Citation: Ruiqi Li, Yifan Chen, Xiang Zhao, Yanli Hu, Weidong Xiao. TIME SERIES BASED URBAN AIR QUALITY PREDICATION[J]. Big Data and Information Analytics, 2016, 1(2): 171-183. doi: 10.3934/bdia.2016003

| [1] | [ L. Bin-lian, G. Feng and J. Jian-hua, Analysis of pm2.5 current situation and the prevention control measures, energy and energy conservation, 54-54. |
| [2] | [ D. Hasenfratz, O. Saukh, S. Sturzenegger, and L. Thiele, Participatory air pollution monitoring using smartphones, In the 2nd International Workshop on Mobile Sensing. |
| [3] | [ Y. Jiang, K. Li, L. Tian, R. Piedrahita, X. Yun, O. Mansata, Q. Lv, R. P. Dick, M. Hannigan and L. Shang, Maqs:a personalized mobile sensing system for indoor air quality monitoring, in Proceedings of the 13th international conference on Ubiquitous computing, 2011, 271-280. |
| [4] | [ L. N. Lamsal, R. V. Martin, A. V. Donkelaar, M. Steinbacher, E. A. Celarier, E. Bucsela, E. J. Dunlea and J. P. Pinto, Ground-level nitrogen dioxide concentrations inferred from the satellite-borne ozone monitoring instrument, Journal of Geophysical Research, 113(2008), 280-288. |
| [5] | [ R. V. Martin, L. Lamsal and A. Van Donkelaar, Satellite remote sensing of surface air quality, Atmospheric Environment, 42(2008), 7823-7843. |
| [6] | [ S. Vardoulakis, B. E. Fisher, K. Pericleous and N. Gonzalez-Flesca, Modelling air quality in street canyons:A review, Atmospheric environment, 37(2003), 155-182. |
| [7] | [ J. Yuan, Y. Zheng and X. Xie, Discovering regions of different functions in a city using human mobility and pois, in Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining, ACM, 2012, 186-194. |
| [8] | [ F. Zhang, D. Wilkie, Y. Zheng, and X. Xie., Sensing the pulse of urban refueling behavior, Proceedings of Acm International Conference on Ubiquitous Computing Ubicomp 11 Acm. |
| [9] | [ Y. Zhang and L. Y. Yang, On the applications of the additive model and multiplicative model of time series analysis, Statistics and Information Tribune. |
| [10] | [ Y. Zheng, F. Liu and H.-P. Hsieh, U-air:When urban air quality inference meets big data, in Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining, ACM, 2013, 1436-1444. |
| [11] | [ Y. Zheng, Y. Liu, J. Yuan and X. Xie, Urban computing with taxicabs, in Proceedings of the 13th international conference on Ubiquitous computing, ACM, 2011, 89-98. |
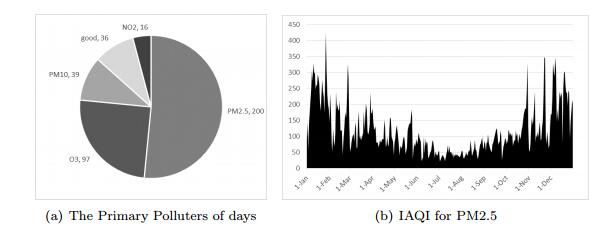
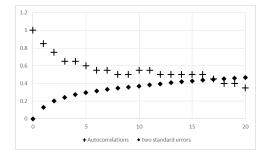
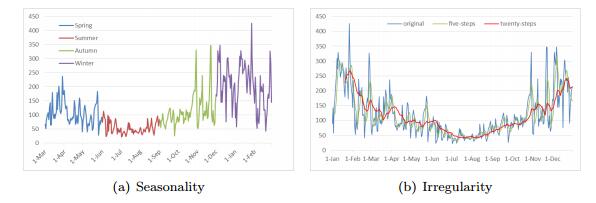
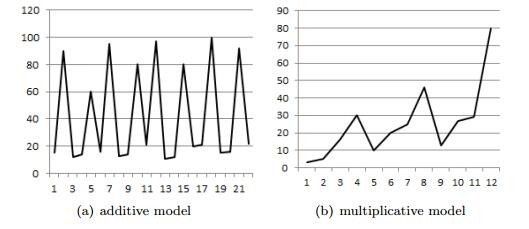
Figures(12) / Tables(4)

Ruiqi Li, Yifan Chen, Xiang Zhao, Yanli Hu, Weidong Xiao. TIME SERIES BASED URBAN AIR QUALITY PREDICATION[J]. Big Data and Information Analytics, 2016, 1(2): 171-183. doi: 10.3934/bdia.2016003









 DownLoad:
DownLoad: