Citation: Tatjana Mijatovic, Dario Siniscalco, Krishnamurthy Subramanian, Eugene Bosmans, Vincent C. Lombardi, Kenny L. De Meirleir. Biomedical approach in autism spectrum disorders—the importance of assessing inflammation[J]. AIMS Molecular Science, 2018, 5(3): 173-182. doi: 10.3934/molsci.2018.3.173

| [1] | Christensen DL, Bilder DA, Zahorodny W, et al. (2016) Prevalence and Characteristics of Autism Spectrum Disorder Among Children Aged 8 Years-Autism and Developmental Disabilities Monitoring Network, 11 Sites, United States, 2012. MMWR Surveill Summ 65: 1–23. |
| [2] |
Zablotsky B, Bramlett M, Blumberg SJ (2015) Factors associated with parental ratings of condition severity for children with autism spectrum disorder. Dis Health J 8: 626–634. doi: 10.1016/j.dhjo.2015.03.006

|
| [3] |
Hertz-Picciotto I, Delwiche L (2009) The rise in autism and the role of age at diagnosis. Epidemiology 20: 84–90. doi: 10.1097/EDE.0b013e3181902d15
|
| [4] |
First MB (2013) Diagnostic and statistical manual of mental disorders, 5th edition, and clinical utility. J Nerv Ment Dis 201: 727–729. doi: 10.1097/NMD.0b013e3182a2168a
|
| [5] |
Siniscalco D, Cirillo A, Bradstreet JJ, et al. (2013) Epigenetic findings in autism: New perspectives for therapy. Int J Environ Res Public Health 10: 4261–4273. doi: 10.3390/ijerph10094261
|
| [6] | Siniscalco D (2013) Current findings and research prospective in autism spectrum disorders. Autism-Open Access S2: e001. |
| [7] | Siniscalco D (2014) The searching for autism biomarkers: A commentary on: A new methodology of viewing extra-axial fluid and cortical abnormalities in children with autism via transcranial ultrasonography. Front Hum Neurosci 8: 240. |
| [8] |
Ashwood P, Krakowiak P, Hertz-Picciotto I, et al. (2011) Altered T cell responses in children with autism. Brain Behav Immun 25: 840–849. doi: 10.1016/j.bbi.2010.09.002
|
| [9] |
Suzuki K, Matsuzaki H, Iwata K, et al. (2011) Plasma cytokine profiles in subjects with high-functioning autism spectrum disorders. PLoS One 6: e20470. doi: 10.1371/journal.pone.0020470
|
| [10] |
Okada K, Hashimoto K, Iwata Y, et al. (2007) Decreased serum levels of transforming growth factor-beta1 in patients with autism. Prog Neuro-Psychopharmacol Biol Psychiatry 31: 187–190. doi: 10.1016/j.pnpbp.2006.08.020
|
| [11] |
Ashwood P, Enstrom A, Krakowiak P, et al. (2008) Decreased transforming growth factor beta1 in autism: A potential link between immune dysregulation and impairment in clinical behavioral outcomes. J Neuroimmunol 204: 149–153. doi: 10.1016/j.jneuroim.2008.07.006
|
| [12] | Al-Ayadhi LY, Mostafa GA (2012) Elevated serum levels of interleukin-17A in children with autism. J Neuroinflammation 9: 158. |
| [13] | Inga Jacome MC, Morales Chacon LM, Vera CH, et al. (2016) Peripheral inflammatory markers contributing to comorbidities in autism. Behav Sci 6: 29. |
| [14] |
Siniscalco D, Schultz S, Brigida AL, et al. (2018) Inflammation and neuro-immune dysregulations in autism spectrum disorders. Pharmaceuticals 11: E56. doi: 10.3390/ph11020056
|
| [15] |
El-Ansary A, Al-Ayadhi L (2012) Lipid mediators in plasma of autism spectrum disorders. Lipids Health Dis 11: 160. doi: 10.1186/1476-511X-11-160
|
| [16] | Skorupka C, Amet L (2017) Autisme, un nouveau regard: Causes et solutions (French), French: Editions Mosaïque-Santé. |
| [17] |
Rossignol DA, Frye RE (2012) Mitochondrial dysfunction in autism spectrum disorders: A systematic review and meta-analysis. Mol Psychiatry 17: 290–314. doi: 10.1038/mp.2010.136
|
| [18] |
Horvath K, Perman JA (2002) Autism and gastrointestinal symptoms. Curr Gastroenterol Rep 4: 251–258. doi: 10.1007/s11894-002-0071-6
|
| [19] |
Adams JB, Johansen LJ, Powell LD, et al. (2011) Gastrointestinal flora and gastrointestinal status in children with autism-comparisons to typical children and correlation with autism severity. BMC Gastroenterol 11: 22. doi: 10.1186/1471-230X-11-22
|
| [20] |
Finegold SM, Dowd SE, Gontcharova V, et al. (2010) Pyrosequencing study of fecal microflora of autistic and control children. Anaerobe 16: 444–453. doi: 10.1016/j.anaerobe.2010.06.008
|
| [21] |
Iovene MR, Bombace F, Maresca R, et al. (2017) Intestinal dysbiosis and yeast isolation in stool of subjects with autism spectrum disorders. Mycopathologia 182: 349–363. doi: 10.1007/s11046-016-0068-6
|
| [22] | Critchfield JW, van Hemert S, Ash M, et al. (2011) The potential role of probiotics in the management of childhood autism spectrum disorders. Gastroenterol Res Pract 2011: 161358. |
| [23] | Siniscalco D, Antonucci N (2013) Involvement of dietary bioactive proteins and peptides in autism spectrum disorders. Curr Protein Pept Sci 14: 674–679. |
| [24] |
Bransfield RC, Wulfman JS, Harvey WT, et al. (2008) The association between tick-borne infections, Lyme borreliosis and autism spectrum disorders. Med Hypotheses 70: 967–974. doi: 10.1016/j.mehy.2007.09.006
|
| [25] |
Kuhn M, Grave S, Bransfield R, et al. (2012) Long term antibiotic therapy may be an effective treatment for children co-morbid with Lyme disease and autism spectrum disorder. Med Hypotheses 78: 606–615. doi: 10.1016/j.mehy.2012.01.037
|
| [26] |
Vanuytsel T, Vermeire S, Cleynen I (2013) The role of Haptoglobin and its related protein, Zonulin, in inflammatory bowel disease. Tissue Barriers 1: e27321. doi: 10.4161/tisb.27321
|
| [27] | Uribarri J, Oh MS, Carroll HJ (1998) D-lactic acidosis. A review of clinical presentation, biochemical features, and pathophysiologic mechanisms. Medicine 77: 73–82. |
| [28] | Nicolson GL, Gan R, Nicolson NL, et al. (2007) Evidence for Mycoplasma ssp., Chlamydia pneunomiae, and human herpes virus-6 coinfections in the blood of patients with autistic spectrum disorders. J Neurosci Res 85: 1143–1148. |
| [29] |
Careaga M, Van de Water J, Ashwood P (2010) Immune dysfunction in autism: A pathway to treatment. Neurotherapeutics 7: 283–292. doi: 10.1016/j.nurt.2010.05.003
|
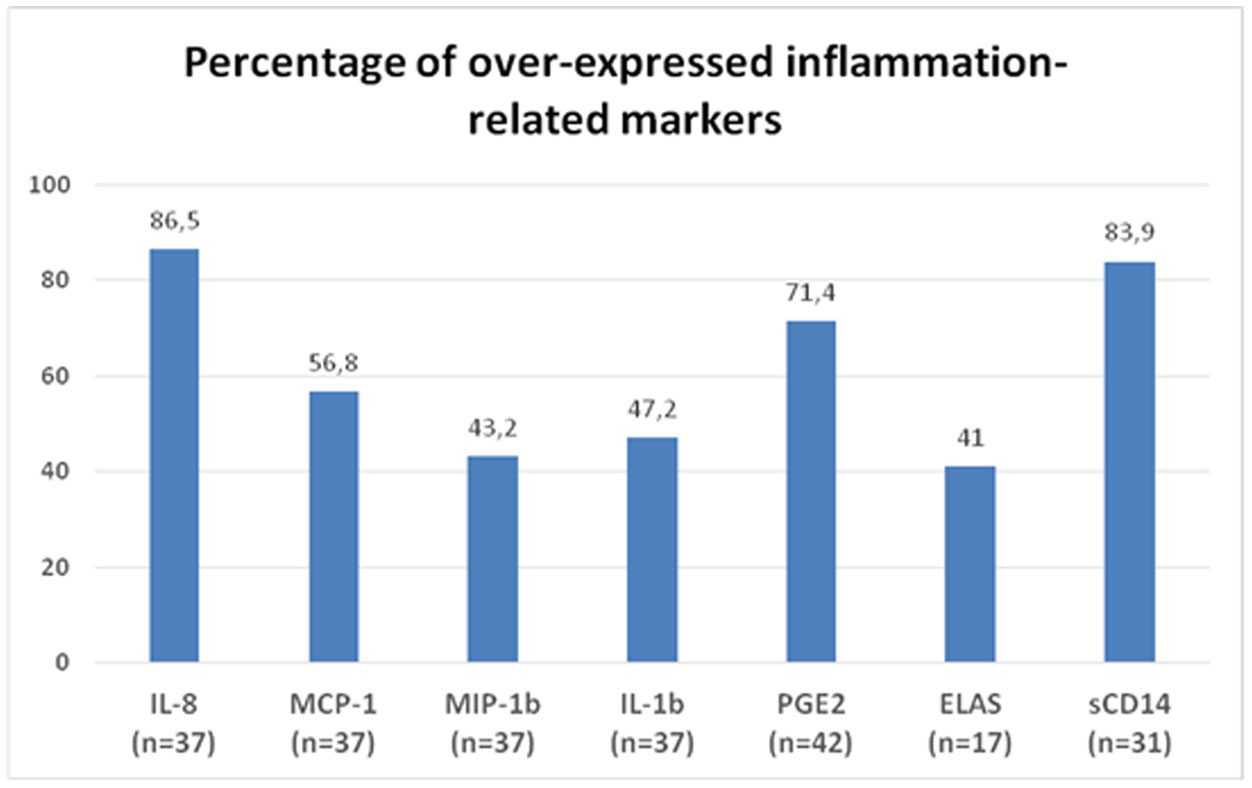
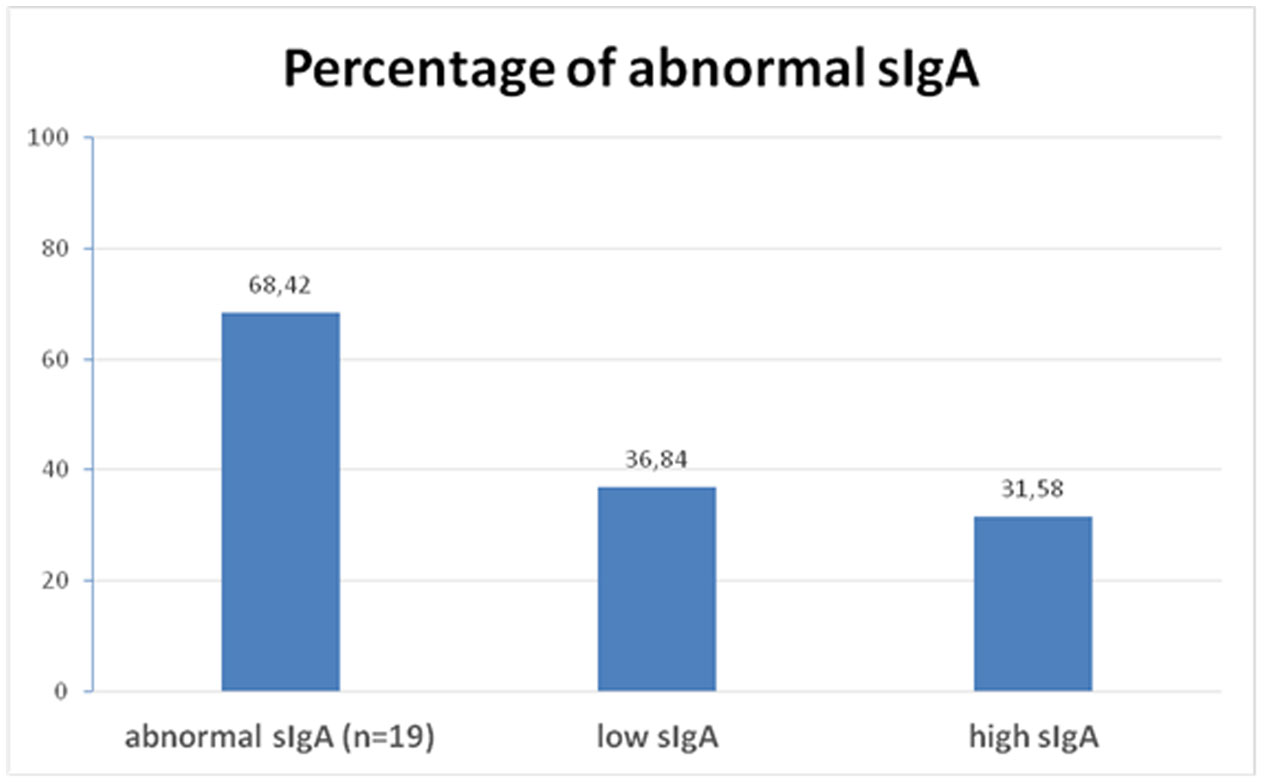
Figures(2) / Tables(1)

Tatjana Mijatovic, Dario Siniscalco, Krishnamurthy Subramanian, Eugene Bosmans, Vincent C. Lombardi, Kenny L. De Meirleir. Biomedical approach in autism spectrum disorders—the importance of assessing inflammation[J]. AIMS Molecular Science, 2018, 5(3): 173-182. doi: 10.3934/molsci.2018.3.173







 DownLoad:
DownLoad: