insulator core rods and recommendation of composite insulators: A review, Eng. Fail. Anal., 138 (2022), 106369. https://doi.org/10.1016/j.engfailanal.2022.106369 doi: 10.1016/j.engfailanal.2022.106369
|
| [3] |
J. Chen, Z. Fu, X. Cheng, F. Wang, An method for power lines insulator defect detection with attention feedback and double spatial pyramid, Electr. Power Syst. Res., 218 (2023), 109175. https://doi.org/10.1016/j.epsr.2023.109175 doi: 10.1016/j.epsr.2023.109175
|
| [4] |
X. Luo, F. Yu, Y. Peng, UAV power grid inspection defect detection based on deep learning (in Chinese), Power Syst. Prot. Control, 50 (2022), 132–139. https://link.cnki.net/doi/10.19783/j.cnki.pspc.211664 doi: 10.19783/j.cnki.pspc.211664
|
| [5] |
X. Jia, Y. Yu, Y. Guo, Y. Huang, B. Zhao, Lightweight detection method of self-explosion defect of aerial photo insulator (in Chinese), High Voltage Eng., 49 (2023), 294–300. https://link.cnki.net/doi/10.13336/j.1003-6520.hve.20220334 doi: 10.13336/j.1003-6520.hve.20220334
|
| [6] | R. Girshick, Fast R-CNN, in 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, (2015), 1440–1448. https://doi.org/10.1109/ICCV.2015.169 |
| [7] |
S. Ren, K. He, R. Girshick, J. Sun, Faster R-CNN: Towards real-time object detection with region proposal networks, IEEE Trans. Pattern Anal. Mach. Intell., 39 (2016), 1137–1149. https://doi.org/10.1109/TPAMI.2016.2577031 doi: 10.1109/TPAMI.2016.2577031
|
| [8] | L. Yao, N. Zhang, A. Gao, Y. Wan, Research on fabric defect detection technology based on EDSR and improved faster RCNN, in Knowledge Science, Engineering and Management, (2022), 477–488. https://doi.org/10.1007/978-3-031-10989-8_38 |
| [9] |
Z. Hu, X. Yao, Identification and extraction of catenary insulators based on improved faster-RCNN (in Chinese), Insulators Surg. Arresters, (2023), 146–152. https://doi.org/10.16188/j.isa.1003-8337.2023.03.021 doi: 10.16188/j.isa.1003-8337.2023.03.021
|
| [10] |
P. Fan, H. M. Shen, C. Zhao, Z. Wei, J. G. Yao, Z. Q. Zhou, et al., Defect identification detection research for insulator of transmission lines based on deep learning, J. Phys. Conf. Ser., 1828 (2021), 012019. https://doi.org/10.1088/1742-6596/1828/1/012019 doi: 10.1088/1742-6596/1828/1/012019
|
| [11] |
H. Hu, J. Xu, Y. Huang, K. Wei, Defect detection of tower insulators based on improved Faster R-CNN transmission (in Chinese), Inf. Technol. Informatization, (2023), 63–66. https://doi.org/10.3969/j.issn.1672-9528.2023.07.016 doi: 10.3969/j.issn.1672-9528.2023.07.016
|
| [12] |
Y. Chen, C. Deng, Q. Sun, Z. Wu, L. Zou, G. Zhang, et al., Lightweight detection methods for insulator self-explosion defects, Sensors, 24 (2024), 290. https://doi.org/10.3390/s24010290 doi: 10.3390/s24010290
|
| [13] |
Z. Na, L. Cheng, H. Sun, B. Lin, Survey on UAV detection and identification based on deep learning (in Chinese), J. Signal Process., 40 (2024), 609–624. https://doi.org/10.16798/j.issn.1003-0530.2024.04.001 doi: 10.16798/j.issn.1003-0530.2024.04.001
|
| [14] | W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Y. Fu, et al., SSD: Single Shot MultiBox Detector, in Computer Vision – ECCV 2016, (2016), 21–37. https://doi.org/10.1007/978-3-319-46448-0_2 |
| [15] | J. Redmon, S. Divvala, R. Girshick, A. Farhadi, You only look once: Unified, real-time object detection, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 8 (2016), 779–788. https://doi.org/10.1109/CVPR.2016.91 |
| [16] |
B. Wei, Z. Xie, Y. Liu, K. Wen, F. Deng, P. Zhang, Online monitoring method for insulator self-explosion based on edge computing and deep learning, CSEE J. Power Energy Syst., 8 (2022), 1684–1696. https://doi.org/10.17775/CSEEJPES.2020.05910 doi: 10.17775/CSEEJPES.2020.05910
|
| [17] | A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, et al., MobileNets: Efficient convolutional neural networks for mobile vision applications, preprint, arXiv: 1704.04861. |
| [18] |
J. Li, L. Liu, Y. Niu, L. Li, Y. Peng, YOLOv3 identification method incorporating attention for insulator string (in Chinese), High Voltage Appar., 58 (2022), 67–74. https://doi.org/10.13296/j.1001-1609.hva.2022.11.009 doi: 10.13296/j.1001-1609.hva.2022.11.009
|
| [19] | J. Redmon, A. Farhadi, YOLOv3: An incremental improvement, preprint, arXiv: 1804.02767. |
| [20] |
H. Xia, B. Yang, Y. Li, B. Wang, An improved centerNet model for insulator defect detection using aerial imagery, Sensors, 22 (2022), 2850. https://doi.org/10.3390/s22082850 doi: 10.3390/s22082850
|
| [21] | X. Zhou, D. Wang, P. Krähenbühl, Objects as points, preprint, arXiv: 1904.07850. |
| [22] |
G. Han, L. Zhao, Q. Li, S. Li, R. Wang, Q. Yuan, et al., A lightweight algorithm for insulator target detection and defect identification, Sensors, 23 (2023), 1216–1225. https://doi.org/10.3390/s23031216 doi: 10.3390/s23031216
|
| [23] | K. Han, Y. Wang, Q. Tian, J. Guo, C. Xu, C. Xu, GhostNet: More features from cheap operations, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 92 (2020), 1577–1586. https://doi.org/10.1109/CVPR42600.2020.00165 |
| [24] | A. Bochkovskiy, C. Y. Wang, H. Y. M. Liao, YOLOv4: Optimal speed and accuracy of object detection, preprint, arXiv: 2004.10934. |
| [25] |
K. Chen, X. Liu, L. Jia, Y. Fang, C. Zhao, Insulator defect detection based on lightweight network and enhanced multi-scale feature fusion (in Chinese), High Voltage Eng., 50 (2023), 1289–1300. https://doi.org/10.13336/j.1003-6520.hve.20221652 doi: 10.13336/j.1003-6520.hve.20221652
|
| [26] | N. Ma, X. Zhang, H. T. Zheng, J. Sun, ShuffleNet V2: Practical guidelines for efficient CNN architecture design, in Proceedings of the European Conference on Computer Vision (ECCV), (2018), 116–131. |
| [27] | N. Ma, X. Zhang, H. T. Zheng, J. Sun, YOLOv5 (accessed on 22 November 2022). Available from: https://github.com/ultralytics/yolov5. |
| [28] |
Y. Li, M. Ni, Y. Lu, Insulator defect detection for power grid based on light correction enhancement and YOLOv5 model, Energy Rep., 8 (2022), 807–814. https://doi.org/10.1016/j.egyr.2022.08.027 doi: 10.1016/j.egyr.2022.08.027
|
| [29] |
D. Wei, B. Hu, C. Shan, H. Liu, Insulator defect detection based on improved Yolov5s, Front. Earth Sci., 11 (2023), 1337982. https://doi.org/10.3389/feart.2023.1337982 doi: 10.3389/feart.2023.1337982
|
| [30] | H. Li, J. Li, H. Wei, Z. Liu, Z. Zhan, Q. Ren, Slim-neck by GSConv: A lightweight-design for real-time detector architectures, preprint, arXiv: 2206.02424. |
| [31] |
Z. Zheng, P. Wang, D. Ren, W. Liu, R. Ye, Q. Hu, et al., Enhancing geometric factors in model learning and inference for object detection and instance segmentation, IEEE Trans. Cybern., 52 (2022), 8574–8586. https://doi.org/10.1109/TCYB.2021.3095305 doi: 10.1109/TCYB.2021.3095305
|
| [32] |
Y. F. Zhang, W. Ren, Z. Zhang, Z. Jia, L. Wang, T. Tan, Focal and efficient IOU loss for accurate bounding box regression, Neurocomputing, 506 (2022), 146–157. https://doi.org/10.1016/j.neucom.2022.07.042 doi: 10.1016/j.neucom.2022.07.042
|
| [33] | C. Y. Wang, A. Bochkovskiy, H. Y. M. Liao, YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors, in 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, (2023), 7464–7475. https://doi.org/10.1109/CVPR52729.2023.00721 |








Figures(9) / Tables(3)
Jianjun Huang, Xuhong Huang, Ronghao Kang, Zhihong Chen, Junhan Peng. Improved insulator location and defect detection method based on GhostNet and YOLOv5s networks[J]. Electronic Research Archive, 2024, 32(9): 5249-5267. doi: 10.3934/era.2024242







 DownLoad:
DownLoad: