Citation: Ugo Avila-Ponce de León, Ángel G. C. Pérez, Eric Avila-Vales. A data driven analysis and forecast of an SEIARD epidemic model for COVID-19 in Mexico[J]. Big Data and Information Analytics, 2020, 5(1): 14-28. doi: 10.3934/bdia.2020002

| [1] | Cruz-Pacheco G, Bustamante-Castañeda JF, Caputo JG, et al. (2020) Dispersion of a new coronavirus SARS-CoV-2 by airlines in 2020: Temporal estimates of the outbreak in Mexico. Rev Invest Clin 72: 138-143. |
| [2] | Vivanco-Lira A, (2020) Predicting COVID-19 distribution in Mexico through a discrete and timedependent Markov chain and an SIR-like model. arXiv 2003.06758. |
| [3] | Alvarez MM, Gonzalez-Gonzalez E and Trujillo-de Santiago G, (2020) Modeling COVID-19 epidemics in an Excel spreadsheet: Democratizing the access to first-hand accurate predictions of epidemic outbreaks. medRxiv. |
| [4] | Acuña-Zegarra MA, Comas-García A, Hernández-Vargas E, et al. (2020) The SARS-CoV-2 epidemic outbreak: A review of plausible scenarios of containment and mitigation for Mexico. medRxiv. |
| [5] | Acuña-Zegarra MA, Santana-Cibrian M and Velasco-Hernandez JX, (2020) Modeling behavioral change and COVID-19 containment in Mexico: A trade-off between lockdown and compliance. Math Biosci 325: 108370. |
| [6] | Lin Q, Zhao S, Gao D, et al. (2020) A conceptual model for the coronavirus disease 2019 (COVID-19) outbreak in Wuhan, China with individual reaction and governmental action. Int J Infect Dis 93: 211-216. |
| [7] | Khrapov P and Loginova A, (2020) Mathematical modelling of the dynamics of the Coronavirus COVID-19 epidemic development in China. Int J Open Inf Technol 8: 13-16. |
| [8] | Fanelli D and Piazza F, (2020) Analysis and forecast of COVID-19 spreading in China, Italy and France. Chaos Solitons Fractals 134: 109761. |
| [9] | Caccavo D, (2020) Chinese and Italian COVID-19 outbreaks can be correctly described by a modified SIRD model. medRxiv. |
| [10] | Singh R and Adhikari R, (2020) Age-structured impact of social distancing on the COVID-19 epidemic in India. arXiv 2003.12055. |
| [11] | Bastos SB and Cajueiro DO, (2020) Modeling and forecasting the Covid-19 pandemic in Brazil. arXiv 2003.14288. |
| [12] | Sharma S, Volpert V and Banerjee M, (2020) Extended SEIQR type model for COVID-19 epidemic and data analysis. medRxiv. |
| [13] | Khoshnaw SHA, Shahzad M, Ali M, et al. (2020) A quantitative and qualitative analysis of the COVID-19 pandemic model. Chaos Solitons Fractals 138: 109932. |
| [14] | Monteiro LHA, (2020) An epidemiological model for SARS-CoV-2. Ecol Complex 43: 100836. |
| [15] | Nabi KN, (2020) Forecasting COVID-19 pandemic: A data-driven analysis. Chaos Solitons Fractals 139: 110046. |
| [16] | Okuonghae D and Omame A, (2020) Analysis of a mathematical model for COVID-19 population dynamics in Lagos, Nigeria. Chaos Solitons Fractals 139: 110032. |
| [17] | Johns Hopkins CSSE, 2019 Novel Coronavirus COVID-19 (2019-nCoV) Data Repository, 2020. Available from: https://github.com/CSSEGISandData/COVID-19. |
| [18] | Hethcote HW, (2000) The mathematics of infectious diseases. SIAM Rev 42: 599-653. |
| [19] | Diekmann O and Heesterbeek JAP, (2000) Mathematical Epidemiology of Infectious Diseases: Model Building, Analysis and Interpretation, New York: John Wiley & Sons. |
| [20] | Diekmann O, Heesterbeek JAP and Roberts MG, (2010) The construction of next-generation matrices for compartmental epidemic models. J Royal Soc Interface 7: 873-885. |
| [21] | Sjödin H, Wilder-Smith A, Osman S, et al. (2020) Only strict quarantine measures can curb the coronavirus disease (COVID-19) in Italy, 2020. Eurosurveillance 25: 2000280. |
| [22] | Expansión política, La magnitud de la epidemia de COVID-19 no se puede medir en tiempo real, 2020. Available from: https://politica.expansion.mx/mexico. |
| [23] | Tang B, Bragazzi NL, Li Q, et al. (2020) An updated estimation of the risk of transmission of the novel coronavirus (2019-nCov). Infect Dis Model 5: 248-255. |
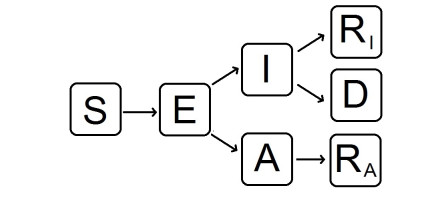
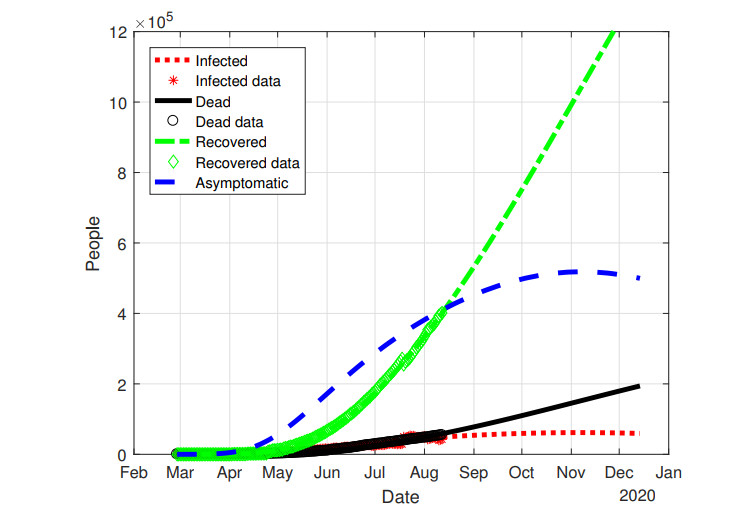
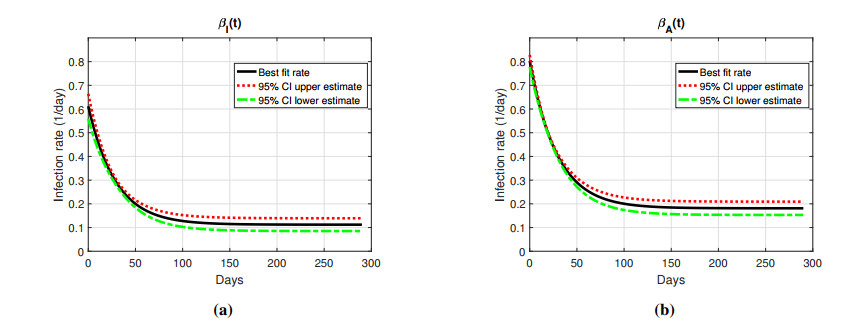
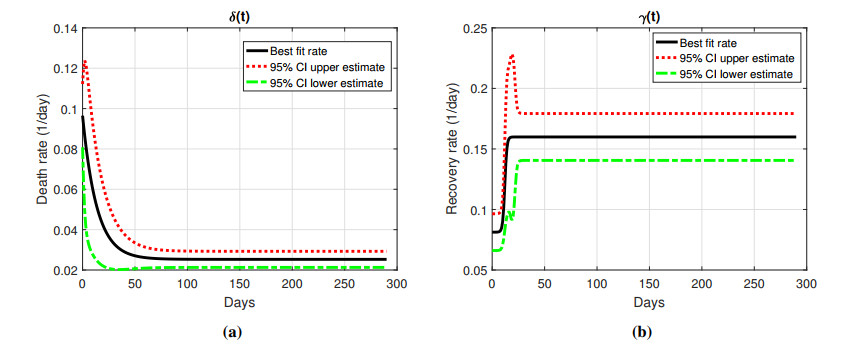
Figures(10) / Tables(1)

Ugo Avila-Ponce de León, Ángel G. C. Pérez, Eric Avila-Vales. A data driven analysis and forecast of an SEIARD epidemic model for COVID-19 in Mexico[J]. Big Data and Information Analytics, 2020, 5(1): 14-28. doi: 10.3934/bdia.2020002









 DownLoad:
DownLoad: