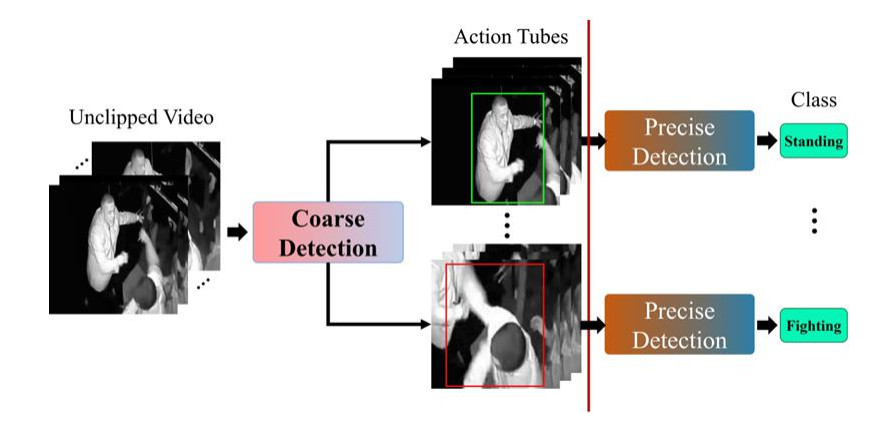
With the proliferation of urban video surveillance systems, the abundance of surveillance video data has emerged as a pivotal asset for enhancing public safety. Within these video archives, the identification of abnormal human actions carries profound implications for security incidents. Nevertheless, existing surveillance systems primarily rely on conventional algorithms, leading to both missed incidents and false alarms. To address the challenge of automating multi-object surveillance video analysis, this study introduces a comprehensive method for the detection and recognition of multi-object abnormal actions. This study comprises a two-stage framework: the coarse detection stage employs an enhanced YOWOv2E model for spatio-temporal action detection, while the precise detection stage utilizes a two-stream network for precise action classification. In parallel, this paper presents the PSA-Dataset to address the current limitations in the field of abnormal action detection. Experimental results, collected from both public datasets and a self-built dataset, illustrate the effectiveness of the proposed method in identifying a wide spectrum of abnormal actions. This work offers valuable insights for automating the analysis of human actions in videos pertaining to public security.
Citation: Yongsheng Lei, Meng Ding, Tianliang Lu, Juhao Li, Dongyue Zhao, Fushi Chen. A novel approach for enhanced abnormal action recognition via coarse and precise detection stage[J]. Electronic Research Archive, 2024, 32(2): 874-896. doi: 10.3934/era.2024042
With the proliferation of urban video surveillance systems, the abundance of surveillance video data has emerged as a pivotal asset for enhancing public safety. Within these video archives, the identification of abnormal human actions carries profound implications for security incidents. Nevertheless, existing surveillance systems primarily rely on conventional algorithms, leading to both missed incidents and false alarms. To address the challenge of automating multi-object surveillance video analysis, this study introduces a comprehensive method for the detection and recognition of multi-object abnormal actions. This study comprises a two-stage framework: the coarse detection stage employs an enhanced YOWOv2E model for spatio-temporal action detection, while the precise detection stage utilizes a two-stream network for precise action classification. In parallel, this paper presents the PSA-Dataset to address the current limitations in the field of abnormal action detection. Experimental results, collected from both public datasets and a self-built dataset, illustrate the effectiveness of the proposed method in identifying a wide spectrum of abnormal actions. This work offers valuable insights for automating the analysis of human actions in videos pertaining to public security.

| [1] |
K. Q. Huang, X. T. Chen, Y. F. Kang, T. N. Tan, Intelligent visual surveillance, Chin. J. Comput., 38 (2015), 1093–1118. http://dx.doi.org/10.11897/SP.J.1016.2015.01093 doi: 10.11897/SP.J.1016.2015.01093

|
| [2] |
E. Selvi, M. Adimoolam, G. Karthi, K. Thinakaran, N. M. Balamurugan, R. Kannadasan, et al., Suspicious actions detection system using enhanced CNN and surveillance video, Electronics, 11 (2022), 4210. https://doi.org/10.3390/electronics11244210 doi: 10.3390/electronics11244210
|
| [3] | M. Jain, J. V. Gemert, H. Jégou, P. Bouthemy, C. G. M. Snoek, Action localization with tubelets from motion, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2014), 740–747. http://doi.ieeecomputersociety.org/10.1109/CVPR.2014.100 |
| [4] | K. Soomro, H. Idrees, M. Shah, Action localization in videos through context walk, in Proceedings of the IEEE International Conference on Computer Vision (ICCV), (2015), 3280–3288. https://doi.ieeecomputersociety.org/10.1109/ICCV.2015.375 |
| [5] | G. Gkioxari, J. Malik, Finding action tubes, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2015), 759–768. https://doi.ieeecomputersociety.org/10.1109/CVPR.2015.7298676 |
| [6] | G. Singh, S. Saha, M. Sapienza, P. Torr, F. Cuzzolin, Online real-time multiple spatiotemporal action localisation and prediction, in Proceedings of the IEEE International Conference on Computer Vision (ICCV), (2017), 3637–3646. https://doi.ieeecomputersociety.org/10.1109/ICCV.2017.393 |
| [7] | R. Hou, C. Chen, M. Shah, Tube convolutional neural network (T-CNN) for action detection in videos, in Proceedings of the IEEE International Conference on Computer Vision (ICCV), (2017), 5822–5831. https://doi.ieeecomputersociety.org/10.1109/ICCV.2017.620 |
| [8] | C. H. Gu, C. Sun, D. A. Ross, C. Vondrick, C. Pantofaru, Y. Q. Li, et al., AVA: A video dataset of spatio-temporally localized atomic visual actions, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2018), 6047–6056. https://doi.ieeecomputersociety.org/10.1109/CVPR.2018.00633 |
| [9] | O. Köpüklü, X. Y. Wei, G. Rigoll, You only watch once: A unified cnn architecture for real-time spatiotemporal action localization, preprint, arXiv: 1911.06644. https://doi.org/10.48550/arXiv.1911.06644 |
| [10] | J. H. Yang, K. Dai, YOWOv2: A stronger yet efficient multi-level detection framework for real-time spatio-temporal action detection, preprint, arXiv: 2302.06848. https://doi.org/10.48550/arXiv.2302.06848 |
| [11] | A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, F. F. Li, Large-scale video classification with convolutional neural networks, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2014), 1725–1732. https://doi.ieeecomputersociety.org/10.1109/CVPR.2014.223 |
| [12] |
K. Simonyan, A. Zisserman, Two-stream convolutional networks for action recognition in videos, Adv. Neural Inf. Process. Syst., 27 (2014). https://doi.org/10.48550/arXiv.1406.2199 doi: 10.48550/arXiv.1406.2199
|
| [13] |
L. M. Wang, Y. J. Xiong, Z. Wang, Y. Qiao, D. H. Lin, X. O. Tang, et al., Temporal segment networks for action recognition in videos, IEEE Trans. Pattern Anal. Mach. Intell., (2016), 20–36. https://doi.org/10.1007/978-3-319-46484-8_2 doi: 10.1007/978-3-319-46484-8_2
|
| [14] | A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lučić, C. Schmid, Vivit: A video vision transformer, in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), (2021), 6836–6846. https://doi.org/10.1109/ICCV48922.2021.00676 |
| [15] | H. Q. Fan, B. Xiong, K. Mangalam, Y. H. Li, Z. C. Yan, J. Malik, et al., Multiscale vision transformers, in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), (2021), 6824–6835. https://doi.org/10.1109/ICCV48922.2021.00675 |
| [16] | G. Bertasius, H. Wang, H. Torresani, Is space-time attention all you need for video understanding?, in Proceedings of the 38th International Conference on Machine Learning, (2021), 813–824. https://arXiv.org/abs/2102.05095 |
| [17] | S. Yan, X. H. Xiong, A. Arnab, Z. C. Lu, M. Zhang, C. Sun, et al., Multiview transformers for video recognition, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2022), 3333–3343. https://doi.org/10.1109/CVPR52688.2022.00333 |
| [18] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, et al., Attention is all you need, in Proceedings of the 31st International Conference on Neural Information Processing Systems, 30 (2017), 6000–6010. https://dl.acm.org/doi/10.5555/3295222.3295349 |
| [19] | L. Yang, R. Y Zhang, L. Li, X. Xie, Simam: A simple, parameter-free attention module for convolutional neural networks, in International Conference on Machine Learning, PMLR, (2021), 11863–11874. https://proceedings.mlr.press/v139/yang21o |
| [20] | C. Y. Wang, A. Bochkovskiy, H. Y. M. Liao, YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2023), 7464–7475. https://doi.org/10.1109/CVPR52729.2023.00721 |
| [21] | N. N. Ma, X. Y. Zhang, H. T. Zheng, J. Sun, Shufflenet v2: Practical guidelines for efficient cnn architecture design, in Proceedings of the European Conference on Computer Vision (ECCV), (2018), 116–131. https://doi.org/10.1007/978-3-030-01264-9_8 |
| [22] | Q. L. Wang, B. G. Wu, P. F. Zhu, P. H. Li, W. M. Zuo, Q. H. Hu, ECA-Net: Efficient channel attention for deep convolutional neural networks, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2020), 11531–11539. https://doi.org/10.1109/CVPR42600.2020.01155 |
| [23] | T. Y. Lin, P. Goyal, R. Girshick, K. M. He, P. Dollár, Focal loss for dense object detection, in IEEE International Conference on Computer Vision (ICCV), (2020), 2999–3007. https://doi.org/10.1109/ICCV.2017.324 |
| [24] |
R. Müller, S. Kornblith, G. Hinton, When does label smoothing help?, Adv. Neural Inf. Process. Syst., 32 (2019), 4694–4703 https://dl.acm.org/doi/10.5555/3454287.3454709 doi: 10.5555/3454287.3454709
|
| [25] | R. Hou, C. Chen, M. Shah, Tube convolutional neural network (T-CNN) for action detection in videos, in Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), (2017), 5822–5831. https://doi.org/10.1109/ICCV.2017.620 |
| [26] | V. Kalogeiton, P. Weinzaepfel, V. Ferrari, C. Schmid, Action tubelet detector for spatio-temporal action localization, in Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), (2017), 4405–4413. https://doi.org/10.1109/ICCV.2017.472 |
| [27] | X. T. Yang, X. D. Yang, M. Y. Liu, F. Y. Xiao, L. S. Davis, J. Kautz, STEP: Spatio-temporal progressive learning for video action detection, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2019), 264–272. https://doi.org/10.1109/CVPR.2019.00035 |
| [28] | Y. X. Li, Z. X. Wang, L. M. Wang, G. S. Wu, Actions as moving points, in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, (2020), 68–84. https://doi.org/10.1007/978-3-030-58517-4_5 |
| [29] | J. Hu, L. Shen, G. Sun, Squeeze-and-excitation networks, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2018), 7132–7141. https://doi.org/10.1109/CVPR.2018.00745 |
| [30] | A. Brock, S. De, S. L. Smith, K. Simonyan, High-performance large-scale image recognition without normalization, in International Conference on Machine Learning, PMLR, 139 (2021), 1059–1071. https://doi.org/10.48550/arXiv.2102.06171 |
| [31] |
F. Anvarov, D. H. Kim, B. C. Song, Action Recognition Using Deep 3D CNNs with sequential feature aggregation and attention, Electronics, 9 (2020), 147. https://doi.org/10.3390/electronics9010147 doi: 10.3390/electronics9010147
|
| [32] |
S. P. Sahoo, S. Ari, K. Mahapatra, S. P. Mohanty, HAR-depth: a novel framework for human action recognition using sequential learning and depth estimated history images, IEEE Trans. Emerging Top. Comput. Intell., 5 (2020), 813–825. https://doi.org/10.1109/tetci.2020.3014367 doi: 10.1109/tetci.2020.3014367
|
| [33] |
S. Kumawat, M. Verma, Y. Nakashima, S. Raman, Depthwise spatio-temporal STFT convolutional neural networks for human action recognition, IEEE Trans. Pattern Anal. Mach. Intell., 44 (2021), 4839–4851. https://doi.org/10.1109/TPAMI.2021.3076522 doi: 10.1109/TPAMI.2021.3076522
|
| [34] |
B. Wang, X. H. Wang, S. W. Ren, W. J. Wang, Y. T. Shi, Hierarchical motion excitation network for few-shot video recognition, Electronics, 12 (2023), 1090. https://doi.org/10.3390/electronics12051090 doi: 10.3390/electronics12051090
|
| [35] |
J. X. Zhang, H. F. Hu, Z. Liu, Appearance-and-dynamic learning with bifurcated convolution neural network for action recognition, IEEE Trans. Circuits Syst. Video Technol., 31 (2020), 1593–1606. https://doi.org/10.1109/TCSVT.2020.3006223 doi: 10.1109/TCSVT.2020.3006223
|
 era-32-02-042-Supplementary.pdf era-32-02-042-Supplementary.pdf |
 |









Figures(10) / Tables(8)
Yongsheng Lei, Meng Ding, Tianliang Lu, Juhao Li, Dongyue Zhao, Fushi Chen. A novel approach for enhanced abnormal action recognition via coarse and precise detection stage[J]. Electronic Research Archive, 2024, 32(2): 874-896. doi: 10.3934/era.2024042







 DownLoad:
DownLoad: