We propose the first subquadratic-time algorithms to a number of natural problems inabelian pattern matching (also called jumbled pattern matching) for strings over a constant-sized alphabet.Two strings are considered equivalent in this model if the numbers of occurrences of respectivesymbols in both of them, specified by their so-called Parikh vectors, are the same. We consider theproblems of computing abelian squares, abelian periods, abelian runs, abelian covers, and abelian borders.This work can be viewed as a continuation of a recent very active line of research on subquadraticspace and time jumbled indexing for binary and constant-sized alphabets (e.g., Moosa and Rahman,2012). Our algorithms apply the so-called four Russian technique in a fancy way and work in linearspace. The purpose of this work is to show that breaking the O(n2) barrier is possible for the aforementionedproblems. In this paper we extend our previous work, published in a preliminary form atMACIS 2015 conference, with effcient computation of abelian runs.
Citation: Tomasz Kociumaka, Jakub Radoszewski, Bartłomiej Wiśniewski. Subquadratic-Time Algorithms for Abelian Stringology Problems[J]. AIMS Medical Science, 2017, 4(3): 332-351. doi: 10.3934/medsci.2017.3.332
We propose the first subquadratic-time algorithms to a number of natural problems inabelian pattern matching (also called jumbled pattern matching) for strings over a constant-sized alphabet.Two strings are considered equivalent in this model if the numbers of occurrences of respectivesymbols in both of them, specified by their so-called Parikh vectors, are the same. We consider theproblems of computing abelian squares, abelian periods, abelian runs, abelian covers, and abelian borders.This work can be viewed as a continuation of a recent very active line of research on subquadraticspace and time jumbled indexing for binary and constant-sized alphabets (e.g., Moosa and Rahman,2012). Our algorithms apply the so-called four Russian technique in a fancy way and work in linearspace. The purpose of this work is to show that breaking the O(n2) barrier is possible for the aforementionedproblems. In this paper we extend our previous work, published in a preliminary form atMACIS 2015 conference, with effcient computation of abelian runs.

| [1] |
Burcsi P, Cicalese F, Fici G, et al. (2010) On Table Arrangements, Scrabble Freaks, and Jumbled Pattern Matching. In: Fun with Algorithms, 5th International Conference. Springer: 89-101. doi: 10.1007/978-3-642-13122-6_11

|
| [2] |
Chan TM, Lewenstein M (2015) Clustered integer 3SUM via additive combinatorics. In: Proceedings of the forty-seventh annual ACM Symposium on Theory of Computing. ACM: 31-40. doi: 10.1145/2746539.2746568
|
| [3] | Cicalese F, Fici G, Lipták Z (2009) Searching for Jumbled Patterns in Strings. In: Stringology: 105-117. |
| [4] | Hermelin D, Landau GM, Rabinovich Y, et al. (2014) Binary jumbled pattern matching via all-pairs shortest paths. arXiv preprint arXiv:1401.2065, 2014. |
| [5] | Kociumaka T, Radoszewski J, RytterW(2013) Effcient indexes for jumbled pattern matching with constant-sized alphabet. Algorithmica 77: 1194-1215. |
| [6] |
Moosa TM, Rahman MS (2010) Indexing permutations for binary strings. Inf Process Lett 110: 795-798. doi: 10.1016/j.ipl.2010.06.012
|
| [7] |
Moosa TM, Rahman MS (2012) Sub-quadratic time and linear space data structures for permutation matching in binary strings. J Discrete Algorithms 10: 5-9. doi: 10.1016/j.jda.2011.08.003
|
| [8] | Erdos P (1961) Some unsolved problems. Hungarian Academy of Sciences Mat. Kutató Intézet Közl 6: 221–254. |
| [9] | Cummings LJ, Smyth WF (1997) Weak repetitions in strings. JCMCC 24: 33-48. |
| [10] | Constantinescu S, Ilie L (2006) Fine and Wilf's Theorem for Abelian Periods. Bulletin of the EATCS 89: 167-170. |
| [11] | Matsuda S, Inenaga S, Bannai H, et al. (2014) Computing Abelian Covers and Abelian Runs. In: Stringology, 43-51. |
| [12] |
Fici G, Kociumaka T, Lecroq T, et al. (2016) Fast computation of abelian runs. Theor Comput Sci 656: 256-264. doi: 10.1016/j.tcs.2015.12.010
|
| [13] |
Fici G, Lecroq T, Lefebvre A, et al. (2014) Algorithms for computing Abelian periods of words. Discrete Appl Math 163: 287-297. doi: 10.1016/j.dam.2013.08.021
|
| [14] |
Crochemore M, Iliopoulos CS, Kociumaka T, et al. (2013) A note on effcient computation of all Abelian periods in a string. Inf Process Lett 113: 74-77. doi: 10.1016/j.ipl.2012.11.001
|
| [15] |
Fici G, Lecroq T, Lefebvre A, et al. (2016) A note on easy and effcient computation of full abelian periods of a word. Discrete Appl Math 212: 88-95. doi: 10.1016/j.dam.2015.09.024
|
| [16] |
Kociumaka T, Radoszewski J, Rytter W (2017) Fast algorithms for abelian periods in words and greatest common divisor queries. J Comput Syst Sci 84: 205–218. doi: 10.1016/j.jcss.2016.09.003
|
| [17] |
Amir A, Apostolico A, Hirst T, et al. (2016) Algorithms for jumbled indexing, jumbled border and jumbled square on run-length encoded strings. Theor Comput Sci 656:146–159. doi: 10.1016/j.tcs.2016.04.030
|
| [18] | Sugimoto S, Noda N, Inenaga S, et al. (2017) Computing Abelian regularities on RLE strings. arXiv preprint arXiv:1701.02836, 2017. |
| [19] | Kociumaka T, Radoszewski J, Wiśniewski B (2015) Subquadratic-time algorithms for Abelian stringology problems. In: International Conference on Mathematical Aspects of Computer and Information Sciences. Springer: 320-334. |
| [20] |
Kolpakov R, Kucherov G (1999) Finding maximal repetitions in a word in linear time. In: 40th Annual Symposium on Foundations of Computer Science. IEEE: 596-604. doi: 10.1109/SFFCS.1999.814634
|
| [21] | Kolpakov RM, Kucherov G (2000) On maximal repetitions in words. J Discrete Algorithms: 159–186. |
| [22] | Cormen TH, Leiserson CE, Rivest RL, et al. (2009) Introduction to Algorithms. 3 ed. MIT Press. |
| [23] | Amir A, Chan TM, Lewenstein M, et al. (2014) On hardness of jumbled indexing. In: International Colloquium on Automata, Languages, and Programming. Springer: 114-125. |
| [24] | Goldstein I, Kopelowitz T, Lewenstein M, et al. (2017) How hard is it to find (honest) witnesses? European Symposium on Algorithms. Schloss Dagstuhl: 45:1-45:16. |
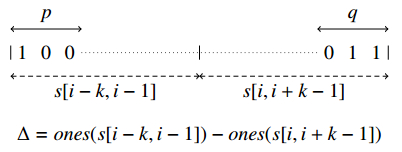
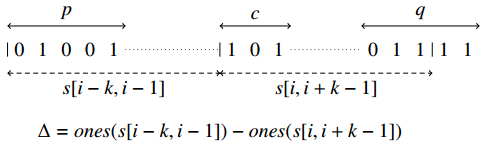
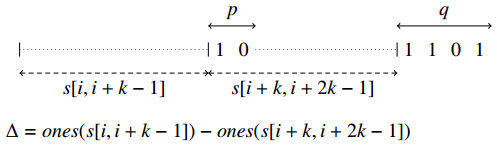
Figures(3)

Tomasz Kociumaka, Jakub Radoszewski, Bartłomiej Wiśniewski. Subquadratic-Time Algorithms for Abelian Stringology Problems[J]. AIMS Medical Science, 2017, 4(3): 332-351. doi: 10.3934/medsci.2017.3.332







 DownLoad:
DownLoad: