Citation: Wenhao Chen, Kinkeung Lai, Yi Cai. Topic generation for Chinese stocks: a cognitively motivated topic modelingmethod using social media data[J]. Quantitative Finance and Economics, 2018, 2(2): 279-293. doi: 10.3934/QFE.2018.2.279

| [1] |
Abbasi A, Chen H (2008) CyberGate: A Design Framework and System for Text Analysis of Computer-Mediated Communication. MIS Quart 32: 811-837. doi: 10.2307/25148873

|
| [2] | Andrzejewski D, Zhu X, Craven M (2009) Incorporating domain knowledge into topic modeling via Dirichlet forest priors. Proc Int Conf Mach Learn 382: 25–32. |
| [3] | Blei D, Ng A, Jordan M (2003) Latent dirichlet allocation. J Mach Learn Res 3: 993–1022. |
| [4] |
Bollen J, Mao H, Zeng X (2011) Twitter mood predicts the stock market. Comput Sci 2: 1–8. doi: 10.1016/j.jocs.2010.12.007
|
| [5] |
Cai Y, Chen W, Leung H, et al. (2016) Context-aware ontologies generation with basic level concepts from collaborative tags. Neurocomputing 208: 25–38. doi: 10.1016/j.neucom.2016.02.070
|
| [6] |
Chau M, Xu J (2007) Mining Communities and Their Relationships in Blogs: A Study of Hate Groups. In J Human-Computer Studies 65: 57–70. doi: 10.1016/j.ijhcs.2006.08.009
|
| [7] |
Chen W, Cai Y, Lai K, et al. (2016) A topic-based sentiment analysis model to predict stock market price movement using Weibo mood. Web Intelligence 14: 287-300. doi: 10.3233/WEB-160345
|
| [8] |
Chen W, Cai Y, Leung H, et al. (2010) Generating ontologies with basic level concepts from folksonomies. Procedia Computer Sc 1: 573–581. doi: 10.1016/j.procs.2010.04.061
|
| [9] | Fan R, Zhao J, Chen Y, et al. (2014) Anger is more influential than joy: Sentiment correlation in Weibo. PloS one 9. |
| [10] | Gao Q, Abel F, Houben GJ, et al. (2012) A Comparative Study of Users? Microblogging Behavior on Sina Weibo and Twitter, In: Mastho_ J., Mobasher B., Desmarais M.C., Nkambou R. (eds), User Modeling, Adaptation, and Personalization, Springer, Berlin, Heidelberg, 88–101. |
| [11] | Gilbert E, Karahalio E (2010) Widespread worry and the stock market. Proceedings of the International AAAI Conference on Weblogs and Social Media, Washington, DC, 59–65. |
| [12] | Gluck M (1985) Information, uncertainty and the utility of categories. Proceedings of the Seventh Annual Conference on Cognitive Science Society, 283–287. |
| [13] | Guo H, Zhu H, Guo Z, et al. (2009) Product feature categorization with multilevel latent semantic association. Proceedings of the 18th ACM conference on Information and knowledge management, 1087–1096. |
| [14] | Gruhl D, Guha R, Kumar R, et al. (2005) The predictive power of online chatter. Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining 41: 78–87. |
| [15] |
Hofmann T (2001) Unsupervised learning by probabilistic latent semantic analysis. Mach learn 42: 177–196. doi: 10.1023/A:1007617005950
|
| [16] | Hu M, Liu B (2004) Mining opinion features in customer reviews. National Conference on Artifical Intelligence, AAAI Press, 755–760. |
| [17] | Jo Y, Oh A (2011) Aspect and sentiment unification model for online review analysis. Proceedings of the fourth ACM international conference on Web search and data mining, 815-824. |
| [18] |
Li X, Xie H, Chen L, et al. (2014) News impact on stock price return via sentiment analysis. Know-Based Syst 69: 14–23. doi: 10.1016/j.knosys.2014.04.022
|
| [19] | Liang H, Tsai F, Kwee A (2009) Detecting Novel Business Blogs. Proceedings of the 7th International Conference on Information. IEEE Press, 1–5. |
| [20] | Liu A, Gu B, Konana P, et al. (2006) Predicting stock price from financial message boards with a mixture of experts framework. Intelligent data exploration & analysis laboratory, 1–14. |
| [21] | Mimno D, Wallach H, Talley E, et al. (2011) Optimizing semantic coherence in topic models. Proceedings of the Conference on Empirical Methods in Natural Language Processing, 262–272. |
| [22] | Mishne G, Glance N (2006) Predicting Movie Sales from Blogger Sentiment. Proceedings of AAAICAAW-06, the Spring Symposia on Computational Approaches to Analyzing Weblogs, 155–158. |
| [23] | Mukherjee A, Liu B (2012) Aspect extraction through semi-supervised modeling. Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, 339–348. |
| [24] |
OLeary D (2011) Blog Mining-Review and Extensions: From Each According to His Opinion. Decision Support Syst 51: 821–830. doi: 10.1016/j.dss.2011.01.016
|
| [25] | Peng F, Feng F, McCallum A (2004) Chinese segmentation and new word detection using conditional random fields. Proceedings of the 20th international conference on Computational Linguistics, 562. |
| [26] |
Rosch E, Mervis C, Gray W, et al. (1976) Basic objects in natural categories. Cogn Psychol 8: 382–439. doi: 10.1016/0010-0285(76)90013-X
|
| [27] | Schumaker R, Chen H (2009) Textual analysis of stock market prediction using breaking financial news: the AZFin text system. ACM T Informa Syst 27: 1–19. |
| [28] | Wang T, Cai Y, Leung H, et al. (2015) Entropy-based term weighting schemes for text categorization in VSM. Tools with Artificial Intelligence, 325–332. |
| [29] | Wilson A, Chew P (2010) Term weighting schemes for latent dirichlet allocation. The 2010 annual conference of the North American Chapter of the Association for Computational Linguistics, 465–473. |
| [30] | Yang F, Liu Y, Yu X, et al. (2012) Automatic detection of rumor on Sina Weibo. Proceedings of the ACM SIGKDD Workshop on Mining Data Semantics, 1–7. |
| [31] | Yang K, Cai Y, Chen Z, et al. (2016) Exploring Topic Discriminating Power of Words in Latent Dirichlet Allocation. Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, 2238–2247. |
| [32] |
Zhang X, Fuehres H, Gloor P (2011) Predicting stock market indicator through twitter 'I hope it is not as bad as I fear'. Procedia-Soc Behav Sci 26: 55–62. doi: 10.1016/j.sbspro.2011.10.562
|
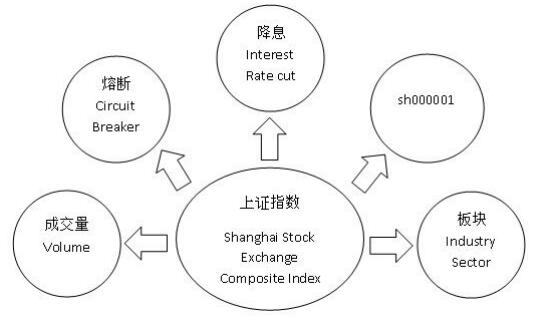
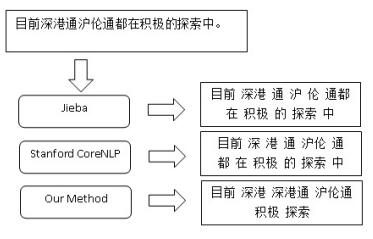
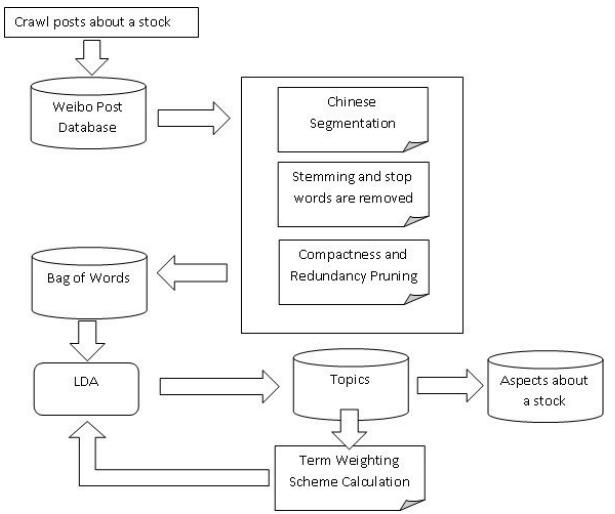
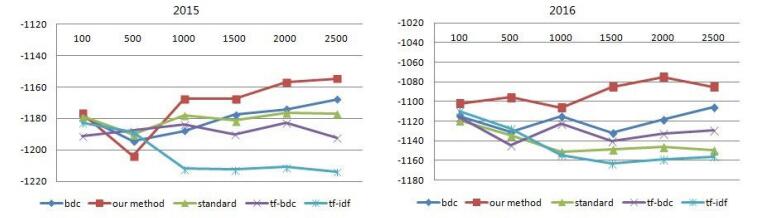
Figures(5) / Tables(2)

Wenhao Chen, Kinkeung Lai, Yi Cai. Topic generation for Chinese stocks: a cognitively motivated topic modelingmethod using social media data[J]. Quantitative Finance and Economics, 2018, 2(2): 279-293. doi: 10.3934/QFE.2018.2.279







 DownLoad:
DownLoad: