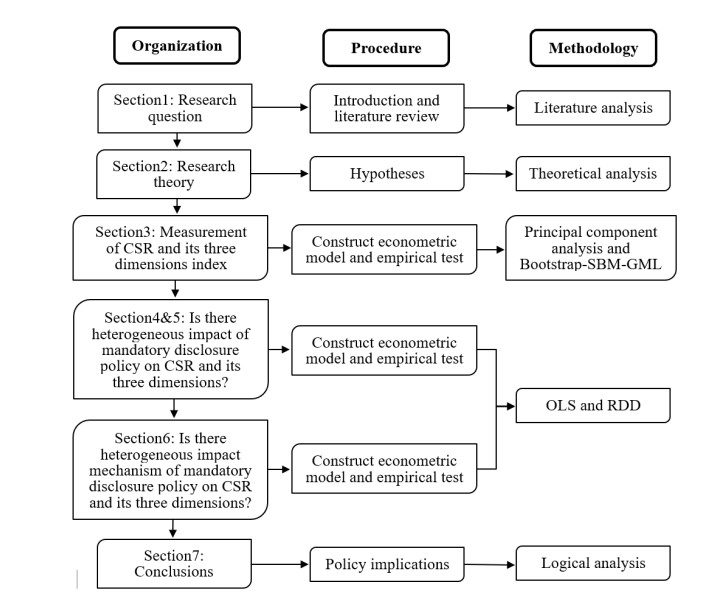
The corporate social responsibility (CSR) report is an important carrier of non-financial information disclosure of enterprises and an important bridge of communication between enterprises and interested parties. Compulsory disclosure has promoted the improvement of CSR levels to some extent. While, for interested parties, their attention to various dimensions of CSR has significant differences, which leads to the heterogeneous impact of mandatory disclosure policy on its different dimensions. Through regression discontinuity design model (RDD), as well as using quasi-natural experiments of Chinese mandatory disclosure policies issued in 2008, we are going to get the following conclusions by analyzing the heterogeneous impact of mandatory disclosure on CSR with the environment (CER), social (SOC) and economic (ECO) three-dimension on the basis of verifying that mandatory disclosure policy has a positive impact on CSR. (1) The effects of mandatory disclosure on the three dimensions of CSR are heterogeneous, that is, the significant effects and directions are significantly different in the three dimensions. (2) The heterogeneity of mandatory disclosure on CSR is reflected in the changing trend, and there is no significant difference at the turning point of the trend. (3) The heterogeneity of the impact mechanism of mandatory disclosure on CSR is reflected in the different mediating variables of policy on different dimensions impact, that is, the mediating variables of CER and ECO are the environmental disclosure information and return on assets. (4) The impact of mandatory disclosure on different dimensions of CSR is heterogeneous when the nature of industries and property rights are different.
Citation: Shuanglian Chen, Cunyi Yang, Khaldoon Albitar. Is there any heterogeneous impact of mandatory disclosure on corporate social responsibility dimensions? Evidence from a quasi-natural experiment in China[J]. Data Science in Finance and Economics, 2021, 1(3): 272-297. doi: 10.3934/DSFE.2021015
The corporate social responsibility (CSR) report is an important carrier of non-financial information disclosure of enterprises and an important bridge of communication between enterprises and interested parties. Compulsory disclosure has promoted the improvement of CSR levels to some extent. While, for interested parties, their attention to various dimensions of CSR has significant differences, which leads to the heterogeneous impact of mandatory disclosure policy on its different dimensions. Through regression discontinuity design model (RDD), as well as using quasi-natural experiments of Chinese mandatory disclosure policies issued in 2008, we are going to get the following conclusions by analyzing the heterogeneous impact of mandatory disclosure on CSR with the environment (CER), social (SOC) and economic (ECO) three-dimension on the basis of verifying that mandatory disclosure policy has a positive impact on CSR. (1) The effects of mandatory disclosure on the three dimensions of CSR are heterogeneous, that is, the significant effects and directions are significantly different in the three dimensions. (2) The heterogeneity of mandatory disclosure on CSR is reflected in the changing trend, and there is no significant difference at the turning point of the trend. (3) The heterogeneity of the impact mechanism of mandatory disclosure on CSR is reflected in the different mediating variables of policy on different dimensions impact, that is, the mediating variables of CER and ECO are the environmental disclosure information and return on assets. (4) The impact of mandatory disclosure on different dimensions of CSR is heterogeneous when the nature of industries and property rights are different.

| [1] |
Charnes A, Cooper WW, Rhodes E (1978) Measuring the efficiency of decision making units. Eur J Oper Res 2: 429-444. doi: 10.1016/0377-2217(78)90138-8

|
| [2] | Albertini E (2014) A Descriptive Analysis of Environmental Disclosure: A Longitudinal Study of French Companies. J Bus Ethics 121. |
| [3] | Angrist JD, Pischke JS (2008) Mostly Harmless Econometrics: An Empiricist's Companion, Princeton University Press. |
| [4] | Arena C, Liong R, Vourvachis P (2018) Carrot or stick: CSR disclosures by Southeast Asian companies. Sustainability Account Manage Policy J 9. |
| [5] |
Atkinson L, Galaskiewicz J (1988) Stock ownership and company contributions to charity. Admin Sci Q, 82-100. doi: 10.2307/2392856
|
| [6] |
Christainsen GB, Haveman RH (1981) The contribution of environmental regulations to the slowdown in productivity growth. J Environ Econ Manage 8: 381-390. doi: 10.1016/0095-0696(81)90048-6
|
| [7] | Calonico S, Cattaneo MD, Titiunik R (2015) Optimal Data-Driven Regression Discontinuity Plots. J Am Stat Assoc 110. |
| [8] | Carroll AB (1979) A Three-Dimensional Conceptual Model of Corporate Performance. Acad Manage Rev 4. |
| [9] |
Chang CY, Shie FS, Yang SL (2019) The relationship between herding behavior and firm size before and after the elimination of short-sale price restrictions. Quant Financ Econ 3: 526-549. doi: 10.3934/QFE.2019.3.526
|
| [10] | Chen YC, Hung M, Wang Y (2018) The effect of mandatory CSR disclosure on firm profitability and social externalities: Evidence from China. J Account Econ 65. |
| [11] |
Clarkson MBE (1995) A Stakeholder Framework for Analyzing and Evaluating Corporate Social Performance. Acad Manage Rev 20: 92-117. doi: 10.2307/258888
|
| [12] |
Demirtas YE, Kececi NF (2020) The efficiency of private pension companies using dynamic data envelopment analysis. Quant Financ Econ 4: 204-219. doi: 10.3934/QFE.2020009
|
| [13] |
Dhaliwal D, Li OZ, Tsang A, et al. (2014) Corporate social responsibility disclosure and the cost of equity capital: The roles of stakeholder orientation and financial. transparency. J Account Public Policy 33: 328-355. doi: 10.1016/j.jaccpubpol.2014.04.006
|
| [14] |
Dhaliwal DS, Li OZ, Tsang A, et al. (2011) Voluntary Nonfinancial Disclosure and the Cost of Equity Capital: The Initiation of Corporate Social Responsibility Reporting. Account Rev 86: 59-100. doi: 10.2308/accr.00000005
|
| [15] | Fama EF, Laffer AB (1972) The Number of Firms and Competition. Am Econ Rev 62. |
| [16] | Federica B, Arianna L, Riccardo T (2020) Credibility of Environmental Issues in Non-Financial Mandatory Disclosure: Measurement and Determinants. J Clean Prod 288. |
| [17] | Feng Y, Chen S, Failler P (2020) Productivity Effect Evaluation on Market-Type Environmental Regulation: A Case Study of SO2 Emission Trading Pilot in China. Int J Environ Res Public Health 17. |
| [18] | Fogler HR, Nutt F (1975) A Note on Social Responsibility and Stock Valuation. Acad Manage J 18. |
| [19] | Galaskiewicz J (1997) An urban grants economy revisited: Corporate charitable contributions in the Twin Cities, 1979-81, 1987-89. Admin Sci Q, 445-471. |
| [20] |
Gallego-Álvarez I, Lozano MB, Rodríguez-Rosa M (2018) An analysis of the environmental information in international companies according to the new GRI standards. J Clean Prod 182: 57-66. doi: 10.1016/j.jclepro.2018.01.240
|
| [21] | Gelman A, Imbens G (2019) Why High-Order Polynomials Should Not Be Used in Regression Discontinuity Designs. J Bus Econ Stat 37. |
| [22] |
El Ghoul S, Guedhami O, Kwok CC, et al. (2011) Does corporate social responsibility affect the cost of capital? J Bank Financ 35: 2388-2406. doi: 10.1016/j.jbankfin.2011.02.007
|
| [23] | Hardy DR, Schwartz MF (1996) Customized information extraction as a basis for resource discovery. ACM Trans Comput Syst (TOCS) 14. |
| [24] | Hemingway CA, Maclagan PW (2004) Managers' Personal Values as Drivers of Corporate Social Responsibility. J Bus Ethics 50. |
| [25] |
Hong M, Drakeford B, Zhang K (2020) The impact of mandatory CSR disclosure on green innovation: evidence from China. Green Financ 2: 302-322. doi: 10.3934/GF.2020017
|
| [26] | Hung M, Shi J, Wang Y (2013) Mandatory CSR disclosure and information asymmetry: Evidence from a quasi-natural experiment in china. Social Sci Electron Publishing 33: 1-17. |
| [27] | Imbens G, Kalyanaraman K (2012) Optimal Bandwidth Choice for the Regression Discontinuity Estimator. Rev Econ Stud 79. |
| [28] | Kim Y, Li H, Li S (2014) Corporate social responsibility and stock price crash risk. J Bank Financ 43. |
| [29] |
Kim Y, Park MS, Wier B (2012) Is Earnings Quality Associated with Corporate Social Responsibility? Account Rev 87: 761-796. doi: 10.2308/accr-10209
|
| [30] | Lee DS, Lemieux T (2010) Regression Discontinuity Designs in Economics. J Econ Lit 48. |
| [31] | Li F, Yang C, Li Z, et al. (2021) Does Geopolitics Have an Impact on Energy Trade? Empirical Research on Emerging Countries. Sustainability 13. |
| [32] |
Li Z, Liao G, Albitar K (2020) Does corporate environmental responsibility engagement affect firm value? The mediating role of corporate innovation. Bus Strat Environ 29: 1045-1055. doi: 10.1002/bse.2416
|
| [33] | Lin KJ, Tan J, Zhao L, et al. (2015) In the name of charity: Political connections and strategic corporate social responsibility in a transition economy. J Corp Financ 32. |
| [34] | Mobus JL (2005) Mandatory environmental disclosures in a legitimacy theory context. Account Audit Account J 18. |
| [35] | Oh DH (2010) A global Malmquist-Luenberger productivity index. J Prod Anal 34. |
| [36] | Petrovits CM (2005) Corporate-sponsored foundations and earnings management. J Account Econ 41. |
| [37] |
Prior D, Surroca J, Tribo JA (2008) Are socially responsible managers really ethical? Exploring the relationship between earnings management and corporate social responsibility. Corp Govern Inter Rev 16: 160-177. doi: 10.1111/j.1467-8683.2008.00678.x
|
| [38] | Cowen SS, Ferreri LB, Parker LD (1987) The impact of corporate characteristics on social responsibility disclosure: A typology and frequency-based analysis. Pergamon 12. |
| [39] | Sánchez CM (2000) Motives for Corporate Philanthropy in El Salvador: Altruism and Political Legitimacy. J Bus Ethics 27. |
| [40] |
Sedláček J, Popelková V (2020) Non-financial information and their reporting—evidence of small and medium-sized enterprises and large corporations on the Czech capital market. Natl Account Rev 2: 204-216. doi: 10.3934/NAR.2020012
|
| [41] | Simar L, Wilson PW (1998) Sensitivity Analysis of Efficiency Scores: How to Bootstrap in Nonparametric Frontier Models. Manage Sci 44. |
| [42] | Tone K (2001) A slacks-based measure of efficiency in data envelopment analysis. Eur J Oper Res 130. |
| [43] | Tone K (2002) A slacks-based measure of super-efficiency in data envelopment analysis. Eur J Oper Res 143. |
| [44] |
Tuzcuoglu T (2020) The impact of financial fragility on firm performance: an analysis of BIST companies. Quant Financ Econ 4: 310-342. doi: 10.3934/QFE.2020015
|
| [45] |
Utomo MN, Rahayu S, Kaujan K, et al. (2020) Environmental performance, environmental disclosure, and firm value: empirical study of non-financial companies at Indonesia Stock Exchange. Green Financ 2: 100-113. doi: 10.3934/GF.2020006
|
| [46] | Verrecchia RE (2001) Essays on disclosure. J Account Econ 32. |
| [47] | Waller DS, Lanis R (2009) Corporate Social Responsibility (CSR) Disclosure of Advertising Agencies: An Exploratory Analysis of Six Holding Companies' Annual Reports. J Adver 38. |
| [48] |
Xu M, Albitar K, Li Z (2020) Does corporate financialization affect EVA? Early evidence from China. Green Financ 2: 392-408. doi: 10.3934/GF.2020021
|
| [49] | Yang C, Li T, Albitar K (2021) Does energy efficiency affect ambient PM2.5? The moderating role of energy investment. |


Figures(3) / Tables(15)
Shuanglian Chen, Cunyi Yang, Khaldoon Albitar. Is there any heterogeneous impact of mandatory disclosure on corporate social responsibility dimensions? Evidence from a quasi-natural experiment in China[J]. Data Science in Finance and Economics, 2021, 1(3): 272-297. doi: 10.3934/DSFE.2021015







 DownLoad:
DownLoad: