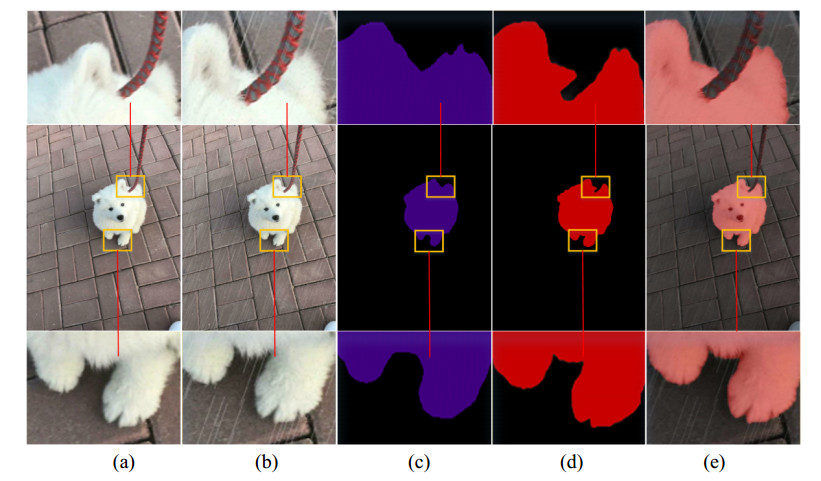
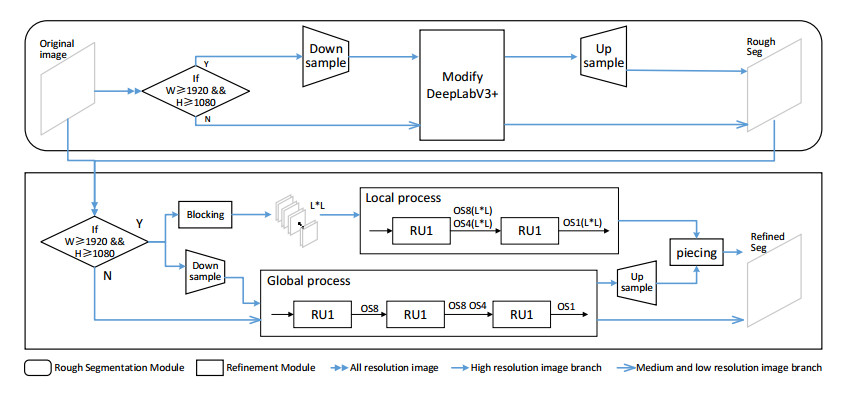
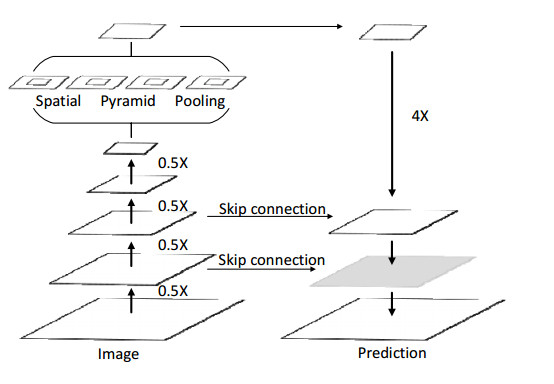
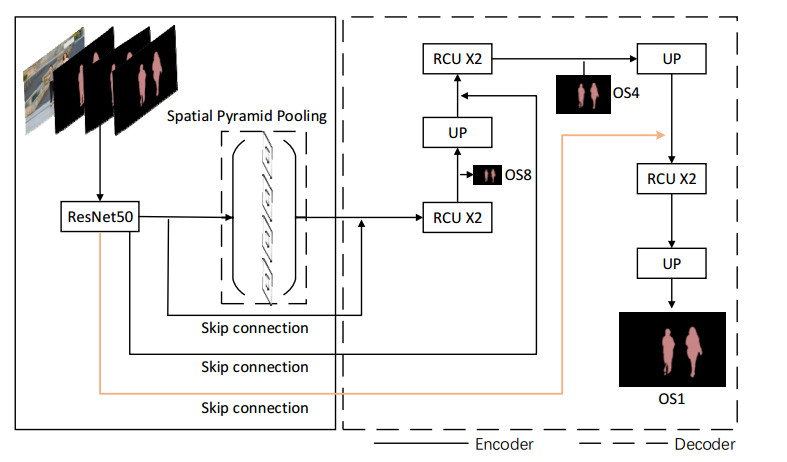
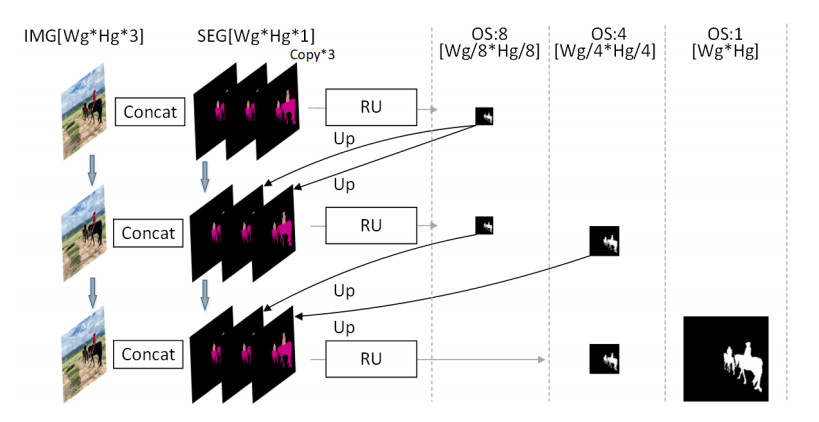
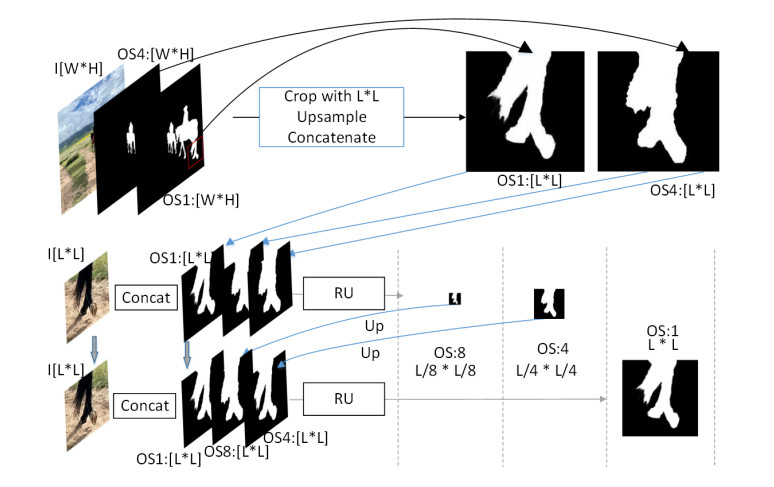
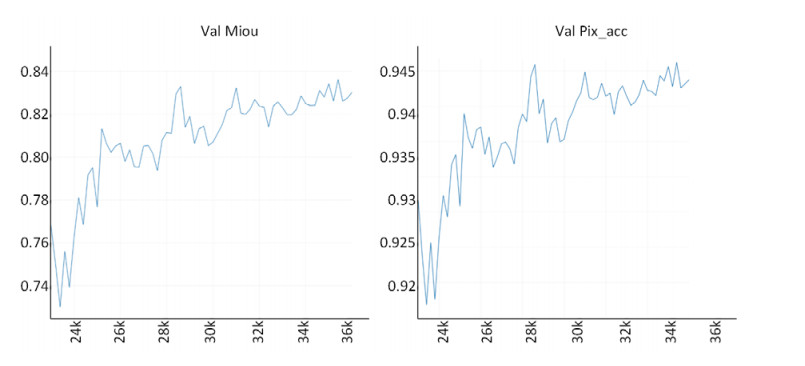
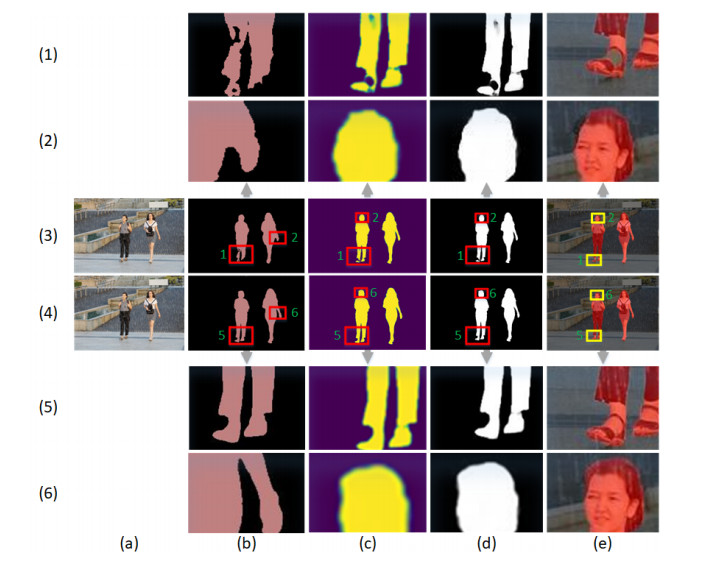
Limited by GPU memory, high-resolution image segmentation is a highly challenging task. To improve the accuracy of high-resolution segmentation, High-Resolution Refine Net (HRRNet) is proposed. The network is divided into a rough segmentation module and a refinement module. The former improves DeepLabV3+ by adding the shallow features of 1/2 original image size and the corresponding skip connection to obtain better rough segmentation results, the output of which is used as the input of the latter. In the refinement module, first, the global context information of the input image is obtained by a global process. Second, the high-resolution image is divided into patches, and each patch is processed separately to obtain local details in a local process. In both processes, multiple refine units (RU) are cascaded for refinement processing, and two cascaded residual convolutional units (RCU) are added to the different output paths of RU to improve the mIoU and the convergence speed of the network. Finally, according to the context information of the global process, the refined patches are pieced to obtain the refined segmentation result of the whole high-resolution image. In addition, the regional non-maximum suppression is introduced to improve the Sobel edge detection, and the Pascal VOC 2012 dataset is enhanced, which improves the segmentation accuracy and robust performance of the network. Compared with the state-of-the-art semantic segmentation models, the experimental results show that our model achieves the best performance in high-resolution image segmentation.
Citation: Qiming Li, Chengcheng Chen. A robust and high-precision edge segmentation and refinement method for high-resolution images[J]. Mathematical Biosciences and Engineering, 2023, 20(1): 1058-1082. doi: 10.3934/mbe.2023049
Limited by GPU memory, high-resolution image segmentation is a highly challenging task. To improve the accuracy of high-resolution segmentation, High-Resolution Refine Net (HRRNet) is proposed. The network is divided into a rough segmentation module and a refinement module. The former improves DeepLabV3+ by adding the shallow features of 1/2 original image size and the corresponding skip connection to obtain better rough segmentation results, the output of which is used as the input of the latter. In the refinement module, first, the global context information of the input image is obtained by a global process. Second, the high-resolution image is divided into patches, and each patch is processed separately to obtain local details in a local process. In both processes, multiple refine units (RU) are cascaded for refinement processing, and two cascaded residual convolutional units (RCU) are added to the different output paths of RU to improve the mIoU and the convergence speed of the network. Finally, according to the context information of the global process, the refined patches are pieced to obtain the refined segmentation result of the whole high-resolution image. In addition, the regional non-maximum suppression is introduced to improve the Sobel edge detection, and the Pascal VOC 2012 dataset is enhanced, which improves the segmentation accuracy and robust performance of the network. Compared with the state-of-the-art semantic segmentation models, the experimental results show that our model achieves the best performance in high-resolution image segmentation.

| [1] | Z. Zheng, Y. Zhong, J. Wang, A. Ma, Foreground-aware relation network for geospatial object segmentation in high spatial resolution remote sensing imagery, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2020), 4095–4104. https://doi.org/10.1109/CVPR42600.2020.00415 |
| [2] | H. K. Cheng, J. Chung, Y. Tai, C. Tang, CascadePSP: Toward class-agnostic and very high-resolution segmentation via global and local refinement, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2020), 8887–8896. https://doi.org/10.1109/CVPR42600.2020.00891 |
| [3] | O. Ronneberger, P. Fischer, T. Brox, U-Net: Convolutional networks for biomedical image segmentation, in International Conference on Medical Image Computing and Computer-assisted Intervention, (2015), 234–241. https://doi.org/10.1007/978-3-319-24574-4_28 |
| [4] | E. Shelhamer, J. Long, T. Darrell, Fully convolutional networks for semantic segmentation, in IEEE Transactions on Pattern Analysis and Machine Intelligence, 39 (2015), 640–651. https://doi.org/10.1109/TPAMI.2016.2572683 |
| [5] |
V. Badrinarayanan, K. Kendall, R. Cipolla, SegNet: A deep convolutional encoder-decoder architecture for image segmentation, IEEE Trans. Pattern Anal. Mach. Intell., 39 (2017), 2481–2495. https://doi.org/10.1109/TPAMI.2016.2644615 doi: 10.1109/TPAMI.2016.2644615

|
| [6] | H. Zhao, J. Shi, X. Qi, X. Wang, J. Jia, Pyramid scene parsing network, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2017), 6230–6239. https://doi.org/10.1109/CVPR.2017.660 |
| [7] | W. Chen, Z. Jiang, Z. Wang, K. Cui, X. Qian, Collaborative global-local networks for memory-efficient segmentation of ultra-high resolution images, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6 (2019), 8916–8925. https://doi.org/10.1109/CVPR.2019.00913 |
| [8] | L. Chen, G. Papandreou, F. Schroff, H. Adam, Rethinking atrous convolution for semantic image segmentation, preprint, arXiv: 1706.05587. |
| [9] |
L. Chen, Y. Zhu, G. Papandreou, F. Schroff, H. Adam, Encoder-decoder with atrous separable convolution for semantic image segmentation, Lect. Notes Comput. Sci., 11211 (2018), 833–851. https://doi.org/10.1007/978-3-030-01234-2_49 doi: 10.1007/978-3-030-01234-2_49
|
| [10] |
L. Chen, G. Papandreou, K. Murphy, A. Yuille, DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs, IEEE Trans. Pattern Anal. Mach. Intell., 40 (2018), 834–848. https://doi.org/10.1109/TPAMI.2017.2699184 doi: 10.1109/TPAMI.2017.2699184
|
| [11] | G. Lin, A. Milan, C. Shen, I. Reid, RefineNet: Multi-path refinement networks for high-resolution semantic segmentation, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 6 (2017), 5168–5177. https://doi.org/10.1109/CVPR.2017.549 |
| [12] | I. Demir, K. Koperski, D. Lindenbaum, G. Pang, J. Huang, S. Basu, et al., DeepGlobe 2018: A challenge to parse the earth through satellite images, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 6 (2018), 172–181. https://doi.org/10.1109/CVPRW.2018.00031 |
| [13] |
C. Yu, J. Wang, C. Peng, C. Gao, G. Yu, N. Sang, BiSeNet: Bilateral segmentation network for real-time semantic segmentation, Lect. Notes Comput. Sci. 11217 (2018), 334–349. https://doi.org/10.1007/978-3-030-01261-8_20 doi: 10.1007/978-3-030-01261-8_20
|
| [14] |
C. Yu, C. Gao, J. Wang, G. Yu, C. Shen, N. Sang, BiSeNet V2: Bilateral network with guided aggregation for real-time semantic segmentation, Int. J. Comput. Vision, 129 (2021), 3051–3068. https://doi.org/10.1007/s11263-021-01515-2 doi: 10.1007/s11263-021-01515-2
|
| [15] | X. Li, T. Lai, S. Wang, Q. Chen, C. Yang, R. Chen, et al., Weighted feature pyramid networks for object detection, in 2019 IEEE International Conference on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking, (2019), 1500–1504. https://doi.org/10.1109/ISPA-BDCloud-SustainCom-SocialCom48970.2019.00217 |
| [16] |
M. Drozdzal, E. Vorontsov, G. Chartrand, S. Kadoury, C. Pal, The importance of skip connections in biomedical image segmentation, Lect. Notes Comput. Sci., 10008 (2016), 179–187. https://doi.org/10.1007/978-3-319-46976-8_19 doi: 10.1007/978-3-319-46976-8_19
|
| [17] | J. Fu, J. Liu, H. Tian, Y. Li, Y. Bao, Z. Fang, et al., Dual attention network for scene segmentation, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6 (2019), 3141–3149. https://doi.org/10.1109/CVPR.2019.00326 |
| [18] | Z. Huang, X. Wang, Y. Wei, L. Huang, H. Shi, W. Liu, et al., CCNet: Criss-cross attention for semantic segmentation, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10 (2019), 603–612. https://doi.org/10.1109/ICCV.2019.00069 |
| [19] | X. Wang, R. Girshick, A. Gupta, K. He, Non-local neural networks, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 7794–7803. https://doi.org/10.1109/CVPR.2018.00813 |
| [20] |
S. Woo, J. Park, J. Lee, I. S. Kweon, CBAM: Convolutional block attention module, Lect. Notes Comput. Sci., 11211 (2018), 3–19. https://doi.org/10.1007/978-3-030-01234-2_1 doi: 10.1007/978-3-030-01234-2_1
|
| [21] | C. Zhang, G. Lin, F. Liu, R. Yao, C. Shen, CANet: Class-agnostic segmentation networks with iterative refinement and attentive few-shot learning, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6 (2019), 5212–5221. https://doi.org/10.1109/CVPR.2019.00536 |
| [22] |
H. Zhou, J. Du, Y. Zhang, Q. Wang, Q. Liu, C. Lee, Information fusion in attention networks using adaptive and multi-level factorized bilinear pooling for audio-visual emotion recognition, IEEE/ACM Trans. Audio Speech Lang. Process., 29 (2021), 2617–2629. https://doi.org/10.1109/TASLP.2021.3096037 doi: 10.1109/TASLP.2021.3096037
|
| [23] | R. Ranftl, A. Bochkovskiy, V. Koltun, Vision transformers for dense prediction, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2021), 12159–12168. https://doi.org/10.1109/ICCV48922.2021.01196 |
| [24] | R. Strudel, R. Garcia, I. Laptev, C. Schmid, Segmenter: Transformer for semantic segmentation, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2021), 7242–7252. https://doi.org/10.1109/ICCV48922.2021.00717 |
| [25] |
E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, P. Luo, SegFormer: Simple and efficient design for semantic segmentation with transformers, Adv. Neural Inf. Process. Syst., 15 (2021), 12077–12090. https://doi.org/10.48550/arXiv.2105.15203 doi: 10.48550/arXiv.2105.15203
|
| [26] | S. Zheng, J. Lu, H. Zhao, X. Zhu, Z. Luo, Y. Wang, et al., Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2021), 6877–6886. https://doi.org/10.1109/CVPR46437.2021.00681 |
| [27] |
K. Khan, N. Ahmad, K. Ullah, I. Din, Multiclass semantic segmentation of faces using CRFs, Turkish J. Electr. Eng. Comput. Sci., 25 (2017), 3164–3174. https://doi.org/10.3906/elk-1607-332 doi: 10.3906/elk-1607-332
|
| [28] | M. T. T. Teichmann, R. Cipolla, Convolutional CRFs for semantic segmentation, preprint, arXiv: 1805.04777. |
| [29] | Y. Kinoshita, H. Kiya, Fixed smooth convolutional layer for avoiding checkerboard artifacts in CNNs, in ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 5 (2020), 3712–3716. https://doi.org/10.1109/ICASSP40776.2020.9054096 |
| [30] | L. Wang, D. Li, Y. Zhu, L. Tian, Y. Shan, Dual Super-resolution learning for semantic segmentation, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2020), 3773–3782. https://doi.org/10.1109/CVPR42600.2020.00383 |
| [31] | T. Hu, Y. Wang, Y. Chen, P. Lu, H. Wang, G. Wang, Sobel heuristic kernel for aerial semantic segmentation, in 2018 25th IEEE International Conference on Image Processing (ICIP), (2018), 3074–3078. https://doi.org/10.1007/CVPR42870.2018.00670 |
| [32] | C. Huynh, A. T. Tran, K. Luu, M. Hoai, Progressive semantic segmentation, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 1 (2021), 16750–16759. https://doi.org/10.1109/CVPR46437.2021.01648 |
| [33] | Q. Li, W. Yang, W. Liu, Y. Yu. S. He, From contexts to locality: Ultra-high resolution image segmentation via locality-aware contextual correlation, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2021), 7232–7241. https://doi.org/ICCV48922.2021.00716 |
| [34] | X. Qi, M. Fei, H. Hu, H. Wang, A novel 3D expansion and corrosion method for human detection based on depth information, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 761 (2017), 556–565. https://doi.org/10.1007/978-981-10-6370-1 |
| [35] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 12 (2016), 770–778. https://doi.org/10.1109/CVPR.2016.90 |
| [36] |
M. Cheng, N. J. Mitra, X. Huang, P. H. S. Torr, S. Hu, Global contrast based salient region detection, IEEE Trans. Pattern Anal. Mach. Intell., 37 (2015), 569–582. https://doi.org/10.1109/TPAMI.2014.2345401 doi: 10.1109/TPAMI.2014.2345401
|
| [37] | C. Yang, L. Zhang, H. Lu, X. Ruan, M. Yang, Saliency detection via graph-based manifold ranking, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2013), 3166–3173. https://doi.org/10.1109/CVPR.2013.407 |
| [38] |
J. Shi, Q. Yan, L. Xu, J. Jia, Hierarchical image saliency detection on extended CSSD, IEEE Trans. Pattern Anal. Mach. Intell., 38 (2016), 717–729. https://doi.org/10.1109/TPAMI.2015.2465960 doi: 10.1109/TPAMI.2015.2465960
|
| [39] | X. Li, T. Wei, Y. Chen, Y. Tai, C. Tang, FSS-1000: A 1000-class dataset for few-shot segmentation, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2020), 2866–2875. https://doi.org/10.1109/CVPR42600.2020.00294 |
| [40] | Q. Zhang, S. Zhao, Y. Luo, D. Zhang, N. Huang, J. Han, ABMDRNet: Adaptive-weighted bi-directional modality difference reduction network for rgb-t semantic segmentation, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2021), 2633–2642. https://doi.org/CVPR46437.2021.00266 |
| [41] | K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition, preprint, arXiv: 1409.1556. |
| [42] | A. Howard, M. Sandler, G. Chu, L. Chen, B. Chen, M. Tan, et al., Searching for mobileNetV3, in Proceedings of the IEEE/CVF International Conference on Computer Vision, 10 (2019), 1314–1324. https://doi.org/10.1109/ICCV.2019.00140 |
| [43] | M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, L. Chen, MobileNetV2: Inverted residuals and linear bottlenecks, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2018), 4510–4520. https://doi.org/10.1109/CVPR.2018.00474 |
| [44] | A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, MobileNets: Efficient convolutional neural networks for mobile vision applications, preprint, arXiv: 1704.04861. |
| [45] |
J. Sun, W. Lin, A target recognition algorithm of multi source remote sensing image based on visual internet of things, Mob. Networks Appl., 27 (2022), 784–793. https://doi.org/10.1007/s11036-021-01907-1 doi: 10.1007/s11036-021-01907-1
|
| [46] | W. Dong, D. Peng, X. Liu, T. Wang, J. Long, Eight direction improved Sobel algorithm based on morphological processing in 5G smart grid, in 2021 2nd International Conference on Computing, Networks and Internet of Things, (2021), 1–5. https://doi.org/10.1145/3468691.3468721 |
| [47] |
Y. Ma, H. Ma, P. Chu, Demonstration of quantum image edge extration enhancement through improved Sobel operator, IEEE Access, 8 (2020), 210277–210285. https://doi.org/10.1109/ACCESS.2020.3038891 doi: 10.1109/ACCESS.2020.3038891
|








Figures(16) / Tables(4)

Qiming Li, Chengcheng Chen. A robust and high-precision edge segmentation and refinement method for high-resolution images[J]. Mathematical Biosciences and Engineering, 2023, 20(1): 1058-1082. doi: 10.3934/mbe.2023049







 DownLoad:
DownLoad: