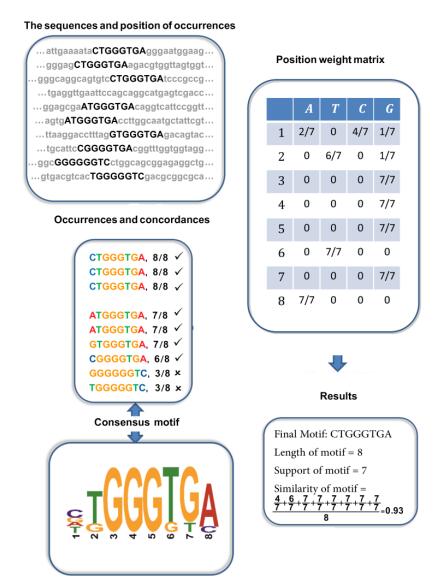
Motif discovery problem (MDP) is one of the well-known problems in biology which tries to find the transcription factor binding site (TFBS) in DNA sequences. In one aspect, there is not enough biological knowledge on motif sites and on the other side, the problem is NP-hard. Thus, there is not an efficient procedure capable of finding motifs in every dataset. Some algorithms use exhaustive search, which is very time-consuming for large-scale datasets. On the other side, metaheuristic procedures seem to be a good selection for finding a motif quickly that at least has some acceptable biological properties. Most of the previous methods model the problem as a single objective optimization problem; however, considering multi-objectives for modeling the problem leads to improvements in the quality of obtained motifs. Some multi-objective optimization models for MDP have tried to maximize three objectives simultaneously: Motif length, support, and similarity. In this study, the multi-objective Imperialist Competition Algorithm (ICA) is adopted for this problem as an approximation algorithm. ICA is able to simulate more exploration along the solution space, so avoids trapping into local optima. So, it promises to obtain good solutions in a reasonable time. Experimental results show that our method produces good solutions compared to well-known algorithms in the literature, according to computational and biological indicators.
Citation: Saeed Alirezanejad Gohardani, Mehri Bagherian, Hamidreza Vaziri. A multi-objective imperialist competitive algorithm (MOICA) for finding motifs in DNA sequences[J]. Mathematical Biosciences and Engineering, 2019, 16(3): 1575-1596. doi: 10.3934/mbe.2019075
Motif discovery problem (MDP) is one of the well-known problems in biology which tries to find the transcription factor binding site (TFBS) in DNA sequences. In one aspect, there is not enough biological knowledge on motif sites and on the other side, the problem is NP-hard. Thus, there is not an efficient procedure capable of finding motifs in every dataset. Some algorithms use exhaustive search, which is very time-consuming for large-scale datasets. On the other side, metaheuristic procedures seem to be a good selection for finding a motif quickly that at least has some acceptable biological properties. Most of the previous methods model the problem as a single objective optimization problem; however, considering multi-objectives for modeling the problem leads to improvements in the quality of obtained motifs. Some multi-objective optimization models for MDP have tried to maximize three objectives simultaneously: Motif length, support, and similarity. In this study, the multi-objective Imperialist Competition Algorithm (ICA) is adopted for this problem as an approximation algorithm. ICA is able to simulate more exploration along the solution space, so avoids trapping into local optima. So, it promises to obtain good solutions in a reasonable time. Experimental results show that our method produces good solutions compared to well-known algorithms in the literature, according to computational and biological indicators.

| [1] | F. Zare-Mirakabad, H. Ahrabian and M. Sadeghi, et al., Genetic algorithm for dyad pattern finding in DNA sequences, Genes Genet. Syst., 84 (2009), 81–93. |
| [2] | M. Li, B. Ma and L. Wang, Finding similar regions in many sequences, J. Comput. Syst. Sci., 65 (2002), 73–96. |
| [3] | M. F. Sagot, Spelling approximate repeated or common motifs using a suffix tree, Springer, 1998. |
| [4] | F. W. Glover and G. A. Kochenberger, Handbook of metaheuristics, Springer Science & Business Media, 2006. |
| [5] | E. Czeizler, T. Hirvola and K. Karhu, A graph-theoretical approach for motif discovery in protein sequences, IEEE/ACM Trans. Comput. Biol. Bioinf., 14 (2017), 121–130. |
| [6] | M. Kaya, MOGAMOD: Multi-objective genetic algorithm for motif discovery, Expert. Syst. Appl., 36 (2009), 1039–1047. |
| [7] | D. L. González-Álvarez, M. A. Vega-Rodríguez and Á. Rubio-Largo, Multiobjective optimization algorithms for motif discovery in DNA sequences, Genet. Program. Evolvable Mach., 16 (2015), 167–209. |
| [8] | C. E. Lawrence and A. A. Reilly, An expectation maximization (EM) algorithm for the identification and characterization of common sites in unaligned biopolymer sequences, Proteins, 7 (1990), 41–51. |
| [9] | C. E. Lawrence, S. F. Altschul and M. S. Boguski, et al., Detecting subtle sequence signals: A Gibbs sampling strategy for multiple alignment, Science, 262 (1993), 208–214. |
| [10] | T. L. Bailey and C. Elkan, Fitting a mixture model by expectation maximization to discover motifs in bipolymers, Proc. Int. Conf. Intell. Syst. Mol. Biol., 2 (1994), 28–36.. |
| [11] | F. P. Roth, J. D. Hughes and P. W. Estep, et al., Finding DNA regulatory motifs within unaligned noncoding sequences clustered by whole-genome mRNA quantitation, Nat. Biotechnol., 16 (1998), 939–945. |
| [12] | K. C. Wong, MotifHyades: Expectation maximization for de novo DNA motif pair discovery on paired sequences, Bioinformatics, 33 (2017), 3028–3035. |
| [13] | K. C. Wong, DNA Motif Recognition Modeling from Protein Sequences, iScience, 7 (2018), 198–211. |
| [14] | G. Pavesi, P. Mereghetti and G. Mauri, et al., Weeder Web: Discovery of transcription factor binding sites in a set of sequences from co-regulated genes. Nucleic Acids Res., 32 (2004), W199–W203. |
| [15] | E. Eskin and P. A. Pevzner, Finding composite regulatory patterns in DNA sequences, Bioinformatics, 18 (2002), S354–S363. |
| [16] | P. A. Evans and A. D. Smith, Toward optimal motif enumeration, Springer, 2003. |
| [17] | J. Serra, A. Matic and A. Karatzoglou, et al., A genetic algorithm to discover flexible motifs with support, IEEE, 2016. |
| [18] | N. Pisanti, A. M. Carvalho and L. Marsan, et al., RISOTTO: Fast extraction of motifs with mismatches, Springer, 2006. |
| [19] | G. Z. Hertz and G. D. Stormo, Identifying DNA and protein patterns with statistically significant alignments of multiple sequences, Bioinformatics, 15 (1999), 563–577. |
| [20] | D. L. González-Álvarez, M. A. Vega-Rodríguez and J. A. Gómez-Pulido, et al., Finding Motifs in DNA Sequences Applying a Multiobjective Artificial Bee Colony (MOABC) Algorithm, Springer, 2011. |
| [21] | D. L. González-Álvarez, M. A. Vega-Rodríguez and Á. Rubio-Largo, Searching for common patterns on protein sequences by means of a parallel hybrid honey-bee mating optimization algorithm, Parallel. Comput., 76 (2018), 1–17. |
| [22] | E. Zitzler and L. Thiele, Multiobjective evolutionary algorithms: A comparative case study and the strength Pareto approach, IEEE T. Evolut. Comput., 3 (1999), 257–271. |
| [23] | E. Wingender, P, Dietze and H. Karas, et al., TRANSFAC: A database on transcription factors and their DNA binding sites, Nucleic Acids Res., 24 (1996), 238–241. |
| [24] | D. L. González-Álvarez, M. A. Vega-Rodríguez and J. A. Gómez-Pulido, et al., Solving the motif discovery problem by using differential evolution with pareto tournaments, IEEE, 2010. |
| [25] | G. B. Fogel, D. G. Weekes and G. Varga, et al., Discovery of sequence motifs related to coexpression of genes using evolutionary computation, Nucleic Acids Res., 32 (2004), 3826–3835. |
| [26] | E. Zitzler, K. Deb and L. Thiele, Comparison of multiobjective evolutionary algorithms: Empirical results, Evolut. Comput., 8 (2000), 173–195. |
| [27] | E. Atashpaz-Gargari and C. Lucas, Imperialist competitive algorithm: An algorithm for optimization inspired by imperialistic competition, IEEE, 2007. |
| [28] | D. L. Gonzalez-Álvarez, M. A. Vega-Rodriguez and J. A. Gomez-Pulido, et al., Predicting DNA motifs by using evolutionary multiobjective optimization, IEEE. T. Syst. Man. Cy. C., 42 (2012), 913–925. |
| [29] | X. S. Yang, Firefly algorithms for multimodal optimization, Springer, 2009. |
| [30] | D. L. González-Álvarez, M. A. Vega-Rodríguez and J, A. Gómez-Pulido, et al., Applying a multiobjective gravitational search algorithm (MO-GSA) to discover motifs, Springer, 2011. |
| [31] | E. Zitzler, M. Laumanns and L. Thiele, SPEA2: Improving the strength Pareto evolutionary algorithm, 2001. |
| [32] | K. Deb, A. Pratap and S. Agarwal, et al., A fast and elitist multiobjective genetic algorithm: NSGA-II, IEEE T. Evolut. Comput., 6 (2002), 182–197. |
| [33] | M. Tompa, N. Li and T. L. Bailey, et al., Assessing computational tools for the discovery of transcription factor binding sites, Nat. Biotechnol., 23 (2005), 137. |
Figures(1) / Tables(6)

Saeed Alirezanejad Gohardani, Mehri Bagherian, Hamidreza Vaziri. A multi-objective imperialist competitive algorithm (MOICA) for finding motifs in DNA sequences[J]. Mathematical Biosciences and Engineering, 2019, 16(3): 1575-1596. doi: 10.3934/mbe.2019075







 DownLoad:
DownLoad: