Citation: Weidong Bao, Wenhua Xiao, Haoran Ji, Chao Chen, Xiaomin Zhu, Jianhong Wu. Towards big data processing in clouds: An online cost-minimization approach[J]. Big Data and Information Analytics, 2016, 1(1): 15-29. doi: 10.3934/bdia.2016.1.15

| [1] | [ Moving an elephant:Large scale hadoop data migration at facebook, http://www.facebook.com/notes/paul-yang/moving-an-elephant-large-scale-hadoop-data-migration-at-facebook/10150246275318920. |
| [2] | [ AWS Import/Export, http://aws.amazon.com/importexport/. |
| [3] | [ P. Barham, B. Dragovic and K. Fraser, Xen and the art of virtualization, SIGOPS Operating Systems Review, 37(2003), 164-177. |
| [4] | [ B. Cho and I. Gupta, New algorithms for planning bulk transfer via internet and shipping networks, in Proc. IEEE ICDCS, (2010), 305-314. |
| [5] | [ B. Cho and I. Gupta, Budget-constrained bulk data transfer via internet and shipping networks, in Proc. ACM ICAC, (2011), 71-80. |
| [6] | [ J. Dean and S. Ghemawat, MapReduce:Simplified data processing on large clusters, Communications of the ACM, 51(2008), 107-113. |
| [7] | [ Y. Feng, B. Li and B. Li, Airlift:Video conferencing as a cloud service using interdatacenter networks, in Proceedings of the IEEE International Conference on Network Protocols(ICNP'12), (2012), 1-11. |
| [8] | [ L. Georgiadis, M. J. Neely and L. Tassiulas, Resource allocation and cross-layer control in wireless networks, Foundations and Trends in Networking, 1(2006), 1-144. |
| [9] | [ Z. Huang, C. Mei, L. Li and T. Woo, CloudStream:Delivering high-quality streaming videos through a cloud-based SVC proxy, in Proceedings of the IEEE INFOCOM, (2011), 201-205. |
| [10] | [ F. Liu, Z. Zhou, H. Jin, B. Li, B. Li and H. Jiang, On arbitrating the power-performance tradeoff in SaaS clouds, IEEE Transactions on Parallel and Distributed Systems, 25(2014), 2648-2658. |
| [11] | [ X. Mo and H. Wang, Asynchronous index strategy for high performance real-time big data stream storage, in Network Infrastructure and Digital Content (IC-NIDC), (2012), 232-236. |
| [12] | [ X. Nan, Y. He and L. Guan, Optimal resource allocation for multimedia cloud based on queuing model, in Proc. of IEEE MMSP Workshop, (2011), 1-6. |
| [13] | [ M. J. Neely, Stochastic Network Optimization with Application to Communication and Queueing Systems, Morgan and Claypool, 2010. |
| [14] | [ M. J. Neely, Opportunistic scheduling with worst case delay guarantees in single and multi-hop networks, in Proc. of INFOCOM, (2011), 1728-1736. |
| [15] | [ E. E. Schadt, M. D. Linderman, J. Sorenson, L. Lee and G. P. Nolan, Computational solutions to large-scale data management and analysis, Nat Rev Genet, 11(2010), 647-657. |
| [16] | [ J. Tang, W. P. Tay and Y. Wen, Dynamic request redirection and elastic service scaling in cloud-centric media networks, IEEE Transactions on Multimedia, 16(2014), 1434-1445. |
| [17] | [ L. Tassiulas and A. Ephremides, Stability properties of constrained queueing systems and scheduling policies for maximum throughput in multihop radio networks, IEEE Transactions on Automatic Control, 37(1992), 1936-1948. |
| [18] | [ C. Union, Homepage http://www.cloudunion.cn/. |
| [19] | [ R. Urgaonkar, U. Kozat, K. Igarashi and M. J. Neely, Resource allocation and power management in virtualized data centers, in Proceedings of the IEEE Network Operations and Management Symp(NOMS'10), (2010), 479-486. |
| [20] | [ J. Wang, W. Bao, X. Zhu, L. T. Yang and Y. Xiang, FESTAL:Fault-tolerant elastic scheduling algorithm for real-time tasks in virtualized clouds, IEEE Transactions on Computers, 64(2014), 2445-2558. |
| [21] | [ F. Wang, J. Liu and M. Chen, CALMS:Cloud-assisted live media streaming for globalized demands with time/region diversities, in Proceedings of the IEEE INFOCOM, (2012), 199-207. |
| [22] | [ D. Wu, Z. Xue and J. He, iCloudAccess:Cost-effective streaming of videogames from the cloud with low latency, IEEE Transactions on Circuits and Systems for Video Technology, 28(2014), 1405-1416. |
| [23] | [ Y. Wu, C. Wu, B. Li, X. Qiu and F.C.M. Lau, Cloudmedia:When cloud on demand meets video on demand, In Proc. of IEEE ICDCS, (2011), 268-277. |
| [24] | [ Y. Wu, C. Wu, B. Li, L. Zhang, Z. Li and F. Lau, Scaling social media applications into geo-distributed clouds, in Proc. IEEE INFOCOM, (2012), 684-692. |
| [25] | [ W. Xiao, W. Bao, X. Zhu, C. Wang, L. Chen and L. T. Yang, Dynamic request redirection and resource provisioning for cloud-based video services under heterogeneous environment, IEEE Transactions on Parallel and Distributed Systems, pp (2015), p1. |
| [26] | [ Y. Yao, L. Huang and A. B. Sharma, L. Golubchik and M. J. Neely, Power cost reduction in distributed data centers:A two-time-scale approach for delay tolerant workloads, IEEE Transactions On Parallel and Distributed Systems, 25(2014), 200-211. |
| [27] | [ M. Zaharia, M. Chowdhury, M. J. Franklin, S. Shenker and I. Stoica. Spark:cluster computing with working sets, In Proceedings of the 2Nd USENIX Conference on Hot Topics in Cloud Computing(HotCloud'10), Berkeley, CA, USA, (2010), p10. |
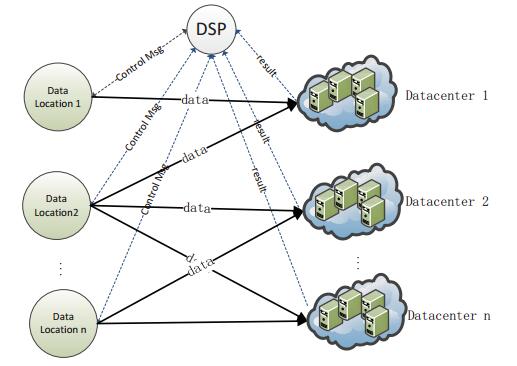
Figures(1) / Tables(1)

Weidong Bao, Wenhua Xiao, Haoran Ji, Chao Chen, Xiaomin Zhu, Jianhong Wu. Towards big data processing in clouds: An online cost-minimization approach[J]. Big Data and Information Analytics, 2016, 1(1): 15-29. doi: 10.3934/bdia.2016.1.15









 DownLoad:
DownLoad: