Citation: Stefania Conti, Santi A. Rizzo, Nunzio Salerno, Giuseppe M. Tina. Distribution network topology identification based on synchrophasor[J]. AIMS Energy, 2018, 6(2): 245-260. doi: 10.3934/energy.2018.2.245

| [1] | Monticelli A (2004) Electric power system state estimation. P IEEE 88: 262–282. |
| [2] |
Kumar DMV, Srivastava SC, Shah S, et al. (1996) Topology processing and static state estimation using artificial neural networks. IEE P-Gener Transm D 143: 99–105. doi: 10.1049/ip-gtd:19960050

|
| [3] | Clements KA, Costa AS (2002) Topology error identification using normalized Lagrange multipliers. IEEE T Power Syst 13: 347–353. |
| [4] | Singh N, Glavitsch H (1991) Detection and identification of topological errors in on line power system analysis. IEEE T Power Syst 6: 324–331. |
| [5] |
Costa IS, Leao JA (1993) Identification of topology errors in power system state estimation. IEEE T Power Syst 8: 1531–1538. doi: 10.1109/59.260956
|
| [6] |
Silva APAD, Quintana VH, Silva APAD, et al. (1995) Pattern analysis in power system state estimation. Int J Elec Power 17: 51–60. doi: 10.1016/0142-0615(95)93277-6
|
| [7] |
Singh D, Pandey JP, Chauhan DS (2005) Topology identification, bad data processing, and state estimation using fuzzy pattern matching. IEEE T Power Syst 20: 1570–1579. doi: 10.1109/TPWRS.2005.852086
|
| [8] | Deka D, Backhaus S, Chertkov M (2015) Structure learning and statistical estimation in distribution networks-Part II. Eprint Arxiv, 1–1. |
| [9] | Bolognani S, Bof N, Michelotti D, et al. (2013) Identification of power distribution network topology via voltage correlation analysis. IEEE Conference on Decision and Control. IEEE, 1659–1664. |
| [10] |
Moslehi K, Kumar R (2010) A reliability perspective of the smart grid. IEEE T Smart Grid 1: 57–64. doi: 10.1109/TSG.2010.2046346
|
| [11] | Conti S, Rizzo SA, El-Saadany EF, et al. (2014) Reliability assessment of distribution systems considering telecontrolled switches and microgrids. IEEE T Power Syst 29: 598–607. |
| [12] |
Rueda JL, Guaman WH, Cepeda JC, et al. (2013) Hybrid approach for power system operational planning with smart grid and small-signal stability enhancement considerations. IEEE T Smart Grid 4: 530–539. doi: 10.1109/TSG.2012.2222678
|
| [13] | Moeini-Aghtaie M, Farzin H, Fotuhi-Firuzabad M, et al. (2016) Generalized analytical approach to assess reliability of renewable-based energy hubs. IEEE T Power Syst 32: 368–377. |
| [14] |
Minciardi R, Sacile R (2012) Optimal control in a cooperative network of smart power grids. IEEE Syst J 6: 126–133. doi: 10.1109/JSYST.2011.2163016
|
| [15] | Zubo RHA, Mokryani G, Rajamani HS, et al. (2016) Operation and planning of distribution networks with integration of renewable distributed generators considering uncertainties: A review. Renew Sust Energ Rev 72: 1177–1198. |
| [16] |
Soltani NY, Kim SJ, Giannakis GB (2015) Real-time load elasticity tracking and pricing for electric vehicle charging. IEEE T Smart Grid 6: 1303–1313. doi: 10.1109/TSG.2014.2363837
|
| [17] |
Gungor VC, Sahin D, Kocak T, et al. (2011) Smart grid technologies: communication technologies and standards. IEEE T Ind Inform 7: 529–539. doi: 10.1109/TII.2011.2166794
|
| [18] |
Hamilton B, Summy M (2011) Benefits of the smart grid [In My View]. IEEE Power Energy M 9: 104–112. doi: 10.1109/MPE.2010.939468
|
| [19] |
Ansari N (2013) CONSUMER: A novel hybrid intrusion detection system for distribution networks in smart grid. IEEE T Emerg Top Com 1: 33–44. doi: 10.1109/TETC.2013.2274043
|
| [20] |
Conti S, Corte AL, Nicolosi R, et al. (2016) Impact of cyber-physical system vulnerability, telecontrol system availability and islanding on distribution network reliability. Sust Energ Grid Netw 6: 143–151. doi: 10.1016/j.segan.2016.03.003
|
| [21] |
Davis KR, Davis CM, Zonouz SA, et al. (2015) A cyber-physical modeling and assessment framework for power grid infrastructures. IEEE T Smart Grid 6: 2464–2475. doi: 10.1109/TSG.2015.2424155
|
| [22] |
Hug G, Giampapa JA (2012) Vulnerability assessment of ac state estimation with respect to false data injection cyber-attacks. IEEE T Smart Grid 3: 1362–1370. doi: 10.1109/TSG.2012.2195338
|
| [23] | Li X, Poor HV, Scaglione A (2016) Blind topology identification for power systems. IEEE International Conference on Smart Grid Communications. IEEE, 91–96. |
| [24] |
Erseghe T, Tomasin S, Vigato A (2013) Topology estimation for smart micro grids via powerline communications. IEEE T Signal Proces 61: 3368–3377. doi: 10.1109/TSP.2013.2259826
|
| [25] | Zhao L, Song WZ, Tong L, et al. (2014) Topology identification in smart grid with limited measurements via convex optimization. Innovative Smart Grid Technologies-Asia. IEEE, 803–808. |
| [26] |
Singh R, Manitsas E, Pal BC, et al. (2010) A recursive bayesian approach for identification of network configuration changes in distribution system state estimation. IEEE T Power Syst 25: 1329–1336. doi: 10.1109/TPWRS.2010.2040294
|
| [27] |
Luan W, Peng J, Maras M, et al. (2015) Smart meter data analytics for distribution network connectivity verification. IEEE T Smart Grid 6: 1964–1971. doi: 10.1109/TSG.2015.2421304
|
| [28] |
Chatzarakis GE (2009) Nodal analysis optimization based on the use of virtual current sources: A powerful new pedagogical method. IEEE T Educ 52: 144–150. doi: 10.1109/TE.2008.921459
|
| [29] | Phasor Advanced FAQ-Phasor-RTDMS: Available from: http://www.phasor-rtdms.com/phaserconcepts/phasor_adv_faq.html. |
| [30] | Vetter WJ (1975) Vector structures and solutions of linear matrix equations. Linear Algebra & Its Applications 10: 181–188. |
| [31] | Depablos J, Centeno V, Phadke AG, et al. (2004) Comparative testing of synchronized phasor measurement units. Power Engineering Society General Meeting. IEEE 1: 948–954. |
| [32] |
Baran ME, Wu FF (1989) Network reconfiguration in distribution systems for loss reduction and load balancing. IEEE T Power Deliver 4: 1401–1407. doi: 10.1109/61.25627
|
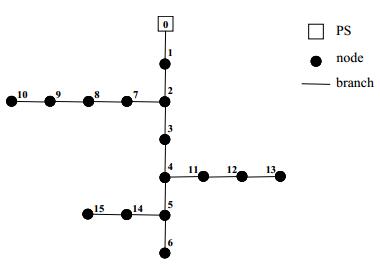
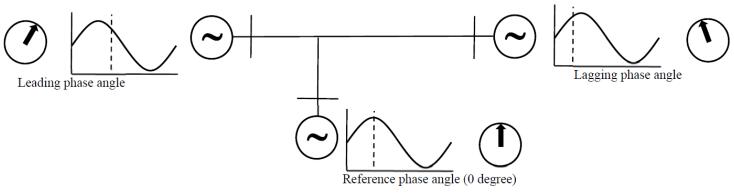

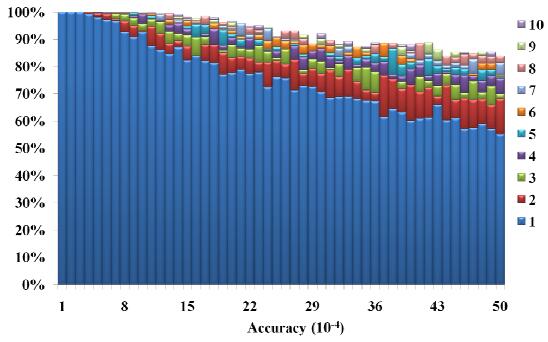
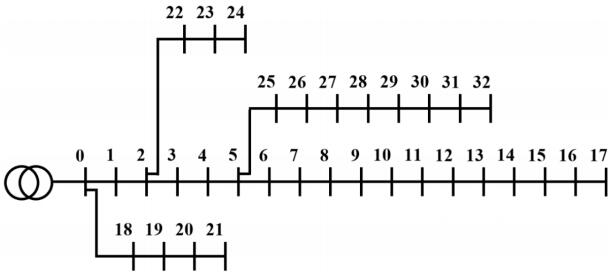
Figures(6)

Stefania Conti, Santi A. Rizzo, Nunzio Salerno, Giuseppe M. Tina. Distribution network topology identification based on synchrophasor[J]. AIMS Energy, 2018, 6(2): 245-260. doi: 10.3934/energy.2018.2.245







 DownLoad:
DownLoad: