Citation: Bei Li, Siddharth Gangadhar, Pramode Verma, Samuel Cheng. Maximize Producer Rewards in Distributed Windmill Environments: A Q-Learning Approach[J]. AIMS Energy, 2015, 3(1): 162-172. doi: 10.3934/energy.2015.1.162

| [1] | The Smart Grid: An Introduction. Technical report, Office of Electricity Delivery and Energy Reliability, Department of Energy, 2008. |
| [2] | Understanding the Benefits of the Smart Grid. Technical report, DOE/NETL-2010/1413, NETL Lab, Department of Energy, 2010. |
| [3] | Methodological Approach for Estimating the Benefits and Costs of Smart Grid Demonstration Projects. Technical report, 1020342, Electric Power Research Institute, 2010. |
| [4] | Borenstein S, Jaske M, Rosenfeld A (2002) Dynamic pricing, advanced metering, and demand response in electricity markets. Available from: https://escholarship.org/uc/item/11w8d6m4. |
| [5] | King CS (2001) The economics of real-time and time-of-use pricing for residential consumers. Technical report, Technical report, American Energy Institute. |
| [6] | SMART GRID POLICY. Technical report, Docket No. PL09-4-000, United States of America Federal Energy Regulatory Commission, 2009. |
| [7] | Communication Networks and Systems for Power Utility Automation—Part 7-420: Basic Communication Structure—Distributed Energy Resources Logical Nodes. Technical report, IEC 61850-7-420, International Electrotechnical Commission, 2009. |
| [8] | Distributed Generation and Renewable Energy Current Programs for Businesses. Available from: http://docs.cpuc.ca.gov/published/news release/7408.htm. |
| [9] | Understanding Net Metering. . Available from: http://www.solarcity.com/learn/understanding-netmetering.aspx. |
| [10] | Ketter W, Collins J, Block CA (2010) Smart grid economics: Policy guidance through competitive simulation. ERIM report series research in management Erasmus Research Institute of Management. Erasmus Research Institute of Management (ERIM). Available from: http://hdl.handle.net/1765/21307. |
| [11] |
Nanduri V, Das TK (2007) A reinforcement learning model to assess market power under auction-based energy pricing. IEEE T Power Syst 22: 85-95. doi: 10.1109/TPWRS.2006.888977

|
| [12] |
Krause T, Beck EV, Cherkaoui R, et al. (2006) A comparison of Nash equilibria analysis and agent-based modelling for power markets. Int J Elec Power 28: 599-607. doi: 10.1016/j.ijepes.2006.03.002
|
| [13] | Frezzi P, Garcés F, Haubrich HJ (2007) Analysis of Short-term Bidding Strategies in Power Markets. Power Tech, 2007 IEEE Lausanne 971-976. |
| [14] | Tellidou AC, Bakirtzis AG (2006) Multi-agent reinforcement learning for strategic bidding in power markets. Intelligent Systems, 2006 3rd International IEEE Conference on, 408-413. |
| [15] | Watanabe I, Okada K, Tokoro K, et al. (2002) Adaptive multiagent model of electric power market with congestion management. Evolutionary Computation, 2002. CEC'02. Proceedings of the 2002 Congress on, 523-528. |
| [16] | Bompard EF, Abrate G, Napoli R, et al. (2007) Multi-agent models for consumer choice and retailer strategies in the competitive electricity market. Int J Emerging Electr Pow Syst 8: 4. |
| [17] | Vytelingum P, Voice TD, Ramchurn SD, et al. (2010) Agent-based micro-storage management for the smart grid. Proceedings of the 9th International Conference on Autonomous Agents and Multiagent Systems 1: 39-46. |
| [18] | Li B, Gangadhar S, Cheng S et al. (2011) Predicting user comfort level using machine learning for Smart Grid environments. Innovative Smart Grid Technologies (ISGT), 2011 IEEE PES 1-6. |
| [19] | Reddy PP, Veloso MM (2011) Strategy Learning for Autonomous Agents in Smart Grid Markets. Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence (IJCAI), 1446-1451. |
| [20] | Reddy PP, Veloso MM (2011) Learned Behaviors of Multiple Autonomous Agents in Smart Grid Markets. Proceedings of the Twenty-Fifth Conference on Artificial Intelligence (AAAI-11), 1396-1401. |
| [21] | Goldin J (2007) Making Decisions about the Future: The Discounted-Utility Model. Mind Matters: Wesleyan J Psychology 2: 49-55. |
| [22] | Watkins C. Learning from Delayed Rewards. PhD thesis, University of Cambridge,England, 1989. |
| [23] | Watkins C, Dayan P (1992) Technical Note: Q-Learning. Mach Learn 8: 279-292. |
| [24] |
Puterman ML (1990) Markov decision processes. Handbooks in Operations Research and Management Science 2: 331-434. doi: 10.1016/S0927-0507(05)80172-0
|
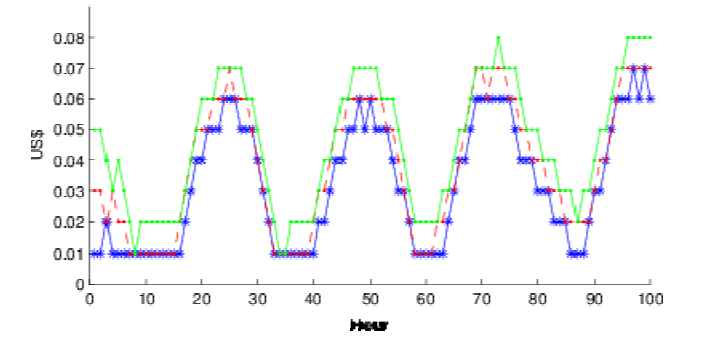
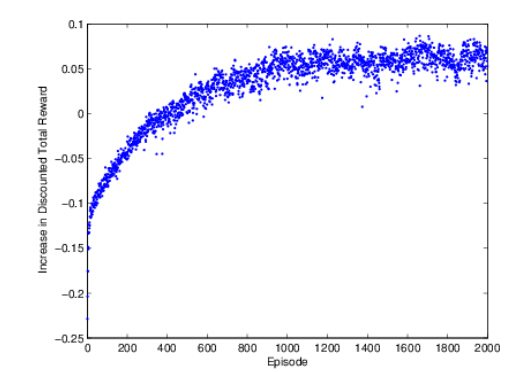
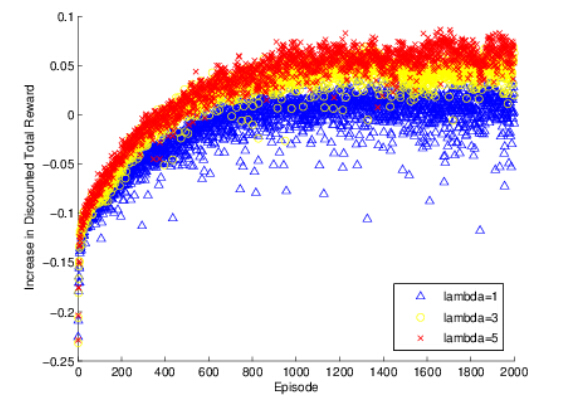
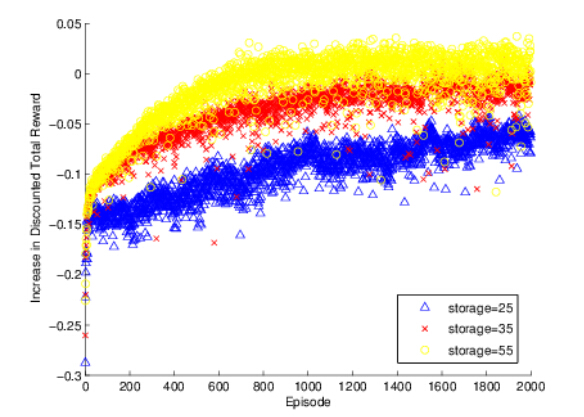
Figures(4)

Bei Li, Siddharth Gangadhar, Pramode Verma, Samuel Cheng. Maximize Producer Rewards in Distributed Windmill Environments: A Q-Learning Approach[J]. AIMS Energy, 2015, 3(1): 162-172. doi: 10.3934/energy.2015.1.162







 DownLoad:
DownLoad: