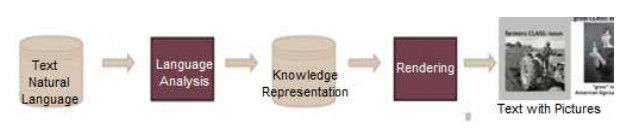
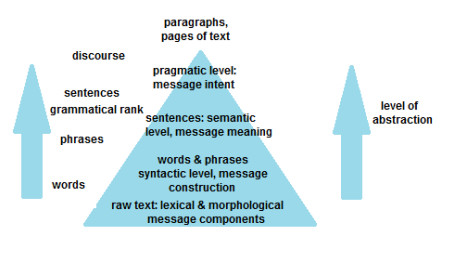
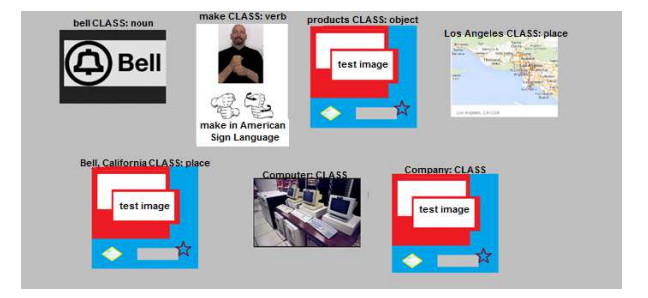
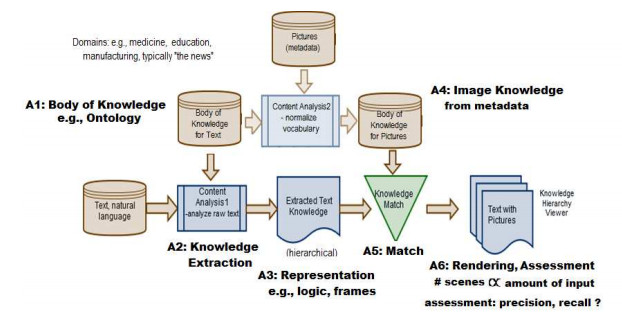
We describe the investigation of automatic annotation of text with pictures, where knowledge extraction uses dependency parsing. Annotation of text with pictures, a form of knowledge visualization, can assist understanding. The problem statement is, given a corpus of images and a short passage of text, extract knowledge (or concepts), and then display that knowledge in pictures along with the text to help with understanding. A proposed solution framework includes a component to extract document concepts, a component to match document concepts with picture metadata, and a component to produce an amalgamated output of text and pictures. A proof-of-concept application based on the proposed framework provides encouraging results
Citation: J. Kent Poots, Nick Cercone. 2017: First steps in the investigation of automated text annotation with pictures, Big Data and Information Analytics, 2(2): 97-106. doi: 10.3934/bdia.2017001
We describe the investigation of automatic annotation of text with pictures, where knowledge extraction uses dependency parsing. Annotation of text with pictures, a form of knowledge visualization, can assist understanding. The problem statement is, given a corpus of images and a short passage of text, extract knowledge (or concepts), and then display that knowledge in pictures along with the text to help with understanding. A proposed solution framework includes a component to extract document concepts, a component to match document concepts with picture metadata, and a component to produce an amalgamated output of text and pictures. A proof-of-concept application based on the proposed framework provides encouraging results

| [1] | Coyne B., Sproat R. (2003) WordsEye: An automatic text-to-scene conversion system. Proceedings of the 28th annual conference on Computer graphics and interactive techniques 3: 487-496. |
| [2] | D. Genzel, K. Macherey and J. Uszkoreit, Creating a high-quality machine translation system for a low-resource language: Yiddish, (2009), Available from: www.mt-archive.info/MTS-2009-Genzel.pdf |
| [3] | A. Handler, An empirical study of semantic similarity in WordNet and Word2Vec, Columbia University (2014). |
| [4] | Joshi D., Wang J. Z., Li J. (2006) The Story Picturing Engine-a system for automatic text illustration. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMCCAP) 2: 68-89. |
| [5] | J. McCarty, Programs with common sense, Defense Technical Information Center (1963). |
| [6] | J. K. Poots and E. Bagheri, Automatic annotation of text with pictures, (in-press), IEEE IT Professional (2016). |
| [7] | Rose S., Engel D., Cramer N., Cowley W. (2010) Automatic keyword extraction from individual documents. Text Mining : 1-20. |
| [8] | Uren V., Cimiano P., Iria J., Handschuh S., Vargas-Vera M., Motta E., Ciravegna F. (2006) Semantic annotation for knowledge management: Requirements and a survey of the state of the art. Web Semantics: science, services and agents on the World Wide Web 4: 14-28. |
| [9] | UzZaman N., Bigham J. P., Allen J. F. (2004) Multimodal summarization of complex sentences. Proceedings of the 16th international conference on Intelligent user interfaces 2: 43-52. |
| [10] | Veale T., Conway A., Collins B. (1998) The challenges of cross-modal translation: English-to-Sign-Language translation in the Zardoz system. Machine Translation 13: 81-106. |
| [11] | Zhao L., Kipper K., Schuler W., Vogler C., Badle N., Palmer M. (2000) A machine translation system from English to American Sign Language. Envisioning Machine Translation in the Information Future : 54-67. |

Figures(5) / Tables(3)

J. Kent Poots, Nick Cercone. 2017: First steps in the investigation of automated text annotation with pictures, Big Data and Information Analytics, 2(2): 97-106. doi: 10.3934/bdia.2017001









 DownLoad:
DownLoad: