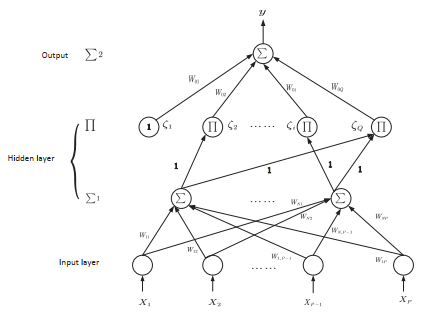
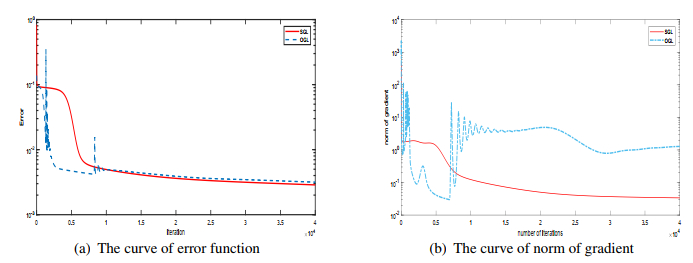
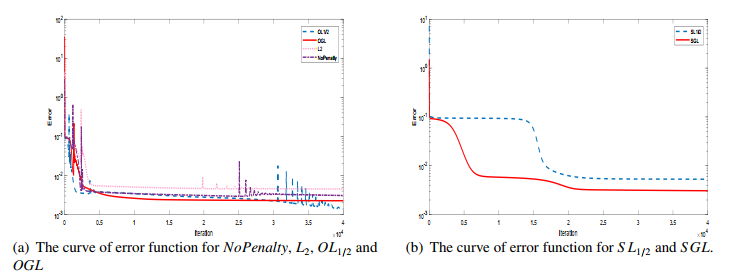
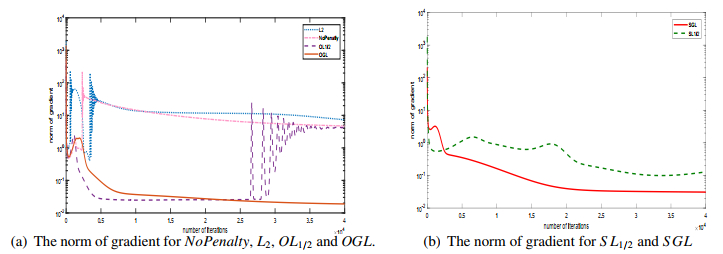
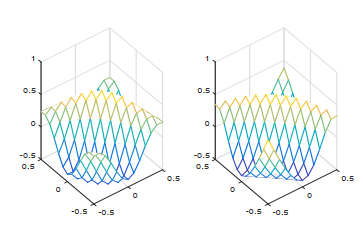
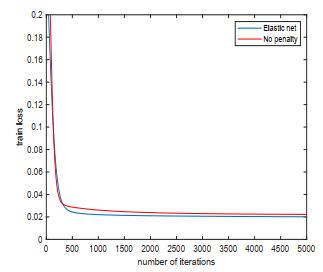
As one type of the important higher-order neural networks developed in the last decade, the Sigma-Pi-Sigma neural network has more powerful nonlinear mapping capabilities compared with other popular neural networks. This paper is concerned with a new Sigma-Pi-Sigma neural network based on a $ L_1 $ and $ L_2 $ regularization batch gradient method, and the numerical experiments for classification and regression problems prove that the proposed algorithm is effective and has better properties comparing with other classical penalization methods. The proposed model combines the sparse solution tendency of $ L_1 $ norm and the high benefits in efficiency of the $ L_2 $ norm, which can regulate the complexity of a network and prevent overfitting. Also, the numerical oscillation, induced by the non-differentiability of $ L_1 $ plus $ L_2 $ regularization at the origin, can be eliminated by a smoothing technique to approximate the objective function.
Citation: Jianwei Jiao, Keqin Su. A new Sigma-Pi-Sigma neural network based on $ L_1 $ and $ L_2 $ regularization and applications[J]. AIMS Mathematics, 2024, 9(3): 5995-6012. doi: 10.3934/math.2024293
As one type of the important higher-order neural networks developed in the last decade, the Sigma-Pi-Sigma neural network has more powerful nonlinear mapping capabilities compared with other popular neural networks. This paper is concerned with a new Sigma-Pi-Sigma neural network based on a $ L_1 $ and $ L_2 $ regularization batch gradient method, and the numerical experiments for classification and regression problems prove that the proposed algorithm is effective and has better properties comparing with other classical penalization methods. The proposed model combines the sparse solution tendency of $ L_1 $ norm and the high benefits in efficiency of the $ L_2 $ norm, which can regulate the complexity of a network and prevent overfitting. Also, the numerical oscillation, induced by the non-differentiability of $ L_1 $ plus $ L_2 $ regularization at the origin, can be eliminated by a smoothing technique to approximate the objective function.

| [1] |
C. K. Li, A sigma-pi-sigma neural network(SPSNN), Neural Processing Letters, 17 (2003), 1–19. https://doi.org/10.1023/A:1022967523886 doi: 10.1023/A:1022967523886

|
| [2] | Q. W. Fan, F. J. Zheng, X. D. Huang, D. P. Xu, Convergence Analysis for Sparse Pi-Sigma Neural Network Model with Entropy Error Function, International Journal of Machine Learning and Cybernetics, (2023), 1–12. https://doi.org/10.1007/s13042-023-01901-x |
| [3] |
Q. W. Fan, L. Liu, Q. Kang, L. Zhou, Convergence of Batch Gradient Method for Training of Pi-Sigma Neural Network with Regularizer and Adaptive Momentum Term, Neural Process. Lett., 4 (2023), 55. https://doi.org/10.1007/s11063-022-11069-0 doi: 10.1007/s11063-022-11069-0
|
| [4] |
J. C. Valle-Lisboa, F. Reali, H. Anastasia, E. Mizraji, Elman topology with sigma-pi units: An application to the modeling of verbal hallucinations in schizophrenia, Neural Netw., 18 (2005), 863–877. https://doi.org/10.1016/j.neunet.2005.03.009 doi: 10.1016/j.neunet.2005.03.009
|
| [5] |
C. Weber, S. Wermter, A self-organizing map of sigma-pi units, Neurocomputing, 70 (2007), 2552–2560. https://doi.org/10.1016/j.neucom.2006.05.014 doi: 10.1016/j.neucom.2006.05.014
|
| [6] |
Z. M. Chen, K. Niu, L. Li, Research on adaptive trajectory tracking algorithm for a quadrotor based on backstepping and the Sigma-Pi neural network, Int. J. Aerosp. Eng., 2019 (2019), 1–9. https://doi.org/10.1155/2019/1510341 doi: 10.1155/2019/1510341
|
| [7] |
M. Fallahnezhad, M. H. Moradi, S. Zaferanlouei, A hybrid higher order neural classier for handling classfication problems, Expert Syst. Appl., 38 (2011), 386–393. https://doi.org/10.1016/j.eswa.2010.06.077 doi: 10.1016/j.eswa.2010.06.077
|
| [8] | Y. B. Wang, T. X. Li, J. Y. Li, W. C. Li, Analysis on the performances of sparselized sigma-pi networks, in: Proceedings of the World Multi-conference on Systemics, Cybernetics and Informatics, Florida, USA, 5 (2004), 394–398. |
| [9] |
B. Dario, M. D. Fernando, A survey of artificial neural network training tools, Neural Comput. Appl., 23 (2013), 609–615. https://doi.org/10.1007/978-3-540-77465-5-13 doi: 10.1007/978-3-540-77465-5-13
|
| [10] |
L. Xu, J. S. Chen, D. F. Huang, Analysis of boundedness and convergence of online gradient method for two-Layer feedforward neural networks, IEEE Trans. Neural Netw. Learn. Syst., 24 (2013), 1327–1338. https://doi.org/10.1109/TNNLS.2013.2257845 doi: 10.1109/TNNLS.2013.2257845
|
| [11] | Q. W. Fan, Z. W. Zhang, X. D. Huang, Parameter conjugate gradient with secant equation based Elman neural network and its convergence analysis, Adv. Theor. Simul., 2022, 1–12. https://doi.org/10.1002/adts.202200047 |
| [12] |
J. Larsen, C. Svarer, L. N. Andersen, Adaptive regularization in neural network modeling, LNCS, 7700 (2012), 111–130. https://doi.org/10.1007/3-540-49430-8-6 doi: 10.1007/3-540-49430-8-6
|
| [13] |
H. T. Huynh, Y. Won, Regularized online sequential learning algorithm for single-hidden layer feedforward neural networks, Pattern Recognit. Lett., 32 (2011), 1930–1935. https://doi.org/10.1016/j.neucom.2016.04.043 doi: 10.1016/j.neucom.2016.04.043
|
| [14] | S. E. Fahlman, C. Lebiere, The cascade-correlation learning architecture, 1990. |
| [15] |
E. D. Karnin, A simple procedure for pruning back-propagation trained neural networks, IEEE Trans. Neural Netw., 1 (1990), 239–242. https://doi.org/10.1109/72.80236 doi: 10.1109/72.80236
|
| [16] |
R. Reed, Pruning algorithms-a survey, IEEE Trans. Neural Netw., 4 (1993), 740–747. https://doi.org/10.1109/72.248452 doi: 10.1109/72.248452
|
| [17] |
H. G. Han, J. F. Qiao, A structure optimisation algorithm for feedforward neural network construction, Neurocomputing, 99 (2013), 347–357. https://doi.org/10.1016/j.neucom.2012.07.023 doi: 10.1016/j.neucom.2012.07.023
|
| [18] |
A. B. Nielsen, L. K. Hansen, Structure learning by pruning in independent component analysis, Neurocomputing, 71 (2008), 2281–2290. https://doi.org/10.1016/j.neuron.2014.05.035 doi: 10.1016/j.neuron.2014.05.035
|
| [19] |
J. F. Qiao, Y. Zhang, H. G. Han, Fast unit pruning algorithm for feed-forward neural network design, Appl. Math. Comput., 205 (2008), 662–667. https://doi.org/10.1016/j.amc.2008.05.049 doi: 10.1016/j.amc.2008.05.049
|
| [20] |
J. L. Li, F. Jiao, J. C. Fang, J. C. Cheng, Temperature error modeling of RLG based on neural network optimized by PSO and regularization, IEEE Sens. J., 14 (2014), 912–919. https://doi.org/10.1109/JSEN.2013.2290699 doi: 10.1109/JSEN.2013.2290699
|
| [21] |
J. P. Donate, X. D. Li, G. G. Sa'nchez, A. S. Miguel, Time series forecasting by evolving artificial neural networks with genetic algorithms, differential evolution and estimation of distribution algorithm, Neural Comput. Appl., 22 (2013), 11–20. https://doi.org/10.1007/s00521-011-0741-0 doi: 10.1007/s00521-011-0741-0
|
| [22] |
O. Ludwig, Eigenvalue decay: A new method for neural network regularization, Neurocomputing, 124 (2014), 33–42. https://doi.org/10.1016/j.neucom.2013.08.005 doi: 10.1016/j.neucom.2013.08.005
|
| [23] |
S. U. Ahmed, M. Shah, K. Murase, A lempel-ziv complexity-based neural network pruning algorithm, Int. J. Neural Syst., 21 (2011), 427–441. https://doi.org/10.1142/S0129065711002936 doi: 10.1142/S0129065711002936
|
| [24] |
T. T. Pan, J. H. Zhao, W. Wu, J. Yang, Learning imbalanced datasets based on SMOTE and Gaussian distribution, Inf. Sci., 512 (2020), 1214–1233. https://doi.org/10.1016/j.ins.2019.10.048 doi: 10.1016/j.ins.2019.10.048
|
| [25] | I. Goodfellow, Y. Bengio, A. Courville, Deep Learning, Cambridge, MA, USA: MIT Press, 2016. |
| [26] |
G. E. Hinton, Deterministic Boltzmann learning performs steepest descent in weight-space, Neural Comput., 1 (1989), 143–150. https://doi.org/10.7551/mitpress/3349.003.0007 doi: 10.7551/mitpress/3349.003.0007
|
| [27] |
J. Sum, C. S. Leung, K. Ho, Convergence analyses on on-line weight noise injection-based training algorithms for MLPs, IEEE Trans. Neural Netw. Learn. Syst., 23 (2012), 1827–1840. https://doi.org/10.1109/TNNLS.2012.2210243 doi: 10.1109/TNNLS.2012.2210243
|
| [28] |
P. May, E. Zhou, A comprehensive evaluation of weight growth and weight elimination methods using the tangent plane algorithm, Int. J. Adv. Comput. Sci. Appl., 4 (2013), 149–156. https://doi.org/10.14569/IJACSA.2013.040621 doi: 10.14569/IJACSA.2013.040621
|
| [29] | J. E. Moody, T. S. Rognvaldsson, Smoothing regularizers for projective basis function networks, Proc. Adv. Neural Inf. Process. Syst., 9 (1997), 585–591. |
| [30] | Z. Chen, S. Haykin, On different facets of regularization theory, Neural Comput., 14(12), 2791–2846. https://doi.org/10.1162/089976602760805296 |
| [31] | Q. W. Fan, Q. Kang, J. M. Zurada, T. W. Huang, D. P. Xu. Convergence analysis of online gradient method for High-Order neural networks and their sparse optimization, IEEE T. Neur. Net. Lear., 2023. https://doi.org/10.1109/TNNLS.2023.3319989 |
| [32] |
L. Zhou, Q. W. Fan, X. D. Huang, Y. Liu, Weak and strong convergence analysis of elman neural networks via weight decay regularization, Optimization, 72 (2023), 2287–2309. https://doi.org/10.1080/02331934.2022.2057852 doi: 10.1080/02331934.2022.2057852
|
| [33] |
M. G. Augasta, T. Kathirvalavakumar, Pruning algorithms of neural networks-a comparative study, Central Eur. J. Comput. Sci., 3(2013), 105–115. https://doi.org/10.2478/s13537-013-0109-x doi: 10.2478/s13537-013-0109-x
|
| [34] |
W. Wu, H. M. Shao, Z. X. Li, Convergence of batch BP algorithm with penalty for FNN training, Neural Inf. Process., 4232 (2006), 562–569. https://doi.org/10.1007/11893028-63 doi: 10.1007/11893028-63
|
| [35] |
J. Wang, W. Wu, J. M. Zurada, Computational properties and convergence analysis of BPNN for cyclic and almost cyclic learning with penalty, Neural Netw., 33 (2012), 127–135. https://doi.org/10.1016/j.neunet.2012.04.013 doi: 10.1016/j.neunet.2012.04.013
|
| [36] | K. Saito, S. Nakano, Second-order learning algorithm with squared penalty term, Neural Comput., 12 (2000), 709–729. |
| [37] |
H. Zhang, W. Wu, M. Yao, Boundedness and convergence of batch backpropagation algorithm with penalty for feedforward neural networks, Neurocomputing, 89 (2012), 141–146. https://doi.org/10.1016/j.neucom.2012.02.029 doi: 10.1016/j.neucom.2012.02.029
|
| [38] | X. Y. Chang, Z. B. Xu, H. Zhang, J. J. Wang, Y. Liang, Robust regularization theory based on $L_{q}$ $(0<q<1)$ regularization: the asymptotic distribution and variable selection consistence of solutions, Sci. China, 40 (2010), 985–998. |
| [39] |
B. K. Natarajan, Sparse approximate solutions to linear systems, SIAM J. Comput., 24 (1995), 227–234. https://doi.org/10.1137/S0097539792240406 doi: 10.1137/S0097539792240406
|
| [40] |
R. Tibshirani, Regression shrinkage and selection via the Lasso, J. R. Stat. Soc. Ser. B., 58 (1996), 267–288. https://doi.org/10.1111/j.2517-6161.1996.tb02080.x doi: 10.1111/j.2517-6161.1996.tb02080.x
|
| [41] |
H. Bilal, A. Kumar, B. Yin, Pruning filters with $L_1$-norm and capped $L_1$-norm for CNN compression, Appl. Intell., 51 (2021), 1152–1160. https://doi.org/10.1007/s10489-020-01894-y doi: 10.1007/s10489-020-01894-y
|
| [42] |
H. J. Rong, Y. S. Ong, A. H. Tan, Z. Zhu, A fast pruned-extreme learning machine for classification problem, Neurocomputing, 72 (2008), 359–366. https://doi.org/10.1016/j.neucom.2008.01.005 doi: 10.1016/j.neucom.2008.01.005
|
| [43] |
J. M. Martinez-Martinez, P. Escandell-Montero, E. Soria-Olivas, J. D. Martin-Guerrero, R. Magdalena-Benedito, J. Gmez-Sanchis, Regularized extreme learning machine for regression problems, Neurocomputing, 74 (2011), 3716–3721. https://doi.org/10.1016/j.neucom.2011.06.013 doi: 10.1016/j.neucom.2011.06.013
|
| [44] |
C. De Mol, E. De Vito, L. Rosasco, Elastic-net regularization in learning theory, J. Complex., 25 (2009), 201–230. https://doi.org/10.1016/j.jco.2009.01.002 doi: 10.1016/j.jco.2009.01.002
|
| [45] |
Q. Kang, Q. W. Fan, J. M. Zurada, Deterministic convergence analysis via smoothing group Lasso regularization and adaptive momentum for sigma-pi-sigma neural network, Inform. Sciences, 553 (2021), 66–82. https://doi.org/10.1016/j.ins.2020.12.014 doi: 10.1016/j.ins.2020.12.014
|
| [46] |
Q. Kang, Q. W. Fan, J. M. Zurada, T. W. Huang, A pruning algorithm with relaxed conditions for high-order neural networks based on smoothing group $L_{1/2}$ regularization and adaptive momentum, Knowledge-Based Syst., 257 (2022), 109858. https://doi.org/10.1016/j.knosys.2022.109858 doi: 10.1016/j.knosys.2022.109858
|
Figures(6) / Tables(5)

Jianwei Jiao, Keqin Su. A new Sigma-Pi-Sigma neural network based on $ L_1 $ and $ L_2 $ regularization and applications[J]. AIMS Mathematics, 2024, 9(3): 5995-6012. doi: 10.3934/math.2024293







 DownLoad:
DownLoad: